To answer my own question, I found a way but it doesn’t seem elegant.
I can filter by the value I want to count, then GroupBy the main column using the count function.
At the moment I don’t need the other rows, but if I need them later I can always bring them back with a concatenate.
To give more detail, I am generating a large cross table from two data sets (call them A and B), then calculating a score based on various column values (this is currently an integer between 0-5). What I am working it out is how many times an entry in the input table scores 0, so the output would be the same number of rows as table A, with a column value varying from 0 up to the number of rows in column B.
You only need to develop a little more… I am just delivering your desired output
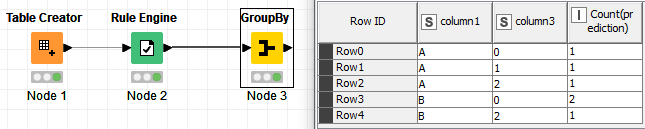
group by the first column and count how many of a certain value there are, eg for 0 output
A 1
B 2
At the moment I don’t need the other rows, but if I need them later…
That’s perfect, exactly what I was trying to do. I group by my first table (ie col1) and the score value, then count how many of the second table (col2) get each score.