I attached a working example of a Random Forest with H2O.ai nodes and a 0/1 Target from a Kaggle competition (please note the example only uses the first 1.000 lines, you should remove this restriction or use your own data for your own purpouses).
In order to get an idea about the quality of you model you might want to read this article:
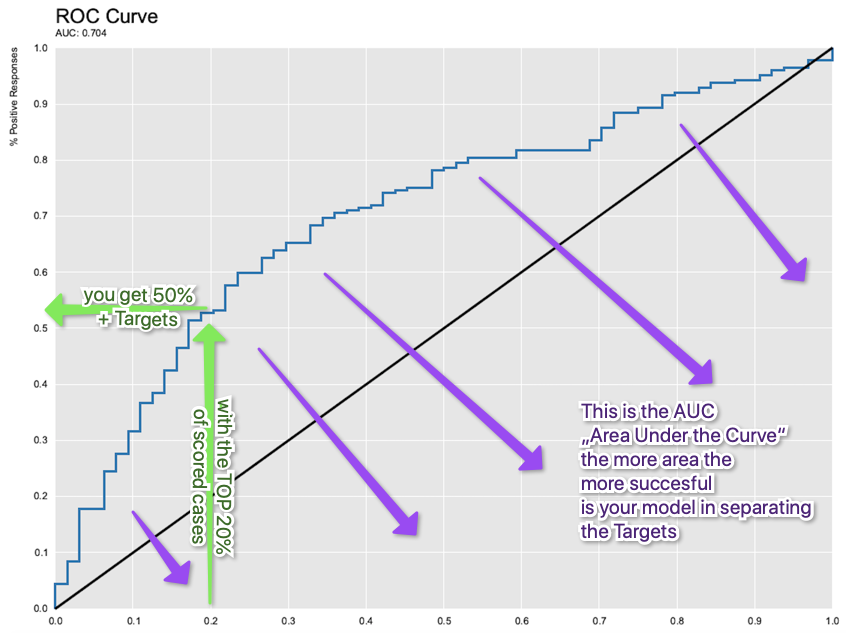
I always advise not just to use a Scorer but rather a metric like Gini/AUC to see the relative quality of the model. In the end the ‘score’ is not a magic ‘prediction’ (some people treat it like that) but in the end it gives your individual case/customer a (relative) rank with regard to your target/label based on a probability of success/purchase. Depending on you model setting (balancing) you might be very careful interpreting that as a real world probability or accuracy. You would want to define the cutoff yourself depending on you business needs and calculations: what is the cost of a wrong classification? Just a missed direct marketing call or a lifesaving drug not working/killing the patient.
If you want to explore more complicated models and compare them KNIME has provided us with another example from a Kaggle competition that is worth studying (also relying on the great H2O nodes):
Please think about what success metric is the right one for your task and compare them for the models you want to test (always on a separate sample or untouched real world data). Common sense is also allowed to be used. If you find a seemingly perfect model for a very complicated task there is a good chance you mixed something up in your data.
kn_example_random_forest_h2o.knar (825.7 KB)