I need to use the GroupBy node to calculate medians on a number of rows. However, in different runs of this workflow there will be different numbers of rows and I would like to not have to manually go in to GroupBy to select them but rather have it automatically use all of them. Is there a way to do this?
I have found that one way to do this is using a loop. Column List Loop Start - eventually ending with Loop End (Column Append) - will handle this fine for an arbitrary number of columns. The problem with this approach though is that it can be very, very, very slow. I have data sets that have 50,000 or more columns (after transposing the table so I can use GroupBy to get the medians from these data sets), and the loop takes quite a while. GroupBy on its own - if I set the columns by hand in manual aggregation - might only take a few seconds to come up with all these medians, but in a loop it takes many minutes to get through 50,000 columns.
If anyone knows a faster way to do this, I’m all ears. I was wondering if a chunk loop might be quicker here?
I can assume that Column Aggregator have to work for you.
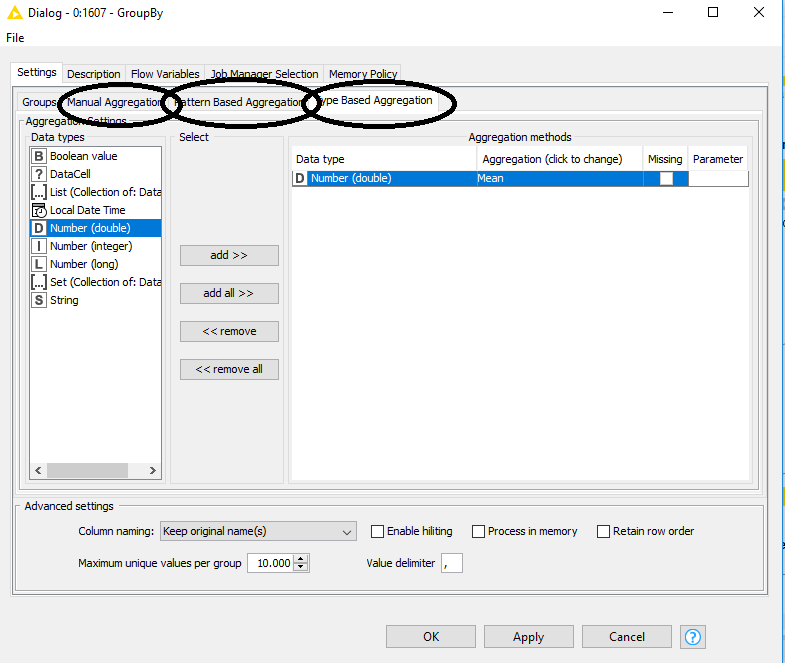
The GroupBy Node also allows to select aggregation columns via wildcard/regular expression pattern or by data type. Have you considered these options?
Thank you both for your replies. It looks like @izaychik63 made a good suggestions with Column Aggregator, it is actually what I needed to begin with (I was transposing my table to use GroupBy, so this saves me two transpose operations).
As for the suggestion from @MH - I suspect my knowledge of GroupBy might not be as good as yours. I am pretty sure I need to use “Manual Aggregation” in GroupBy in order to get the medians that I’m after. I don’t know how to do this with a wildcard match for the columns though, from my experience it seems that Manual Aggregation requires me to manually specify which columns I want to work with.
RegEx is a “bit” more flexible than wildcards:
www.regexr.com
The column aggregator node, aggregates columns not rows. That’s why i think you are stuck with the GroupBy Node.
You can use the same set of aggregations with a regular expressions/wildcards or data type selection. It’s just a simplification that helps to define the columns that you want to group on.
You can change the search strategy in the groupby node with the tabs (see picture).
1 Like