seems a lot of time for the data and the type of operation. I have created a fake dataset with 270k rows and tried to group with three columns for grouping and one for unique count and they are processed within seconds. I don’t even have 28GB on my PC
Any chance to have a look at the data/workflow? Maybe we can notice something useful.
Also, there is a very good guide written by @mlauber71 on how to optimise KNIME to boost performance a little bit. Have a look at this article, maybe it can help:
sorry if it took so long to reply, busy day at work.
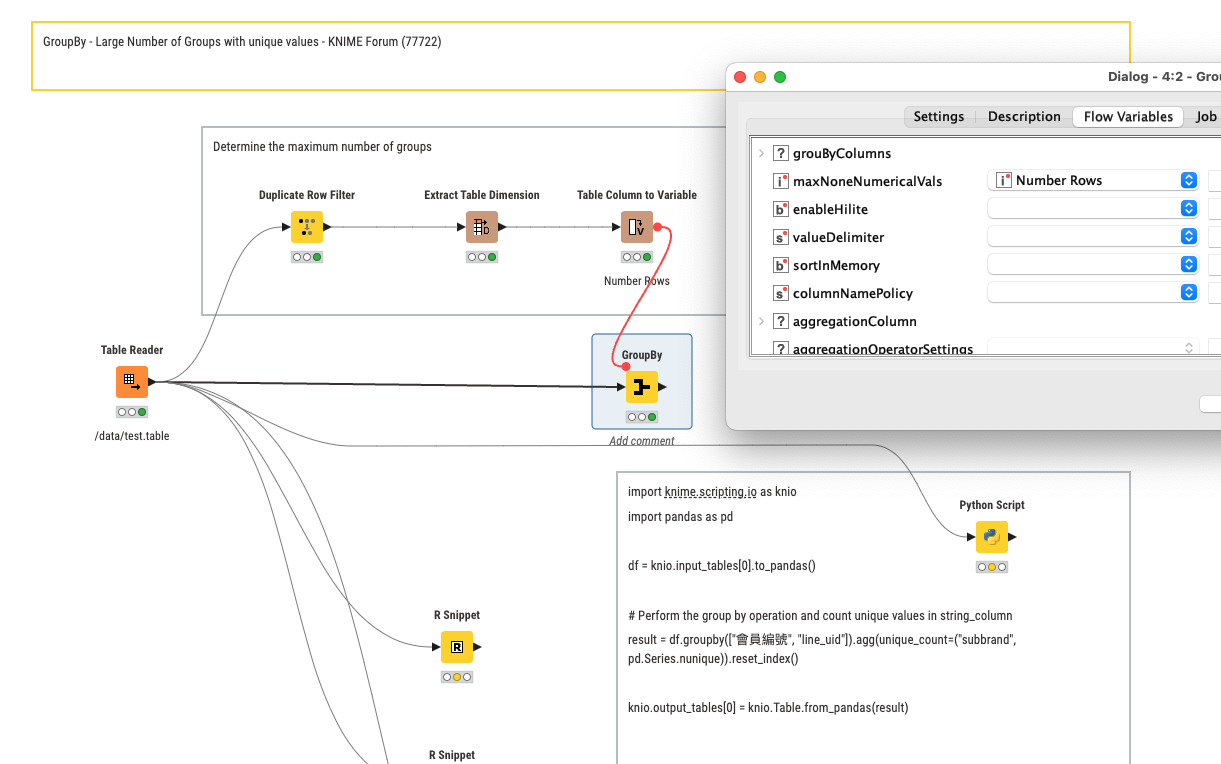
Here is a small wf with two approaches I’ve tested.
By looping on your first column, you will get to the result in a decent time and much less effort
Python: AI wrote it, but it’s sooo fast!
I also tried to reduce the grouping columns from 2 to 1 by concatenating and deleting them, but I haven’t seen any improvement in terms of performance.
thnaks for your reply.
I have tried your two approaches:
The first group by loop seems to send the groupby data to the node in batches for aggregate. The memory usage is significantly reduced, but the calculation time does not seem to be faster.
It is much faster to use R or Python
I don’t know why using KNIME’s native node performance not good. Is it due to platform architecture limitations?
the group loop was just an alternative to using R/Python, which are considerably faster. No idea on why the groupby node is so much slower! But glat it helped
Hi @joey70918 , I just downloaded your example groupby and it performed slowly on my pc too. I think this is because you had set the value of Maximum unique values per group to be a very high number (9,999,999). The default is just 10,000.
I don’t have full details on the optimum value to be used there, but I have seen it noted elsewhere that setting this high severely affects performance.
In this case setting it back down to the default 10,000, which I think looks fine for your data, will allow KNIME to process your 233k rows in just a few seconds.
@joey70918 as @takbb has mentioned you might want to adapt the number of unique values possible. If in doubt one could dynamically determine that value to be sure:
It seems that the setting of Maximum unique values per group will affect the speed.
Because the amount of data is large, I set it to 9,999,999.
@mlauber71 ,
Thank you for the method you provided. It is indeed a dynamic way to set the value, which can make groupby node have better execution efficiency.
@lelloba ,
After testing, the execution efficiency comparison is as follows:
R or Python>
Dynamically set value of Maximum unique values > group by loop(if Maximum unique values per group set 9,999,999