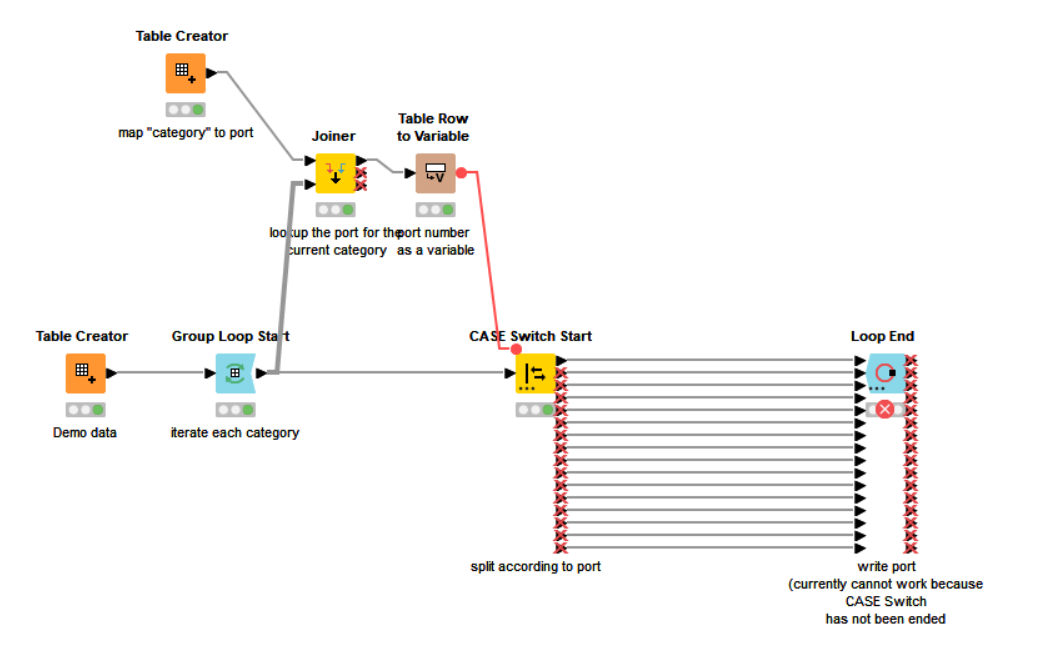
I am trying to apply multiple filters to a data set based on the values in a certain column (Asset Category). There are 16 individual values in the Asset Category column therefore I have to use 16 row filter nodes to get the 16 separate tables.
It would be good if KNIME could have some form of “grouped row splitter” where a column value would define the rows to be directed to each of a variable number of output ports.
I had been pondering on whether a group loop start and a case switch could assist, but to me it would only be beneficial if the outcome of the loop could be several output ports.
Unfortunately, the case switch requires that at the end, the branches are all collapsed into a single table again before the loop ends, or else you get an error such as this:
The only mechanism I currently see for producing split outputs coming out of the loop for further manual analysis is once again to involve row filters or row splitters, thereyby losing the benefit of looping, and just adding complication but it would be interesting to see if there are any avenues to explore here…
You are almost there. You can put the CASE Switch end inside the loop and add your processing for each category there. Since there is only one loop iteration per group and only one branch of the CASE switch is executed per group/iteration, this should be fine.
Though I must admit that the solution using the Python Script you provided in the linked thread leads to a much cleaner workflow.
Wouldn’t all of the processing have to happen between the case switch start and case switch end nodes? It seems like trying to use the Case Switch approach would constantly lead to battling inactive branches on all but one of the processing streams when trying to initially build out a workflow, unless I am missing some kind of cool trick to Case Switch and maintain multiple active output branches…
If this “Group Row Splitter” comes to fruition, I would love to see the 1st tab of the “GroupBy” node configuration approach allowing us to stack Group columns into the splitter as well! Though that might be a bit too much of tricky thing to pull off on the dynamic output assignment side…
yes, the processing would happen between the Switch nodes. This clearly is a workaround only.
