Hi! I would like to build a predictive model for classification. It should be a binary classification that aims to predict which patients are “DIFICULT” or “EASY” to have a specific disease.
Is the H2O model in some way different than the normal machine learning algorithms? I’m implementing the Random Forest nodes (learner and predictor) to do a prediction about my patients. Also, with H2O model I have the option to use the Random Forest algorithm, which I have also implemented. I have compared both models and they give different results. In the H2O binomial scorer, I can specify which is the target class I would like to predict. In my case, my interest is to have a good prediction of the patients classified as “Difícil”.
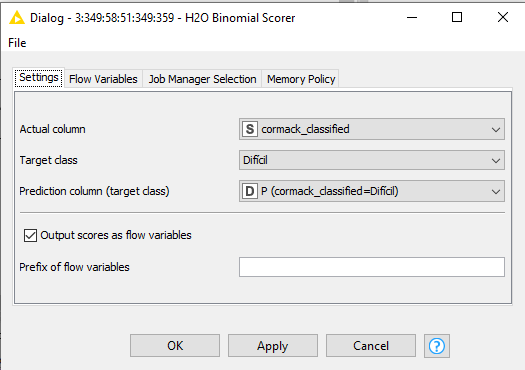
However, in the scorer node I can not specify the target class, just the column I would like to predict.

Is this fact giving different results in the prediction?
I have another doubt regarding the previous question. In my workflow, I have optimised the parameters for each model and then I have compared all the models. For example, from the picture it can be seen that I have built a H2O Random Forest. With the node “Parameter Optimisation Loop End”, I have registered the parameters from the model that give the best accuracy. Then I have written also the name of the model thorugh the node “Constant Value Column”
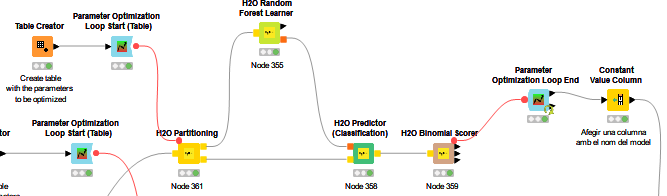
The output from the Constant Value Column node is the following:
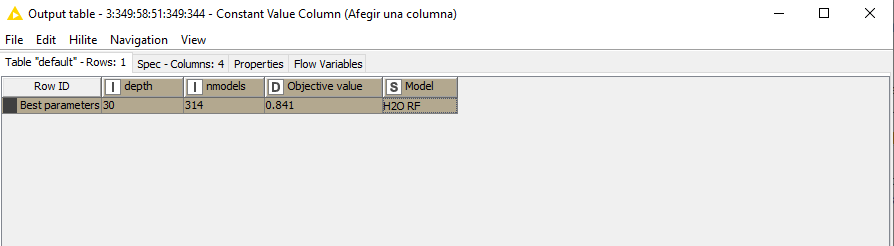
As I said, my interest is to predict appropiately the patients classified as “Difícil”. In the ouput table, I would like to add information about the difficult patients well predicted for the best accuracy model.
Blockquote
Is there any possibility I can do that?
Thank you in advance.
Helena Fortuny