I am setting up components that include pivot and unpivot nodes, and can’t seem to figure out how get the Pivot Nodes to accept an empty group selection… Does anyone know if there is a value that I can pass by flow variable into the Pivot Node that will be read as an empty included list? Or another trick to bypass a flow variable controlled group list via another boolean flow variable?
I have tried “”, missing values, switching the Column Selection Configuration Node over to an empty table…
The only possible workaround that I can come up with is to swap the logic and use the entered Column Selection Configuration node to build an “Exclude List”, and then add their selection to that list if a bypass boolean setting is selected. It might work, but I was wondering if there was a cleaner trick that someone found to pass empty flow variable column lists.
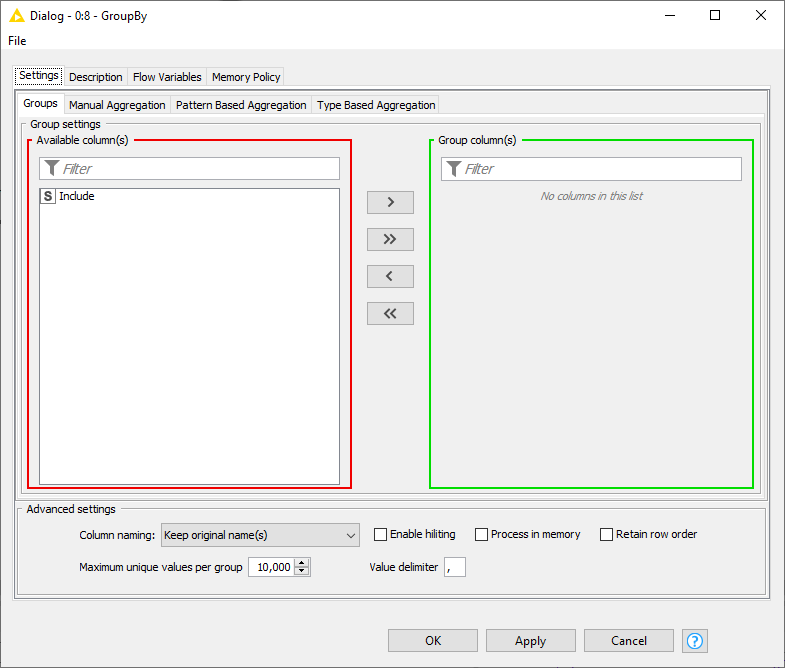
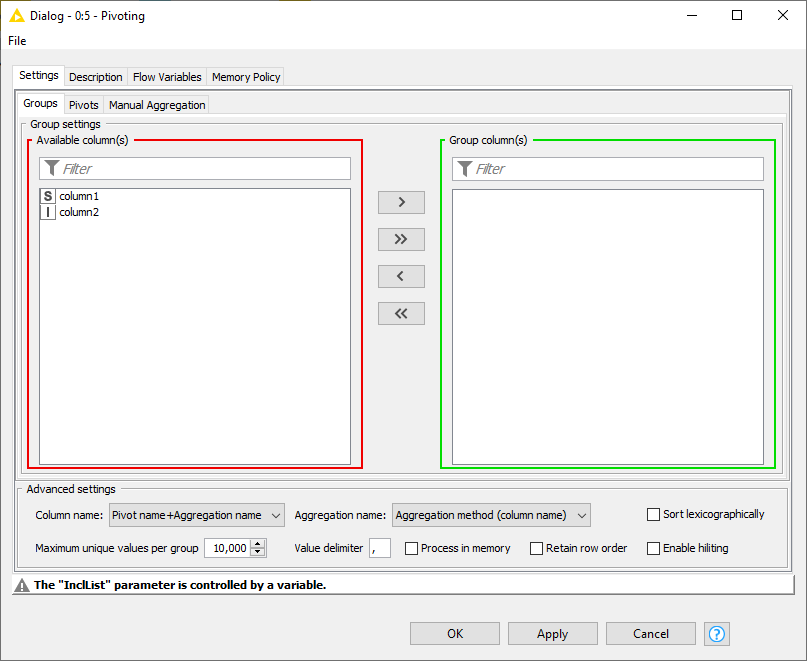
In my experience, there’s nothing special needed to leave the Pivoting node’s Group column(s) field empty. The node will give you a warning, but it will run.
Can you share some more specifics about what you’re trying to do?
