Dear KNIME community
i have a rather peculiar problem and do not really get why it isn’t working.
Shortly what i do:
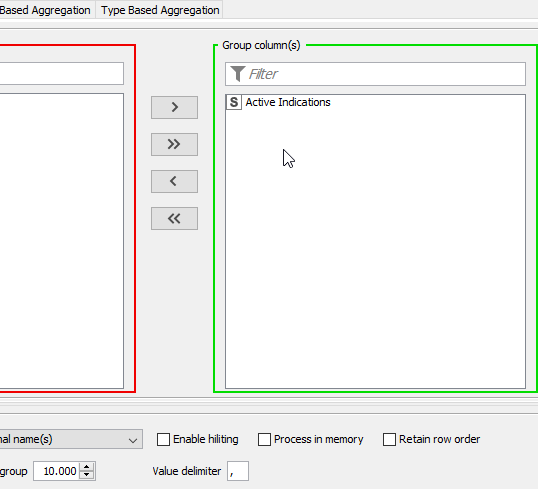
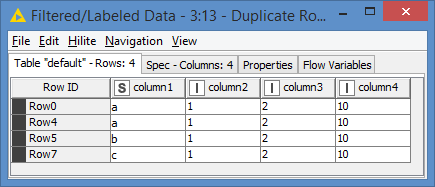
i prepare a kind of matrix view using a “One to Many” node and then want to sum up the occurences
afterwards the output looks like
=> so the entries in the first column is three times the same and i would want to combine the different other columns. in this case i wanted to sum them up, so that i get a final line for the three rows where the numbers in the different columns are simply added/summed up
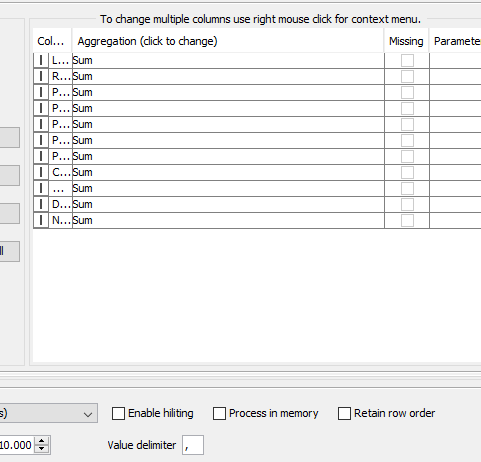
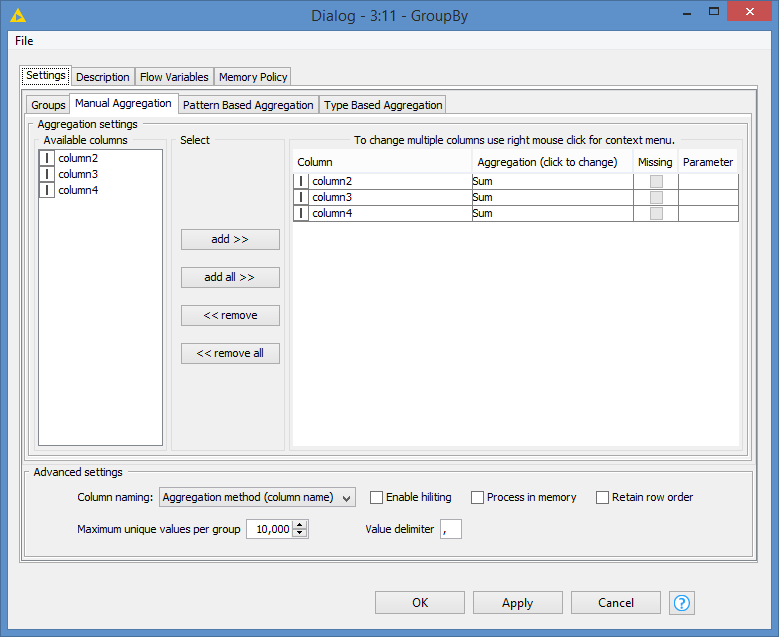
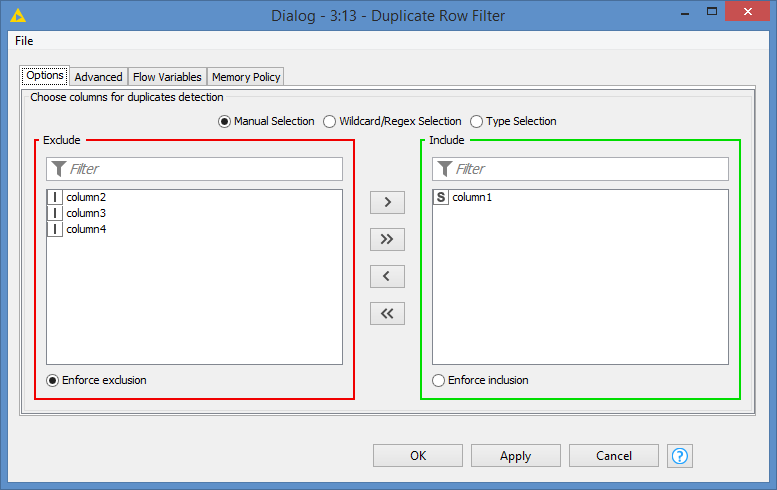
i tried that with a group by on column one and then aggregating the other columns with “Sum”. Somehow it doesn’t work… Oh and i forgot the other columns (apart from column 1) are of type integer …
The groupby node runs but the output is the same as the input …
Hi @And_Z , can you share some data and show what is the expected results that you want?