Interesting idea, however, as you mention, it is not obvious to me yet how to configure to which output what data is send. Likely chaining Group Splitter nodes would be easier to understand and configure.
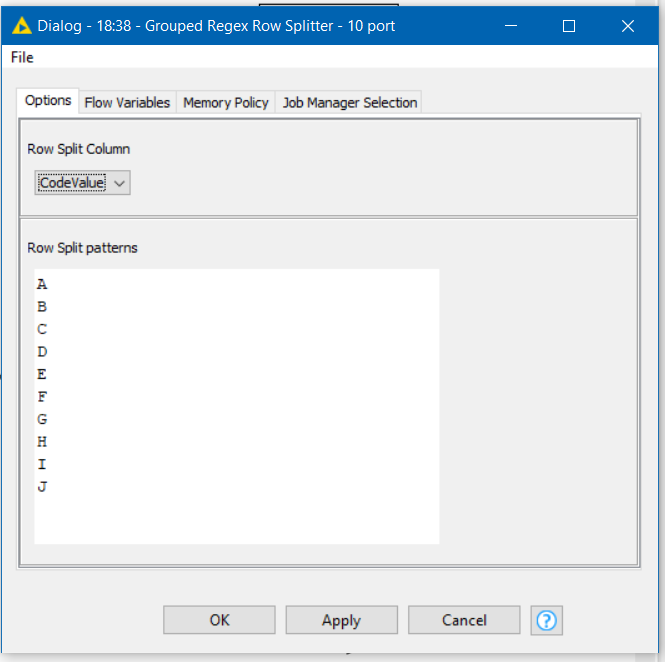
I have created some components which may be of interest. (i.e. use at own risk and please let me know of any issues) These use standard (non script) nodes rather than python and allow for regex patterns to be used to conveniently group rows across 5, 8 or 10 output ports:
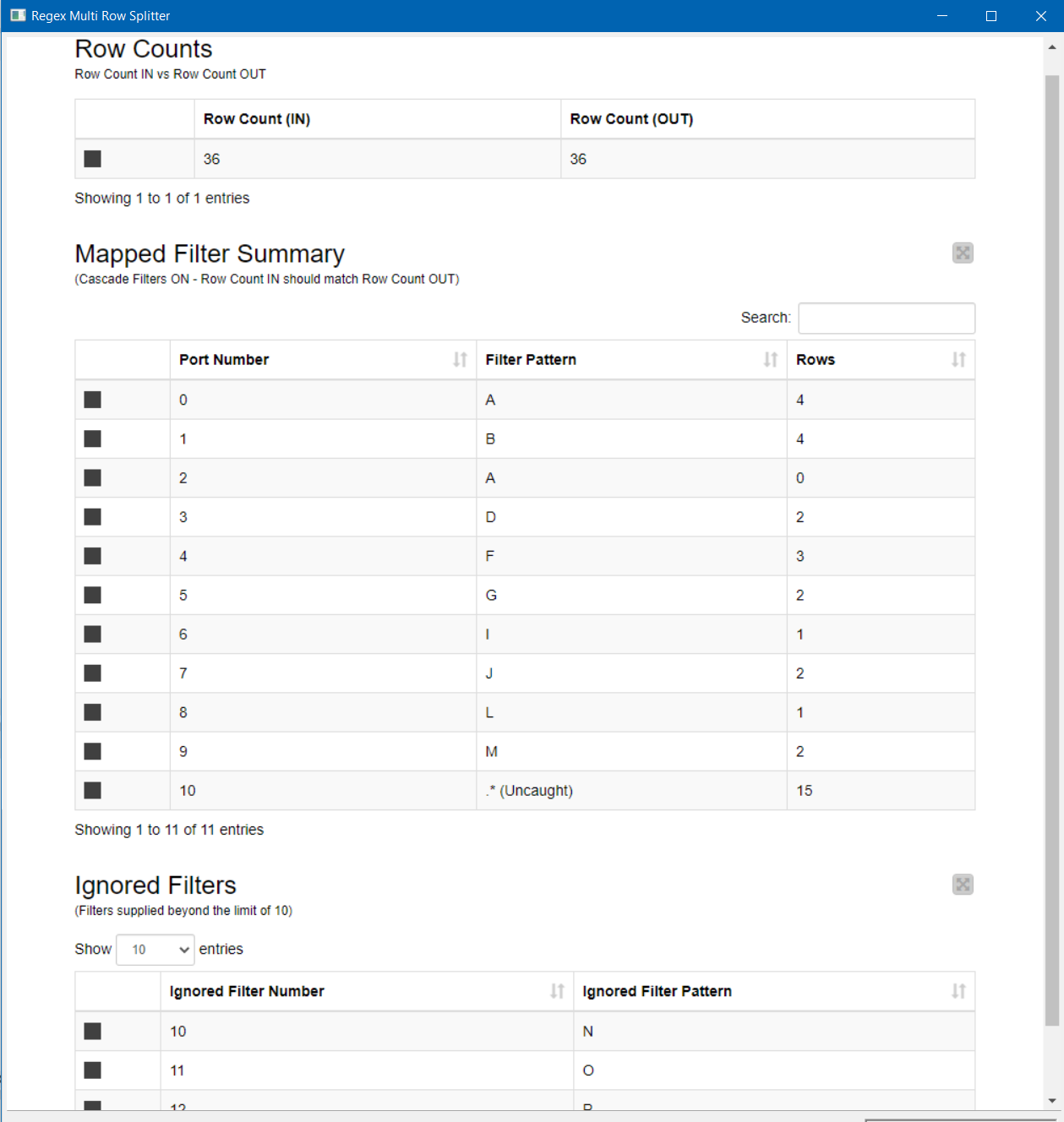
A group of rows will go to all output ports for which it matches the specified pattern. If no pattern is specified for an output port, the output port will be empty. If more patterns are specified than there are output ports, the additional ones are ignored. There is an additional output port (the last one) which shows the mapping patterns that have been used.
If you have more than 10 splits required, you can simply use multiple components. e.g for 16 groups, use either two 8-port or two 10-port components.
I am actually building a last minute budget template for a client now that we will be using at noon, and I was just about to chain together a bunch of row splitters to do this. I will drop this in and give it a shot. Also, I love that you made it Regex based! Not just for flexibility on all of the individual outputs, but to allow for an easy catchall at the bottom output.
Keep in mind that the pattern matching isn’t exclusive so a row will go to all outputs it matches. I was wondering about providing a port that automatically collects all rows that haven’t been collected by the other ports (i.e. your catch-all). If that would be a useful function, then I could look to add.
My only initial feedback would be that ideally it would function like a chained string of row splitters, where rows routed to outputs above would be removed from the pool. Currently, you would have to set specific filters for each output and ensure that there was no overlap causing road duplications or drops. If the output filter routings functioned in series, then there would be no risk of duplication and the final output could simply be “.*” In order to function as a catchall. Very cool though!
