I am using groupby node. And grouping result by a column. Further defined Sum as aggregation method in manual aggregation tab. Result shows me only columns i used in grouping. I want to select all columns. How can i aceive this. Please provide me some help.
The result of a group by operation is always two sets of columns. The "group" columsn with their original values and the aggregated column with some aggregated value. There is not third set of columns. So you either have to add the remaining columns as group columns (which will change the results, though, and is probably not what you want to do) or aggregate the remaining columns with a suitable function.
How can i aggregate the remaining columns with suitable function? Is there any node capable of doing this? Please help me out in this. I am stuck there.
Ok yes i have used this. Actually i was trying to ask is there a way to achive what i origionally asked i.e get grouped columns and also columns which are not used in groupby? I mean by using some other nodes? I tried other nodes to get my desired result but no success. Is there a way
I have the exact question as hassan posted two years ago, but I have been unable to find a suitable answer in the forums.
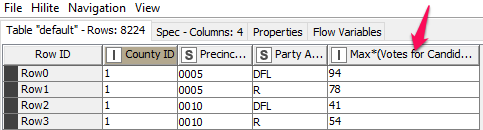
I have election data as shown in Figure 1 where I want to show the candidate with the most votes for each party, grouped by CountyID, Precinct Name, and Party Affiliation. However, I also want to show all other columns without any aggregations (e.g. %Votes, Office ID, etc.).
I have successfully grouped and aggregated the data using ‘GroupBy’ node (see Figure 2), but don’t see a way to pass the other columns. Can someone suggest a solution? Thank you!
If you want to combine aggregated and not aggregated data I would do the aggregation on the levels you want and then join the data back to the original data by the keys you want. If you could provide us with sample data one might have a closer look.
Here is the original *.XLSX file. There is no primary key that is unique to each row. I tried using a ‘Joiner’ node on 1.) County ID 2.) Precinct Name and 3.) Candidate Order Code after Grouping by Max(Votes for Candidate), but none of the aggregations worked.
For example, using ‘First’ Candidate Order Code will just pass the first code and not necessarily the candidate from each party with the highest votes. Is there a node to assign a unique primary key to each row?
To recap, I am trying to extract the candidate with the most votes from each party (D, R), for each precinct within each county.
You could have a look at this. The principle is to aggregate to the information you want and then join it back to the original data. You might have to be careful if there is a candidate with the exact same amount of votes. You might have to have a procedure for that.