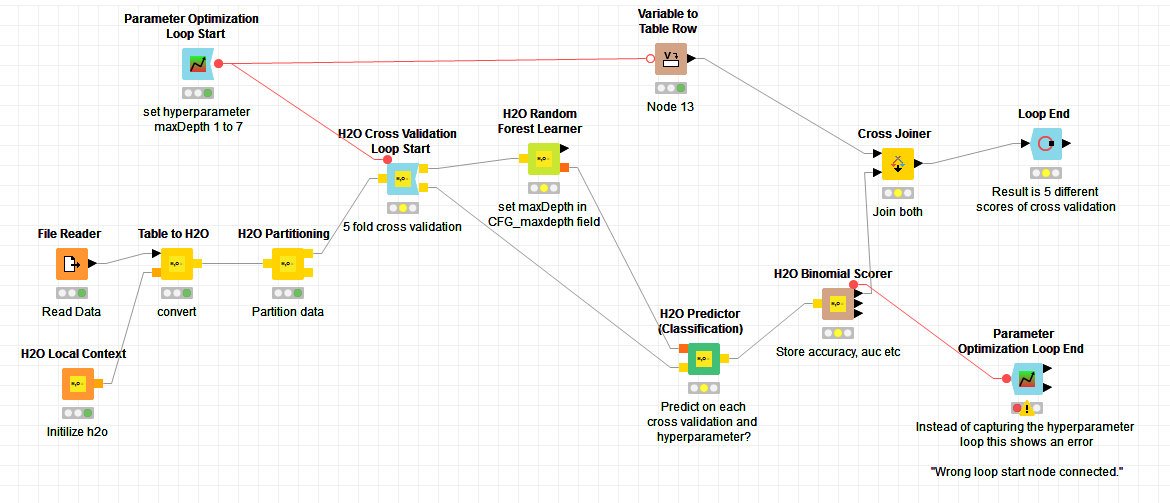
Problem:
I want to run a h2o randomforest algorithm with parameter maxDepth ranging from 1 to 7. However, I do not want to use the whole data instead divide it into 5 fold (cross-validation) and then identify the best result.
Through various tutorials and forum discussion, I was able to achieve the following workflow but get an error when ending the optimization loop.
the very beginning of your workflow looks good already, but the ends of your CV and hyperparameter optimization need to be restructured. One of our blogposts describes in detail how to do hyperparameter optimization and CV with H2O nodes and it comes with a supplementary workflow. Feel free to use it as a template and adjust it to your needs.