I am working with an extremely simple and small dataset 3 columns under 30,000 rows in KNIME 4.6.1.
Individual’s Name
Unique Identifier associated with Individual
Data Source Source Name
There are duplicates across data sources and files.
I read the 3 excel files, each of which have multiple data sources from different systems identified as strings in the data source name column.
Concatenate each of the excel files, as their data structures are the same.
Remove duplicates based on the unique identifier.
Before removing all the duplicates there are ~176,500 rows.
After removing duplicates there are are ~28,000 rows.
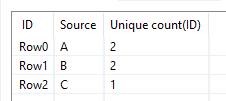
I very simply want to show a unique count of individuals associated with each data source after the duplicates have been removed.
I’ve always been able to use a GroupBy node for this in the past.
GroupBy Node:
Group: Data Source
Manual Aggregation: Unique Count of Unique Identifiers
Originally it failed with this aggregation, even for a data source label that accounted for a majority of the records. I also created another column manually to create ‘one group’ for the entire dataset, and it also failed.
Would it be possible to include a sample set dataset or even your workflow to play around with? On paper it makes sense but obviously something is off.
This seems to be related to the data itself and the amount of data, so it might come down to some settings within the GroupBy node.
@Nathan_Klassen try to increase the “Maximum unique values per group” setting. You can put it to a huge number. This setting is just to let you know that if you do have a huge number of unique value in your dataset, it will take long to process (you may even run out of memory).
But you can’t run within the limits that you have set anyways, so you can push the number and see what error you run into. You can set it up to 100,000 to start with, and keep increasing.
Or as a test, you can run a Duplicate Row Filter on your dataset separately (this node does not have any limit on uniqueness). You will be able to see the expected number of uniqueness. Obviously, do this on the same field(s) you want to Group By on
EDIT: Sorry, I just read this:
There you go, the default value for “Maximum unique values per group” is 10,000. So if you have 28,000 unique, it’s beyond that maximum value. Just change to 30,000 as max (or even 100,000), and you should be good.