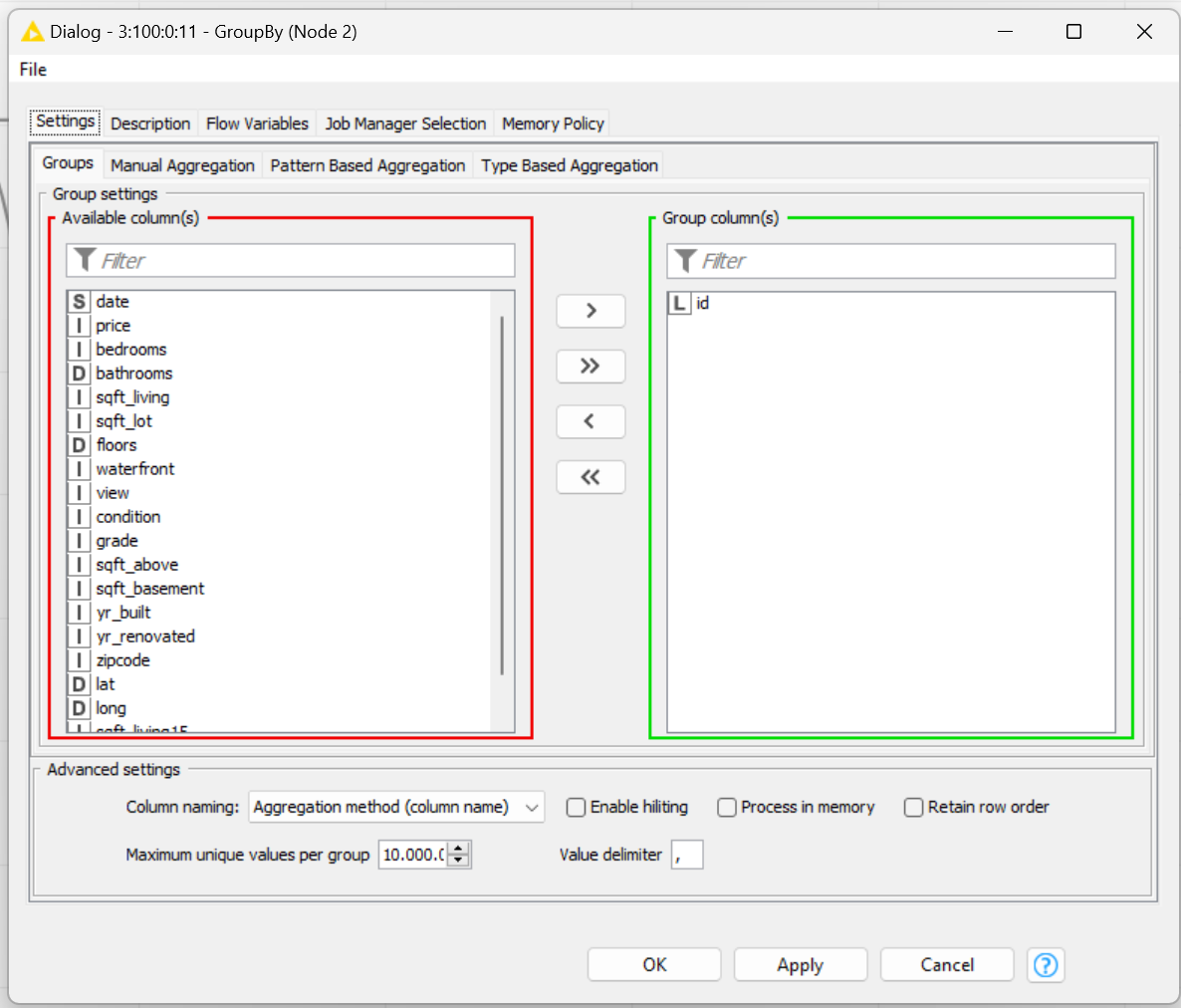
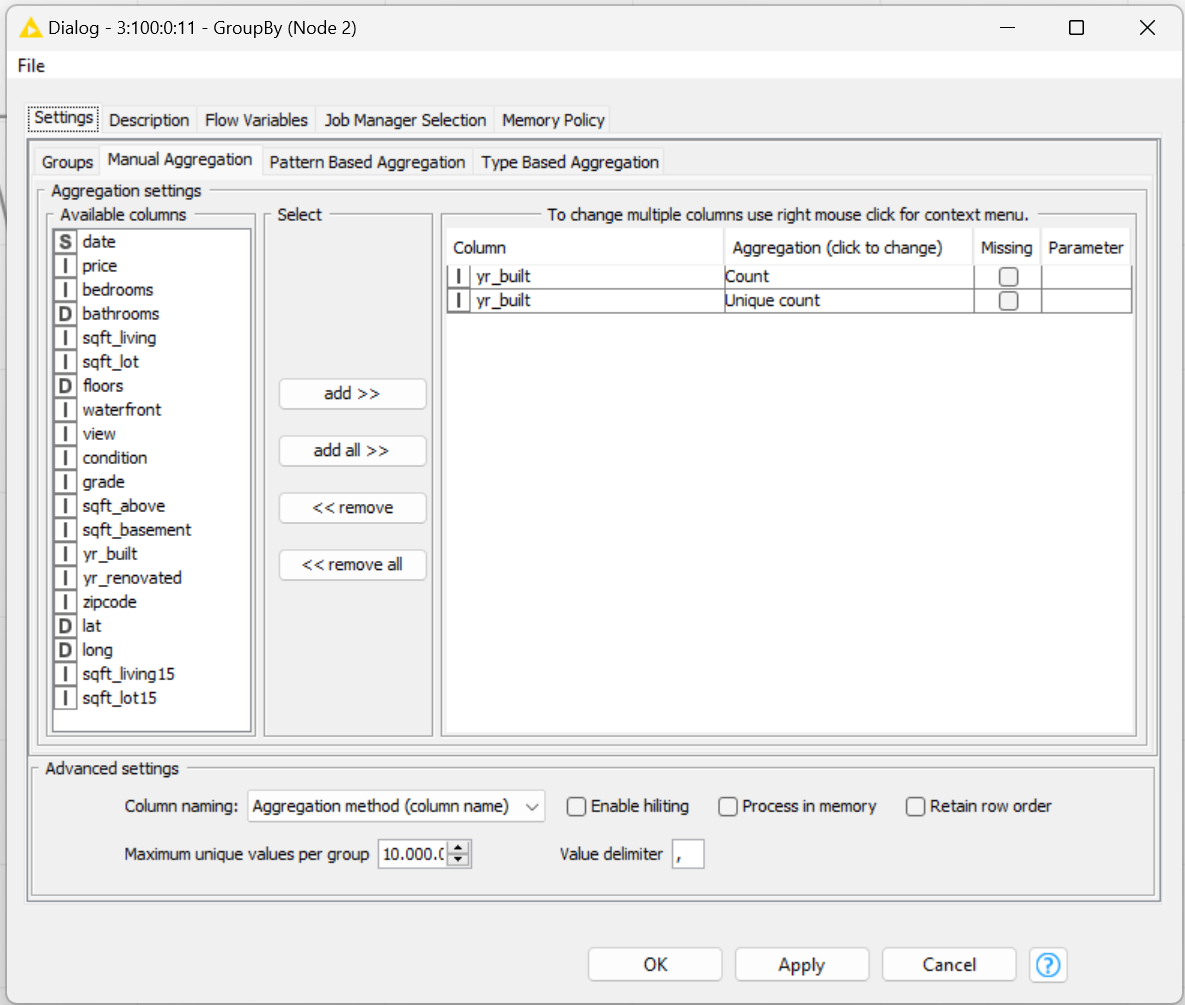
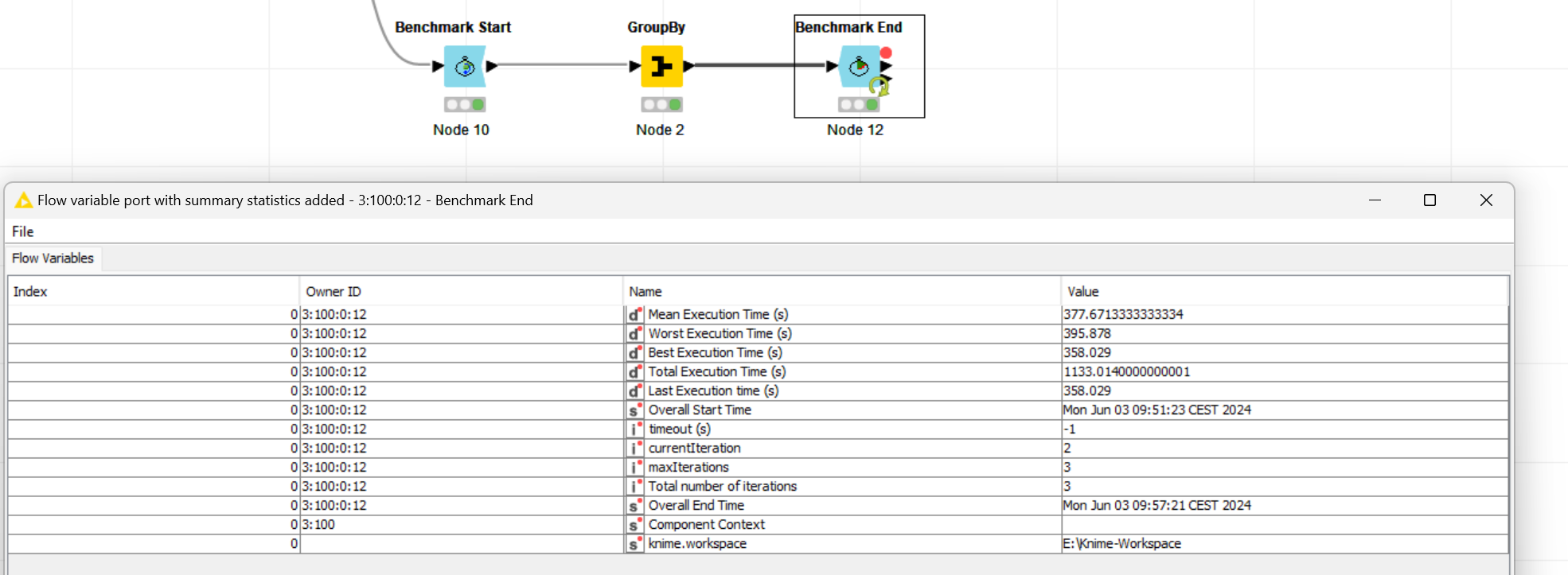
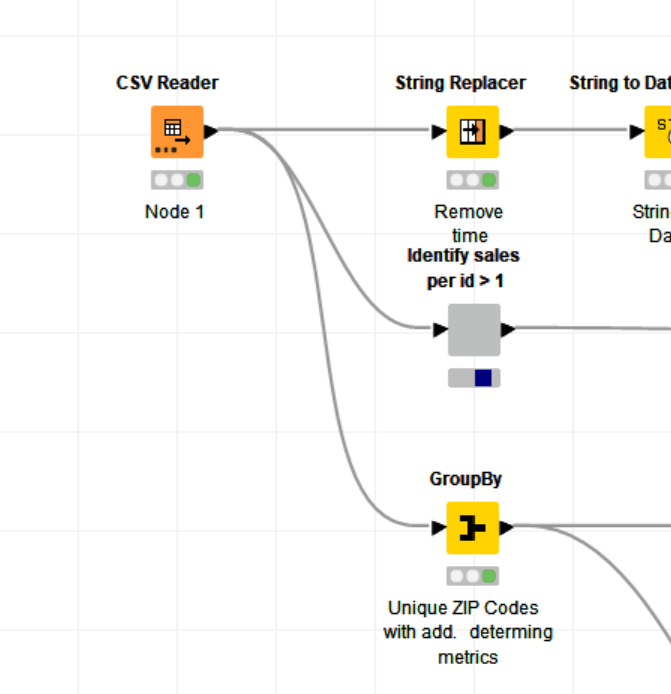
apologize, yes I was referring to the data set from challenge 3. Odd that it is working as quickly as expected for you. Here is my solution, maybe you spot something:
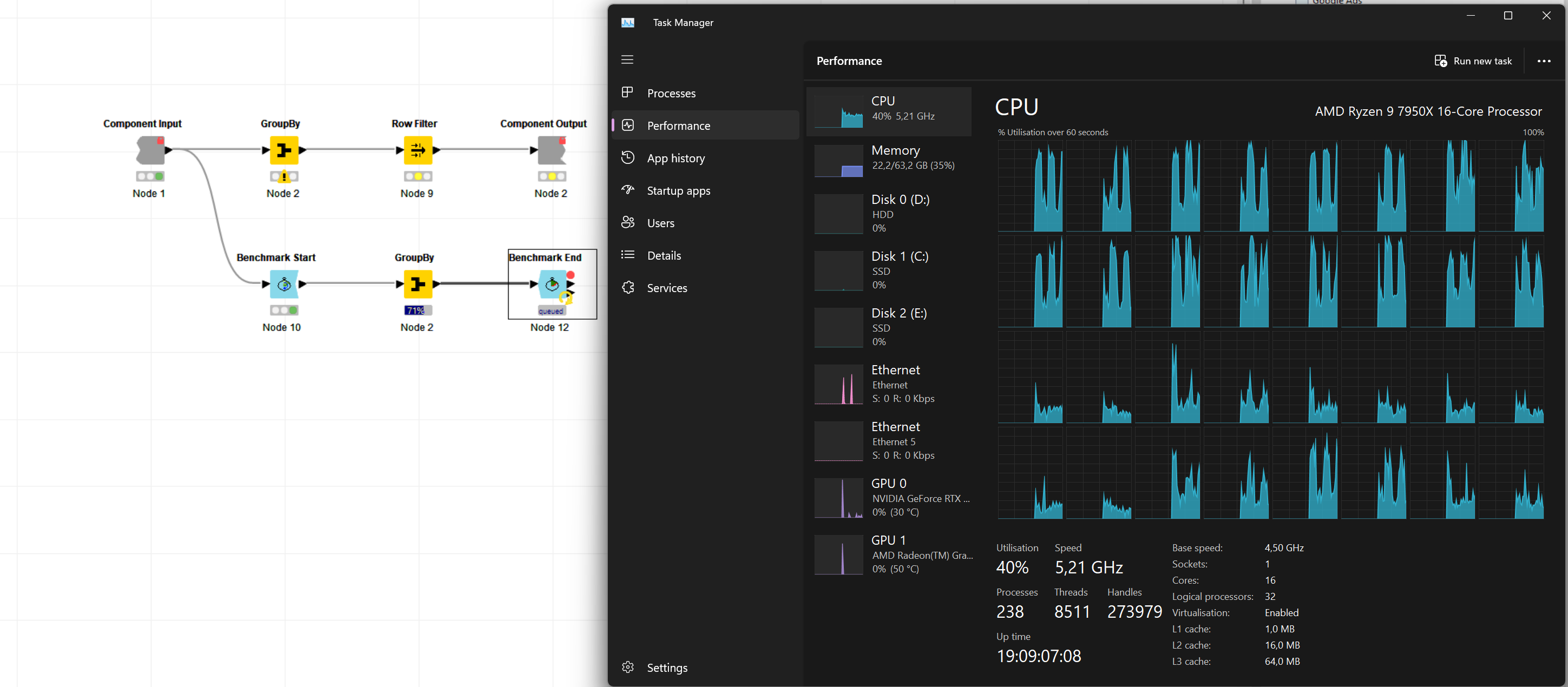
