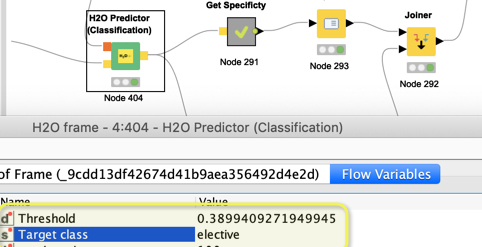
You could use The Rule Engine and define the Threshold yourself. As @SimonS explained H2O.ai uses an optimized threshold so there is not a simple split at a score of 0.5.
The best Threshold/prediction very much depends on your business model and what you want to do with the results.
You could read more in these entries, especially about the ROC curve.
Models for 0/1 or Yes/No Targets
Understand metrics like AUC and Gini (and use H2O.ai)