Hi
I’m using GroupBy inside a loop- How one force GroupBy to usee all the columns? Each iteration I have other columns to apply GroupBy. I want to use GroupBy in order to get the uniques rows of the table.
Hi there!
If by any case you have same number of columns in each loop iteration you can do following. In each iteration extract column headers, transform them into flow variables and then control the group columns in GroupBy node with those flow variables.
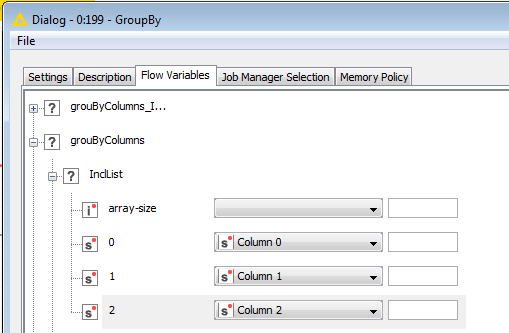
For other case (not having the same number of columns in each iteration) it seems to be a bit tricky and I have to check certain things and get back to you.
Br,
Ivan
Hey Ivan,
I was working on this issue and assumed that the number of columns are changing otherwise as you mentioned there is a simple method to handle this.
There is an option in “Flow Variables” tab under “groupByColumns” category named “keep_all_columns_selected” which gets a boolean value and I guess it should be the right option for this case but I couldn’t make use of it.
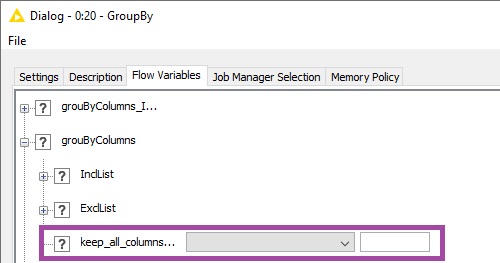
Maybe you can. 
It will be nice to learn this one.
Meanwhile I suggest having the option in “GroupBy” node to enforce inclusion and exclusion. That could work here. Is it possible @Iris ?
Hi Ivan
The number of columns in each iteration actually i increasing by one each time. So it is not a fixed number.
Malik
Hi
Atatched the WorkFlow and the Input file.
Would you please help me to make it consider all the columns?
Best
Malik
EC_input.xlsx (248.1 KB)
EC_Kmeans and EC Classifier-EstiamteNumberOfClusters.knwf (38.1 KB)
I just checked your workflow Malik.
Whatever you’re doing I have the feeling that it’s not the best approach. (Just a feeling, I’m not sure)
Maybe you can explain it to me what this workflow is supposed to do then maybe we can help you even better than how you expected. 
Let’s explain it in a simple word- I have a table of fata- I would like to consider each time the first i columns of the data and get the uniques rows- i run from 1 to n, where n is the number of columns.
Malik
Dear @armingrudd
Did you see my problem?
Malik
I was waiting for @ipazin or @Iris to see if they have any suggestions.
What I asked you was about the whole workflow not the current issue.
Perhaps we can do what you wanna do in a different way so we don’t need to loop over the columns like this.
However I will try to find a way to do the trick.
Armin
Hi there!
@armingrudd
Regarding “keep_all_columns_selected” option I’m still checking that and if this option does what it sounds like it would be the solution for this problem. Regarding enforce inclusion and exclusion options in GroupBy node - seems to me that enforce inclusion option is actually in background cause newly added column in table are automatically not grouping columns. Except for this uniqueness use cases I don’t see how Enforce exclusion option makes sense in this node but maybe I do not see well 
@malik
I agree with Armin to try to do in a different way so we don’t need to loop over the columns like this.
Also I have seen another topic where similar is discussed (Column List Loop Start) so please if this is the same issue don’t open multiple topics.
Br,
Ivan
2 Likes
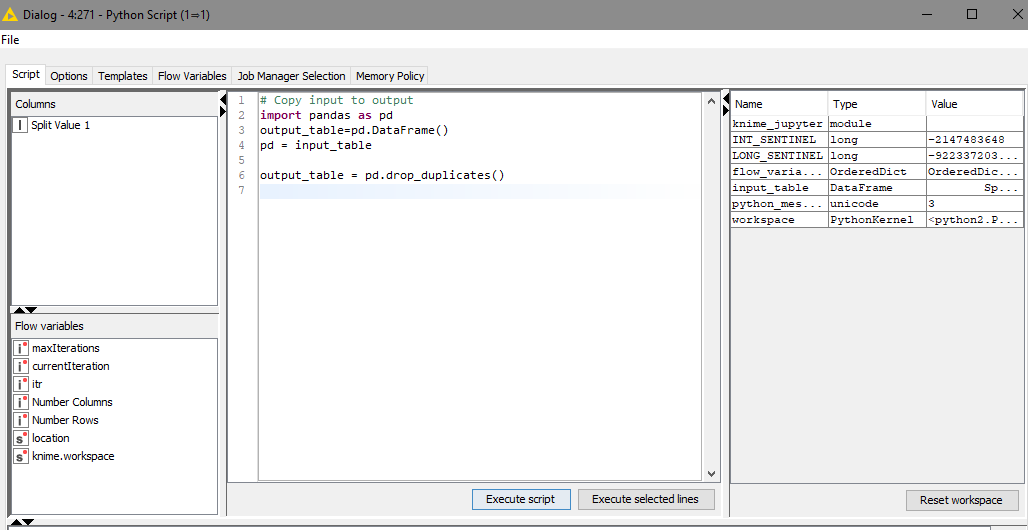
Hi!
Glad you did! Python is a good approach as well in this cases 
Anyways I will try to see can I make GroupBy node work in this case and get back to this topic.
Br
Ivan
Hi there!
This option is disabled and can not be enabled with flow variable. But ticket was written in order to create a dedicated de-duplication node!
Tnx for engaging 
Br,
Ivan
3 Likes