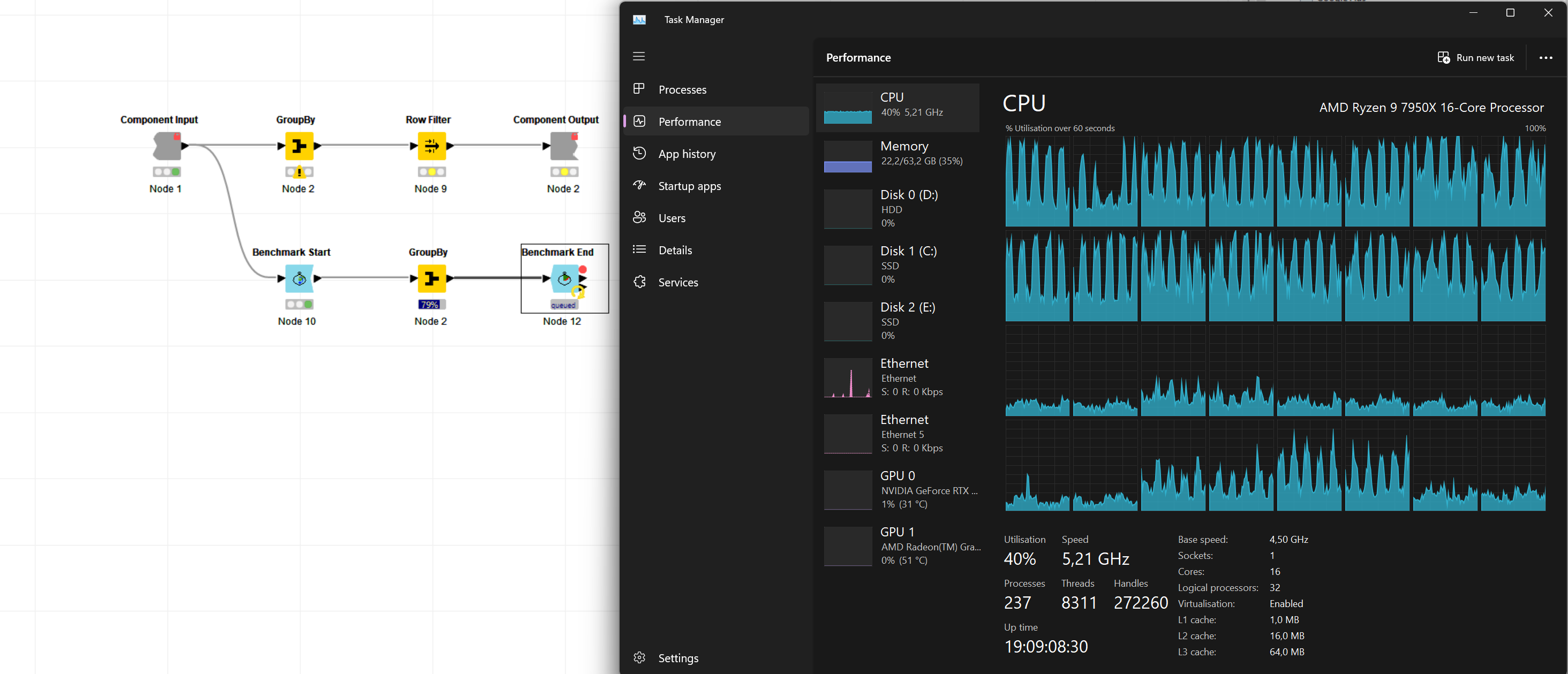
here you go. I closed and restarted Knime. Reset the workflow to until that GrouBy node and started execution experiencing the same regression. I then immediately took aa thread dump, one more around half way through and after processing finished.
Your node is configured to allow group sizes of up to 10M elements:
The default is 10k, which is why my workflow above doesn’t show the problem.
Why did I not notice this earlier when trying your workflow? … because I was using a nightly build (5.3.0 Nightly), which is using a different, more efficient, grouping implementation.
I don’t think this is a performance regression. For these settings, with many groups (21k groups) allowing for 10M elements in a group, it has always been “inefficient”.
In order to fix your problem, either set a different group size parameter or use 5.3.0 nightly (release is planned for mid July).
Thanks Bernd! It seems my understanding of the threshold is not accurate. I thought I ran into compute constraints because the threshold of unique values was exceeded causing missing to be entered. Hence I increased the number, which I did many times before in other workflows too, to a higher number.
Maybe it’s an option to make the skip voluntary as this one setting, please correct my explanation if it’s wrong, does both, divide the ingress data into groups of 10k unique values each, and inserts missing in case of “overflow”.
I still believe I am not getting the concept right, am I?