Hello
How one can use the H2O Random Forest node to deal with imbalanced data?
My data consists from 222 pos and 1250 neg?
Hello
How one can use the H2O Random Forest node to deal with imbalanced data?
My data consists from 222 pos and 1250 neg?
Hi @malik,
there are basically two ways.
The first way is to balance the data before converting it to an H2O data frame. You can find easily more information about this in the forum. See, e.g, Unbalanced data - good practice and SMOTE for further details.
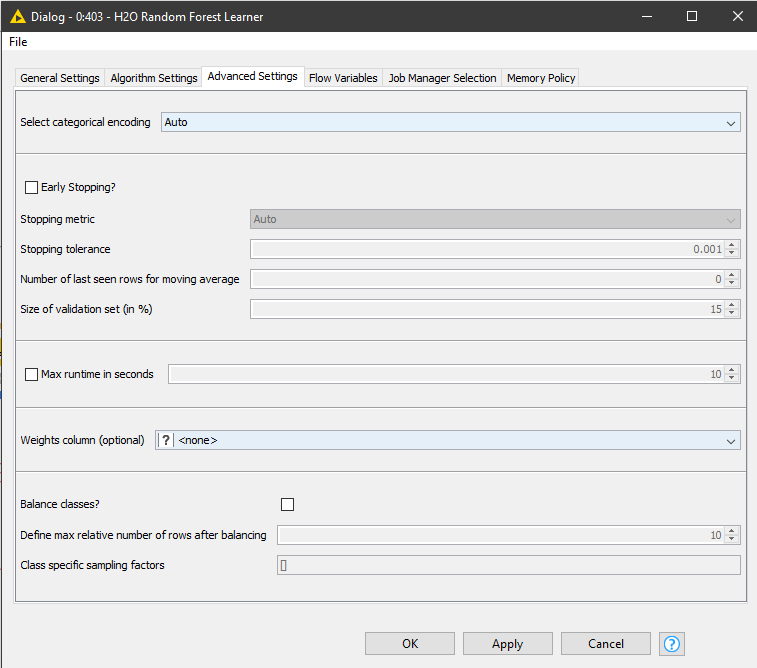
The second way is the “Balance classes” option shown in your screenshot. By checking this option, H2O will automatically balance the classes. With the setting “Define max relative number of rows after balancing”, you can control how much balancing is done, see also here. If you set the number very high, the classes will be balanced equally no matter how skewed they are. The setting at the very bottom even allows you to manually specify the balancing factors but you can just leave it empty as it is and the factors will be calculated by H2O.
Hope this helps you,
Simon
First the question why specifically H20 random forest? Just something you should always ask yourself why your are using that algorithm.
I suggest you avoid SMOTE like the plague. Too easy to do something wrong and even if you do it right, you are training your model on artificial data generated by another model. If from the available data you can generate useful artificial data, you probably won’t need it anyway due to clear class boundaries.
Before doing any balancing, I would just try without it. Your case isn’t really that unbalanced. If you want to balance Instead of the Balance classes? options suggested by Simon I would use the weights column with which you can give each row it’s own importance. A simple way is to give all rows of the minority class a higher weight. weight 1 for majority class and “num rows of majority class” / “num rows of minority class” as weight for the minority class, eg 1250/222 = 5.6. you can create the weights column with rule engine node.
Thanks for that addition, @beginner. Using a weights column is definitely a good idea.
In the end, one can simply try all the different ways out and see what works best. As always, it depends heavily on the data.
Cheers,
Simon
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.