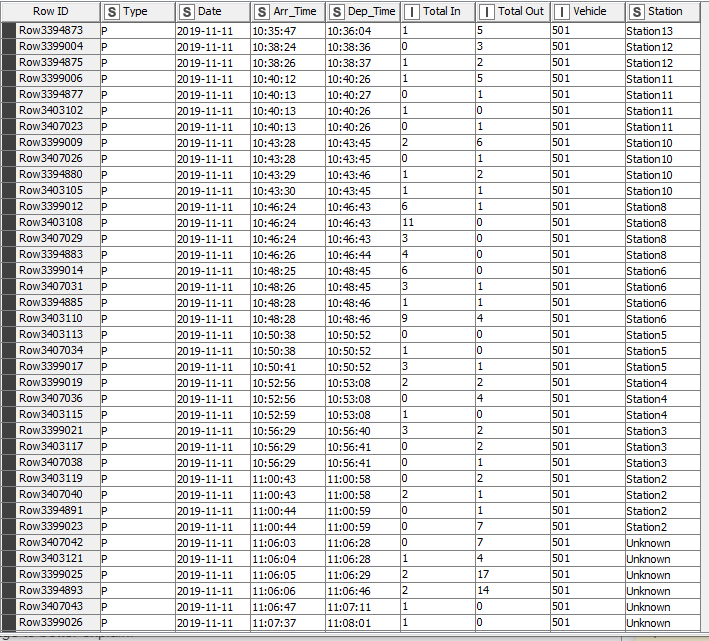
Every record is an instance of train doors opening. As you can see, sometimes this occurs multiple times as a train waits at a station. I’d like to consolidate it so it’s always one row per station, summing up the ‘Total In’ and ‘Total Out’ columns. This means the aggregation should only happen when consecutive rows share the same ‘Station’ value.
You can also see that sometimes the arrival and departure times don’t remain static for a station like they should – I’d like to have the first Arr_time and last dep_time in the resulting row.
Is this aggregation possible with the standard GroupBy node?
I think itś possible. Use the GroupBy node (GroupBy on Station) and in the Manual Configuration tab you can specify the way you want to do the aggregations. See the screenprint. Don’t forget to convert your arrival and departure string to a time-format. But things get more complex if a station is visited more than one time in your table. If that is the case, let us know and provide an sample/dummy data set.
Thanks for the reply @HansS ! I should have clarified, it is indeed the more complicated situation where there’s repeating of stations. I’ve attached the first 1000 rows of the much larger data set.train_dummy.xlsx (53.6 KB)
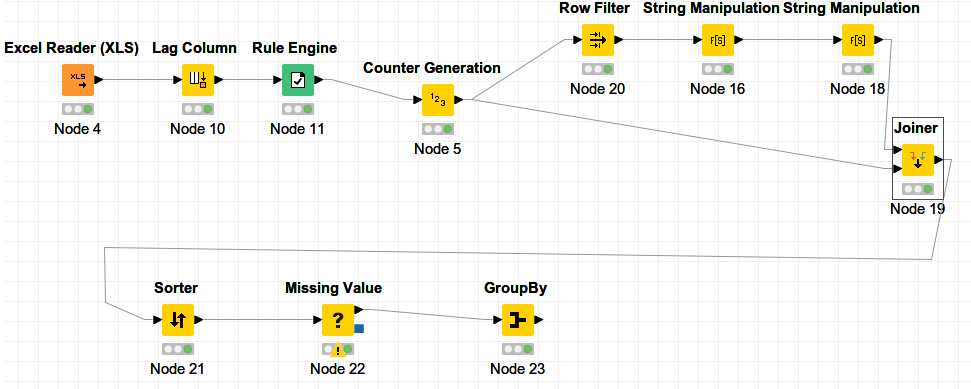
The Lag Column node in combination with the Rule Engine defines the start of the next station. With the Row filter the first arrival on every station is identified; and given a unique id. Those unique station_ids are join to the original file. With the Missing Value node (option: next value) you can make groups of doors open/closed for every stop.
@HansS You’re an absolute legend. I’ll need to try it with the larger dataset when I revisit this next week, but given it works for the sample I don’t see why it won’t. Your approach here is something I will definitely apply to other analyses. Thanks so much.
@braunnz interesting data indeed! Maybe wanna add Vehicle information as grouping column as well into GroupBy node. Although it will make no difference to results you will have it in your result data set.
@HansS you can simplify it by using NOT $Station$ = $Station(-1)$ => $$ROWINDEX$$
in Rule Engine node. This will create unique identifier whenever there is change and leave other rows with missing values. Then you can immediately go with Missing Value node followed by GroupBy avoiding all other nodes in between.