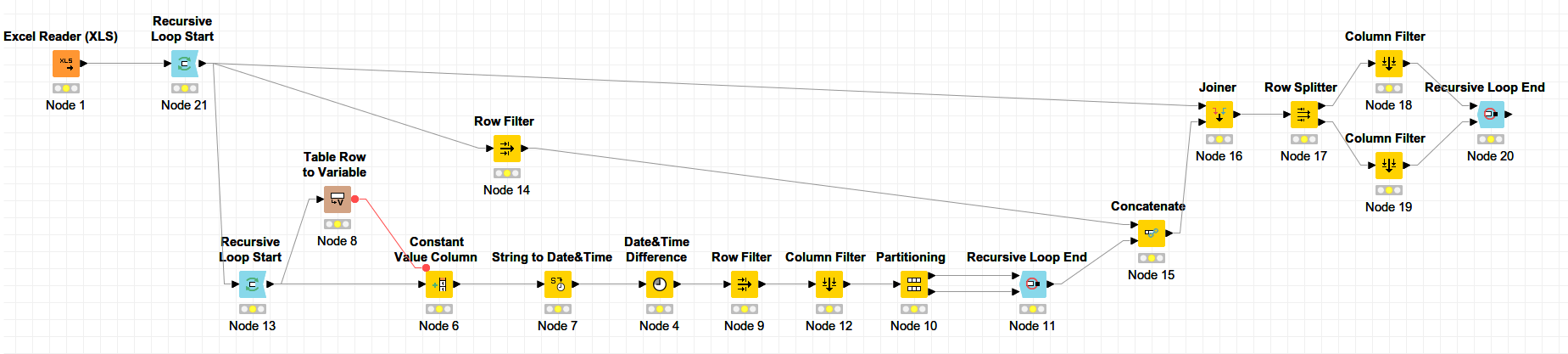
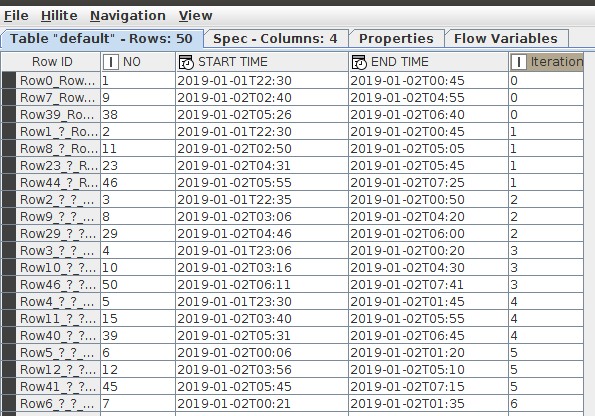
Hello! I wanted to group my rows with some limitations. For example, the 1st red box “END TIME” is 00:45, so the next one would be row with “START TIME” >= the previous “END TIME” + 5 minutes, in this case its the 2nd red box, which “START TIME” is 2:40. The 1st grouping will finish if there are no rows to group. Then, the 2nd group can be done (purple box). And so on…
Does anyone know how I can do this? Thank you very much!
Well, I just came to upload my solution and saw the solution by @Andrew_Steel which is similar to mine in case of using nested recursive loops.
However, I guess I could make it in a shorter form, so I share mine as well.
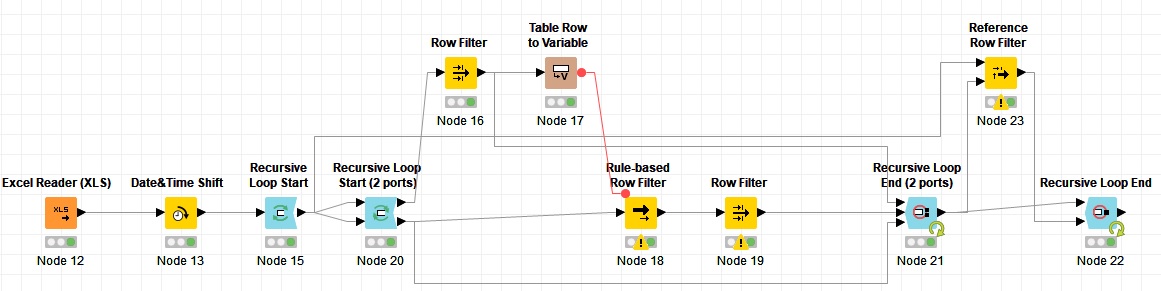
First, I have shifted the end time values by 5 minutes in a new column. After that two recursive loop start nodes: First, a single port loop start node and then a 2 ports loop start.
The first loop gathers all the groups and the second one (the one inside the first one) selects the members of each group.
Let’s see how the loops work:
First, the second loop (the 2 ports): In the first iteration the whole dataset goes to the top port and then the first row is filtered and passed to the Table Row to Variable node.
Then the data from the second port (includes the whole data set in the first iteration) goes to the Rule-based Row Filter node and based on the condition that you mentioned, rows are filtered and then the first one is selected by the Row Filter node.
Now, for the next iterations, the output of the second row filter (Node 19 in the picture) goes to the second input port of the loop end which then will feed the first output port of its loop start and the whole data set goes directly to the third port which then feed the second port of the loop start.
The output of the first Row Filter (Node 16) goes to the first input port of the loop end which is collected as the output.
Finally, a Reference Row Filter excludes the output of the first loop from the initial data set and feed it back to the fist loop start node.
I hope I could explain it well but do not hesitate to ask your questions.
Here is the workflow (not reset): time-based-groups.knwf (55.7 KB)
Best,
Armin
P.S. Dear @Andrew_Steel, I think you have to double check your workflow as I have noticed a flaw in your output.
E.g. The end time in the 5th row of the final output is 05:05 but the start time of the next row with the same group counter is 04:31 (in the same date).
oh, yes, thanks. That’s a good idea (Grrmml). Two mistakes (Grmml, Grmmm).
I’ve changed the partition node into row filter, because the partition node extracted the first row, but I need this row for the next loop. And I changed the row filter (node9). 500 seconds are not 5 Minutes (Argrrrr…). Finally, we have the same outcome.