Thanks. Useful ideas. I think I could add an option to either behave the way it does at the moment, or alternatively to have true top-to-bottom filtering where rows are filtered in the order of top port to lower port.
That would be awesome. The way it is currently functioning now would be useful to view data in several different segments such as reporting at the end of the workflow when some redundancies and drops are not necessarily an issue, and top to bottom filtering would be more useful in the data processing and manipulation stages.
Hi @iCFO , when you have a spare moment, would you like to test this out
For now I only have built only the 10 port version.
It’s rewritten and now chooses between Row Filters and chained Row Splitters depending on the choice of “Cascade filtering”. If it looks ok, I’ll rename it and replace the 10 port one from yesterday. Didn’t want to break the original in case you were using it
I am loving this component. Dividing streams for separate multi-step analysis, processing or reporting is such a common requirement on my end, that this will likely get leaned on hard. I would personally prefer that the pattern map be sent out by flow variable keeping those outputs uniform as filtered rows. When used in split stream processing, I expected that a 10 input concatenate at the end should be used re-combine the full table. You could even make it an option to sync between multiple component’s filter settings via flow variable. I typically include that sync functionality with many of my in house components, and would certainly use that functionality with this one. You could even turn output 10 into “.*” for a failsafe catchall output when additional rows are still present after cascade filtering. What about calling it the Regex Multi Row Splitter to help people find it in searches?
