My team and I are trying to measure the significance of repetitions on the virality of a song in the music industry.
We have learned about the H-P point approach from this article.
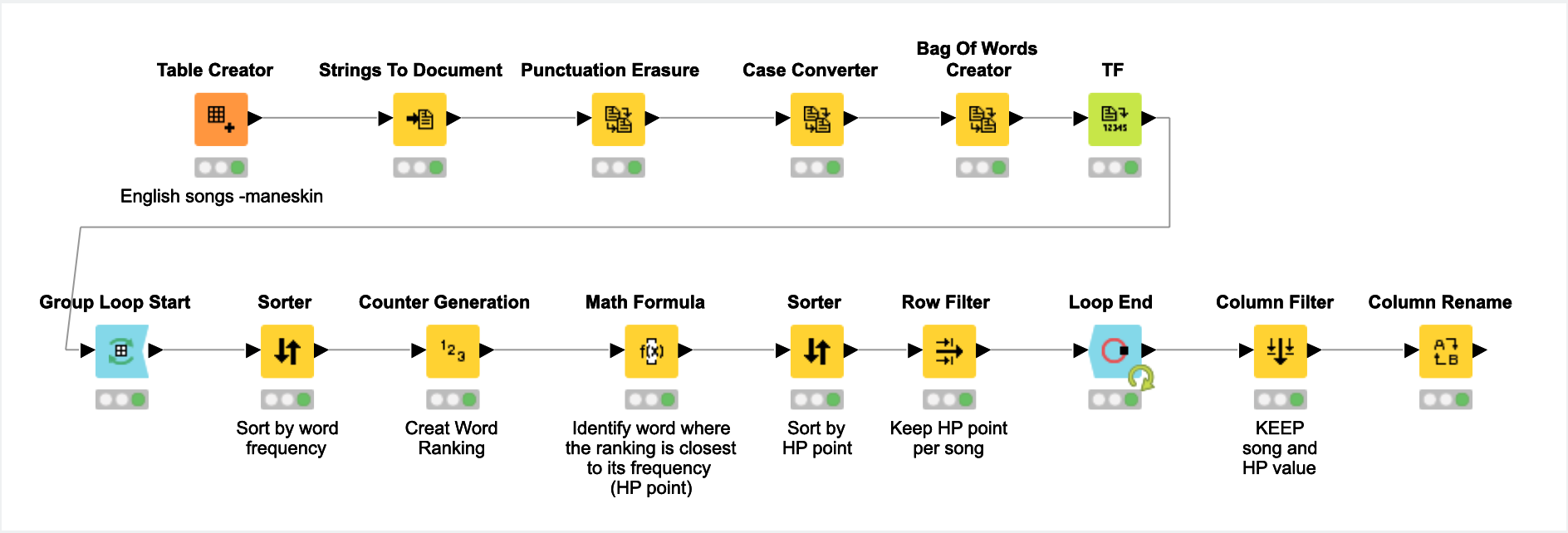
However, we are having troubles on implementing this approach on Knime.
We have a dataset that contains (artist_name, song_title, song_lyrics)
After performing a Bag of Words, our idea is to split the dataset into different sub-dataset containing the song title, artist, and the TF (abs) related to the word.
At that point, we could use the row ID to check whether the row value of the TF is equal to the row ID.
Yet, we would need some guidance on this as we are not sure this is possible in Knime and we also believe it would result into a significant computational effort.
Also, we noticed that through the GroupBy we can aggregate by TF as a list, however we don’t know how to manipulate it afterwards, could this be another option?