Can you also share your workflow, or at least show how you configured your groupby? Most likely you are not grouping by any column, that is why “the output is the same as the input”.
Hi @And_Z , based on what you showed for the config, it should work.
Here’s a basic example I put together:
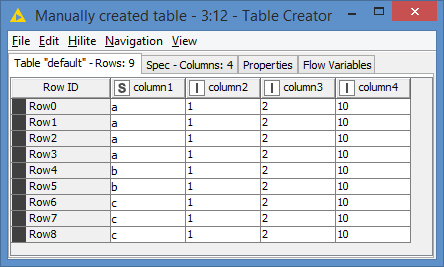
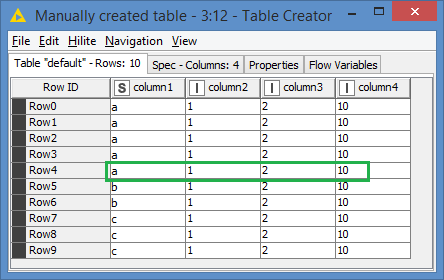
Here’s the input data:
4 entries of a
2 entries of b
3 entries of c
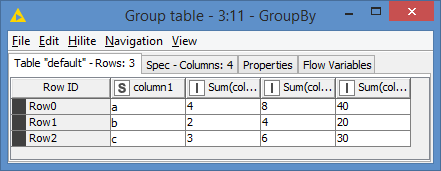
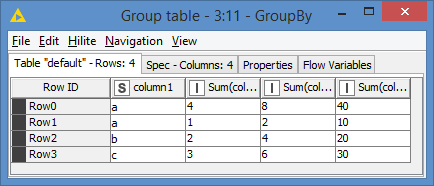
Column 2 has multiple of 1, so we expect to see 4,2,3; Column 3 has multiple of 2, so we expect to see 8,4,6; and Column 4 has multiple of 10, so we expect to see 40,20,30
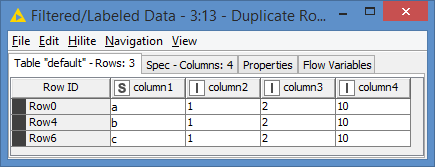
Here’s the result of the GroupBy:
which is exactly what was expected.
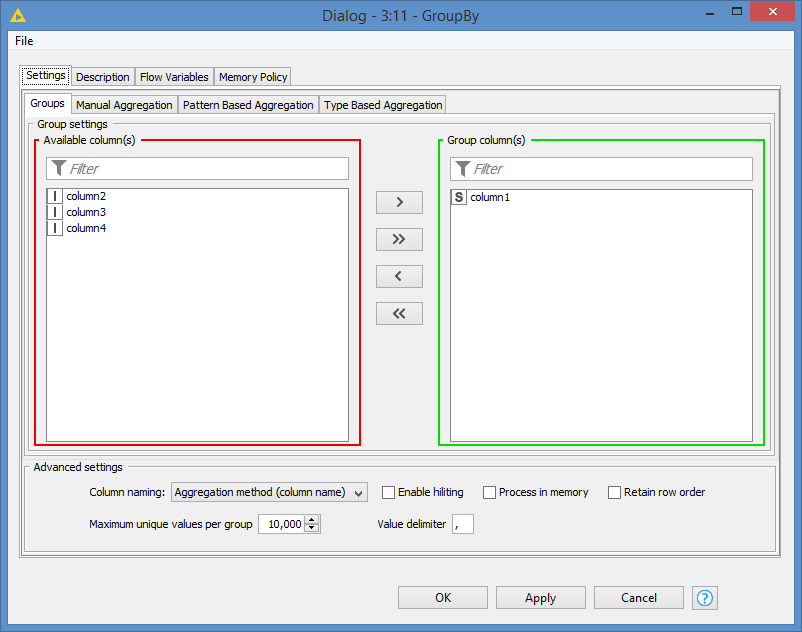
Configuration of GroupBy as follows (same as yours):
The only thing I can suspect in your case is that the values in your first column might “appear” to be the same, but they’re not (case sensitivity, unwanted space, etc…). To test this, do a deduplication on that column and see how many rows you get. If it’s the same amount of rows that you get in the GroupBy, then it confirms the theory.
While it appears that we have 2 entries for “a”, it’s in fact 1 entry for “a” and 1 entry for "a ", which seems to what is happening in your case.
And the deduplicate test confirms it:
4 rows as expected.
If you want to identify which rows have spaces at the beginning or at the end, you can always do a String Manipulation and do a join(“XXXX”, <your_column>, “XXXX”). This would show which record has space before or after the value of the column.
Alternatively, you can also simply “clean” the value by doing a strip() on the column via String Manipulation, making sure spaces before and/or after the values are removed before running the GroupBy
Hi @And_Z
Following up on @bruno29a 's point which sounds to be the most likely explanation, also please widen the first column when viewing your output table, as you showed them truncated and it could well be obscuring the kind of differences suggested. If viewed in full they may turn out to be quite apparent
… oh dear, sometimes the most obivous things are the hardest to find …
@takbb i truncated the column by intention, because of the data.
the solution however is, and @bruno29a ’ idea with the string manipulation was a really good one, that there are serveral entries in that column separated by line feed…
i normally split that from the start, but it is a different workflow here and therefore i forgot …
so i splitted them and it works now…
many thanks @you both
If you have time, could you mark @bruno29a 's post as the solution so that others know it’s resolved, and people can quickly find this in future should they have similar problems.