Hello
I would like to ask your help for the following problem.
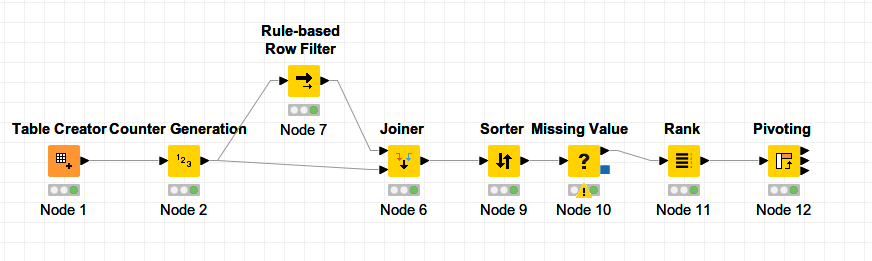
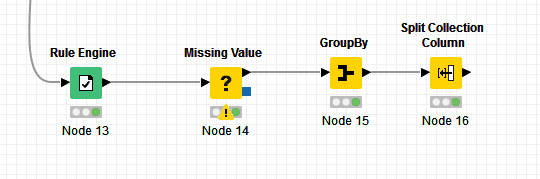
A software that predicts molecules’ toxicities gives the following output as plain text file.
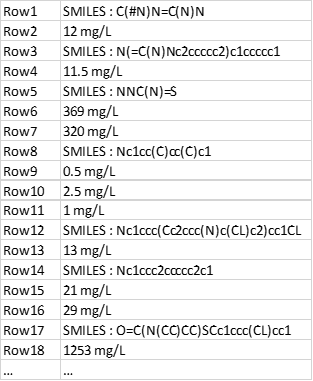
Each line containing the string “SMILES” correspond to one molecule and the rows immediately after it are the respective predicted value(s) until the next “SMILES”-containing string, which denotes the next molecule (and so on). The issue is that, for a given molecule, one to many values can be given.
The desired output is simply to transpose next to each molecule its predicted value(s).
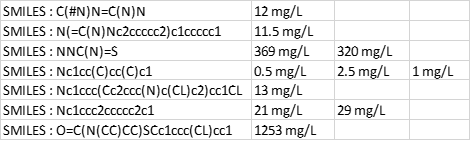
If the number of rows after each molecule would stay the same, this can be easily done with a groupby node. However, as it randomly changes i don’t know how to correctly group each block of rows.
Do you have any suggestion on how to do it? Considering that I am not an expert of java or python scripting…
Thank you in advance.
Filippo