There are niceties that could be added if it were officially built in node form such as, dynamically adding outputs per filter rule, access to select or reference unique values, automatically adding / turning the bottom output into a catchall “.*” when cascading filtering is active… That being said, it is good to go in current component form.
Hi @iCFO thanks for the continued feedback and encouragement. All great stuff.
I must admit I was in two minds about putting the mapping out as a data table (as it currently is). My thoughts were that because the filters are entered free format in a text box, with no numbering, it was useful to have visual confirmation about which filters applied to which port and I didn’t really want to “clutter” the flow variables as of course these cannot be deleted/filtered out. However, on balance perhaps the flow variable route is better, and I think I’ll include a checkbox of whether to output the mapping as a flow variable, which would just be a list containing port number and mapping so it can be inspected if needed. I only intended it for “debugging/feedback” purposes, but the flow variable could be used to chain with others downstream which I think is what you are alluding to.
I’d be interested in hearing more about the “sync functionality” idea between multiple component’s filters using flow variables. I think I know what you are getting at here, but how do you envisage that working? Would like to hear more about what you do for your home grown components. Happy to try to oblige once I fully understand it
An automatic “catch-all” port… I like it! So that it cannot be overridden by the user’s mappings, I could use that as “port 11” in place of the filter mapping. So you have 10 filter output ports and the additional 11th is always the catchall.
Totally agree about dynamically added ports. Would be great to be able to dynamically add ports on components… If I ever get round to actually writing a node, rather than creating components, this one will be on my hit list! Whilst on the subject of ports, I’d also like to see optional input ports on components, but a story for another day.
I think also that I might just stick to a single 10 port (+catch all port) component, rather than also include a 5 or 8 or whatever port versions. I liked the idea of providing different (smaller) sizes to make up for lacking dynamic ports, because the 10 port is quite space-consuming, but I realised there is quite an overhead in maintaining/fixing multiple versions of components and 10 port is quite a good compromise, especially when we consider the workspace real estate “saved” by having just the single component.
The “Regex Multi Row Splitter”… Sounds good! Watch this space!
When I want to include some visual feedback on component settings / results, I like to put it in the Interactive View instead of an output. Especially if it is something that I only need review during initial setup.
I agree that clutter can be a problem. I certainly wish we could filter flow variables… I hard code my sync flow variable names to something hyper specific that is extremely highly unlikely to be mistaken with others in a workflow. (ex: “xxmulti_row_filter_comp_takbb_colxx”) However, I typically only do this on internal components that can be synced with 1 or 2 flow variables. I also use a table output for syncing when a large amount of variables and settings are required. (I always wish it could be grouped separately from the other outputs visually though) I typically use case switches controlled by a single config setting to toggle between config settings and flow variable / table sync.
I wouldn’t bother trying to maintain components with different numbers of outputs either. One lesson that I have learned from the recent depreciation of the column rename node is that a small change at the platform / node level can potentially lead to a lot of time updating older workflows & components… You have a ton of public components already! Personally, I will probably always use the 10 port version even if it is occasionally overkill for smaller routing tasks. Room for expansion if I need it, and I can quickly copy and paste it around a workflow and use it for more difficult multi-routing situations.
Thank you for all of the responses and thanks for taking the time to build the “Regex Multi Row Splitter” component.
As a new (ish) user the technicalities of the node build is way above my level of KNIME knowledge (for now )but I will certainly be making use of the node in future.
@takbb What about an automatic split setting to use the 1st 10 unique values of the selected column as the splitter list? Then it is as easy as selecting a column and running it to do basic grouped splits.
@fostc80857 had 16 splits in his situation, but since the bottom output is a catchall it would be simple to run those remaining rows to a second copy of the component.