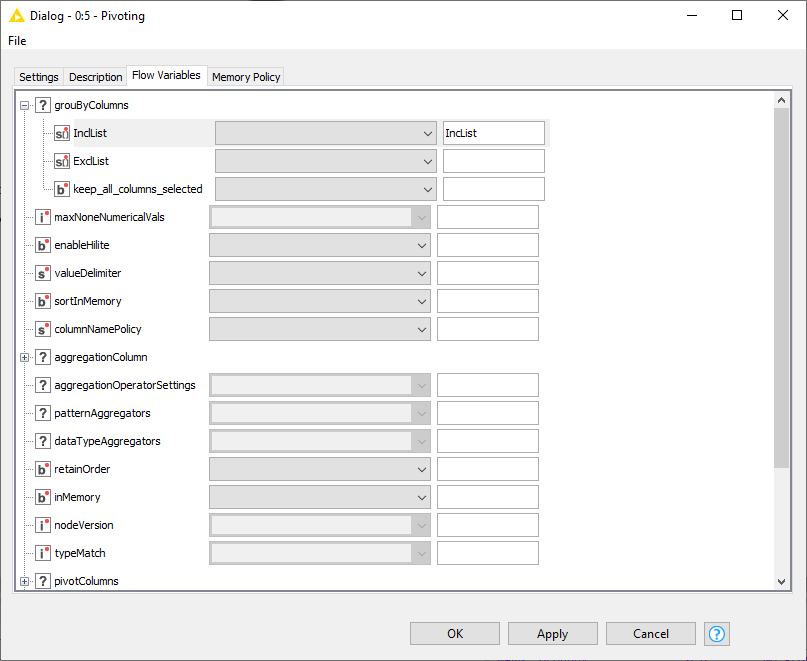
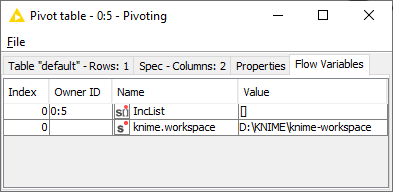
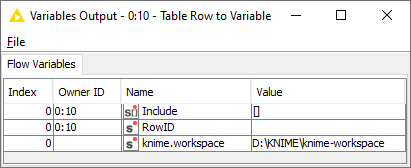
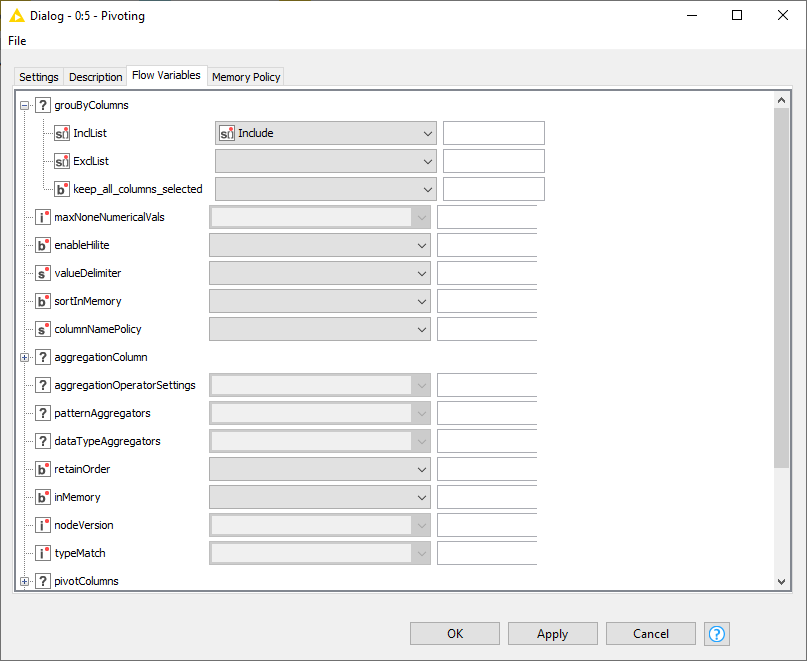
In any case, you can indeed supply the Pivoting node with a variable to control this. As shown by the icon next to IncList the variable needs to be in the form of a List. You can test this by configuring the node the way you want, then choosing to export the variable, and looking at the output:
I was able to pull off a dynamic pivot component that outputs the “raw values” into separate columns instead of performing an aggregation. (More of a personal learning challenge to make it a component than anything else…)
For those of you finding this post and attempting to configure a pivot node for universal use within a component there are plenty of challenges to work around. Here are a few that might be helpful.
The pivot node requires valid placeholder columns names / datatypes to be manually entered into group, pivot and aggregation even when those settings are being overridden via a flow variable. (Which of course makes no sense…) I got around this by mirroring the selected column data with dummy column names / data types and using those as placeholders to avoid errors and allow for more dynamic component use.
The aggregation column name and method needs to be controlled by flow variable in the 0 array. I was unable to feed in the data type by flow variable, so I had to convert all of the columns data types to string and then return it back again at output. Otherwise selecting columns of different datatypes then were in the dummy columns caused errors.
Individual string flow variables should be converted to “lists” via the group node for group and pivot name lists.
You need to build a Group bypass setting that will pass an empty list through to the group flow variable.