This workflow investigates the composition of gut microbial communities from individuals with inflammatory bowl disease (IBD). Samples were taken from 10 donors (1x) and 10 patients (3x) before and after a gut microbiome transplant at different time points. The V1 and V2 region of the 16S ribosomal RNA gene sequence were sequenced from total of 40 samples using 454 GS FLX Titanium sequencer. The corresponding sequences, with accession ID PRJDB4959 will be downloaded from ENA.
The workflow uses the DADA2 R package by Callahan et al. to determine the microbial composition from the 16S sequences. The DADA2 R package needs to be installed for the workflow to work. Installation instructions can be found at https://benjjneb.github.io/dada2/dada-installation.html
MANUAL: DADA2 Software instalation manual https://benjjneb.github.io/dada2/dada-installation.html
Hi! I would appreciate any inputs on how to go about setting up this workflow to analyse phyloseq files. I’m unable to open the configurations of the prepare essential variables node in Knime, can someone help me implement this workflow in knime? I would really appreciate any support on how to go about it, thank you so much in advance
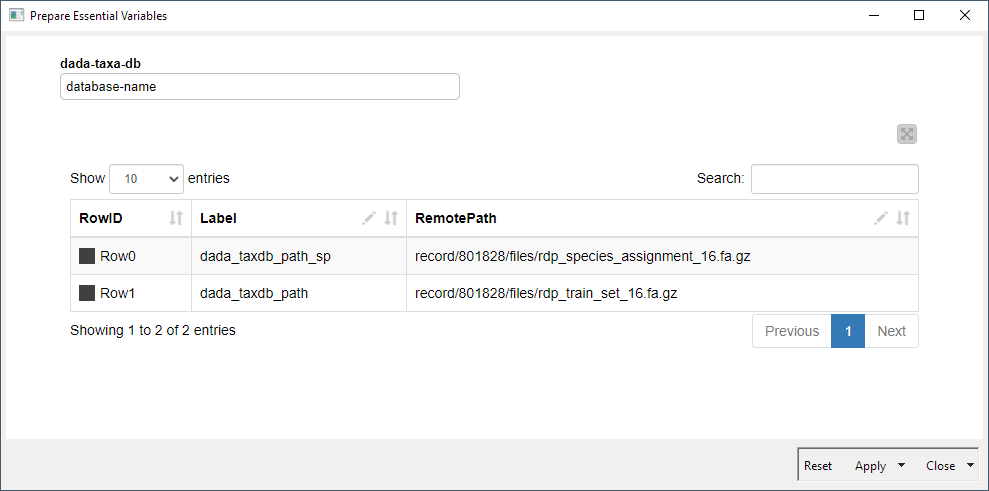
“Prepare Essential Variables” is actually a component in this workflow, as opposed to a node. To make changes to it, you need to right click and select Interactive View, which will bring up a dialog like this:
It’s hard for me to tell for sure since the resolution makes it hard to read, but I think you need to execute the component first before opening the interactive view.
There is a warning sign on the component but that might go away once you execute. If it doesn’t it would be interesting to know what the KNIME log says at that point.