when I copied a table within hadoop (table A to table B) in overwrite mode the resulting table B
had more (!) rows than table A. The additional rows are somewhat “corrupt”.
As an alternative I tried the DB SQL Exceutor node with the following code:
drop table B;
create table B like A;
insert into B select * from A;
This worked fine !
Now to debug I would like to see the SQL statement which the DB Connection Table Writer node uses.
However, I could not find it out (even not in DEBUG level)
Could you tell me pls. which (Imapala) SQL is executed by this node ?
PS: by the way: meanwhile Impala is supporting SQL insert statements
(this should by fixed in the db insert node)
To use Hive and Impala you might have to follow some steps. Eg. before you use the Connection Table Wirrer to make sure that an existing table has been dropped. And also make sure that the Connection Table writer is set to overwrite an existing table (it is always better to make sure the table in question has been dropped).
You might want to take a look at these examples to get an idea what to do. The Hive commands mostly do work also for Impala - Impala in addition offers statistics (that Hive will then be able to use).
Indeed I had already experimented with dropping of table B before recreating it.
and it might also be a hadoop (not a KNIME) problem in this case.
But to debug this it would be good to see the SQL which is created by the
db connection table writer.
From my experience there could be strange behaviour between KNIME and Cloudera depending on the version (mostly of Cloudera) and sometimes Hive is not up-to-date if you do things in Impala (why it does make sense to always compute the statistics in Impala).
With so many things in Big Data often it does make sense to double check what the system did in the end.
As a further anecdote: writing from Spark to Impala sometimes the the Cloudera system dose report that the file is still there while it is not. I had to revert to creating such a file from KNIME computing the statistics and the deleting the file so Spark/KNIME/Impala would accept that the file indeed is not there. Yes this sounds strange, but to a certain extend Big Data is still under development and you have to take care of some items yourself in order to get a stable production.
Can you explain what nodes are you using? Do you mean HDFS with Hadoop and copying files around or do you try to copy tables with the DB nodes and an Impala connection? Or do you mix HDFS, Impala and Hive?
Most of the nodes log the SQL they use. I would suggest to try another table name than simply B. The big data stuff like Impala/Hive removes files asynchron in the background. If you remove a table and immediately write again a table with the same name, than this might result in old and new files if you access them on different ways.
Table A is an existing table within a hadoop cluster. Table A is copied directly to table B via DB Connection Table writer (i.e. copy within hadoop). I’m using Impala SQL.
I used A and B just to simplify/generalize the problem.
In reality A and B are longer table names
I used logging level DEBUG but could not find anywhere the SQL
Do you have a workflow or a screenshoot of the workflow to reproduce this? You can use the Create Local Big Data ENV to create a local Hive setup and make a simplified version of your worklfow.
I have removed your post with the workflow since the DB Connector node might contain sensitive data. If you share workflows please make sure to remove all connection information first. Thanks.
Before removing it I had a look at the workflow and couldn’t find anything that worries me. The only thing that you could improve is to replace the DB Connector node with the dedicated Impala Connector node but this is mostly cosmetic since they both do the same if you select Impala as DB type and dialect like you did.
@sascha.wolke the workflow is straight forward and looks like this:
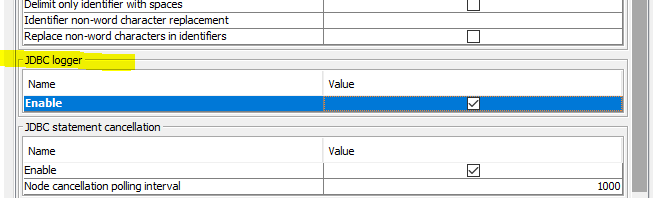
Regarding the JDBC logging. Because of performance reasons you need to explicitly enable the statement logging this in the [advanced tab] n(https://docs.knime.com/latest/db_extension_guide/index.html#advanced_tab) of the DB Connector node you are using. The option is called JDBC logger which then logs all statements send to the database to the KNIME log with debug level.
Regarding the SQL insert statement we haven’t enabled it so far since quite some customers still older Cloudera installations where using the insert statement results in very bad behavior e.g. one data file per inserted row in HDFS. Therefor we recommend to use the DB Loader node for inserting data into Hive and Impala. This node uploads the data first into HDFS and then loads it in one go into the target table which results in much better performance.