Hello all; so I'm new to KNIME, so pardon my ignorance, but I'm working on a computer with 8GB of memory and 8 cores handling a dataset that has 100GB of data. This is a bit of a general question, what is the appropriate way of handling this sort of data? Can filereaders stream this data and process this data in parallel? I suppose I'm trying to get a general feel for the usecases and advantages of KNIME. (and how much of a magic bullet approach this would be)
Hi glenohumorous,
generally speaking, KNIME is able to handle data sets that do not fit into your main memory. It does so by creating temporary files on the hard drive, so this is slower than in-memory processing. My gut feeling is that a ratio of 8:100 GB is not something I would want to work with on a regular basis - but that might depend on your particular use case and on the kind of things you want to do with your dataset. (E.g., extracting a sub-set or just processing the dataset row-wise might be feasible, doing group-by and join might get ugly).
Streaming was recently added to KNIME and might help in your case, but to the best of my knowledge not all nodes support this additional mode (yet).
Hope this helps,
Nils
Hi All,
i have a similar problem, where i have to handle a CSV file of 60gb resulting in a dataset of 246 milj records and about 23 cols. (most of them are text because i’m not yet to the analytical stage)
i’m stuck at a “rule-based row splitter” after a series of concat nodes, throwing me a heap-space / garbage collector (gc) error.
i have already crancked up the heap space to 6gb, not sure if cranking it further would do any good.
-also a regexp split node or a row filter node are not able to chew through the dataset
i have the impression that the number of preceding nodes all add up to the heap, thus giving me the heapspace issue after x-number of nodes, not specifically on the concat / split node combination
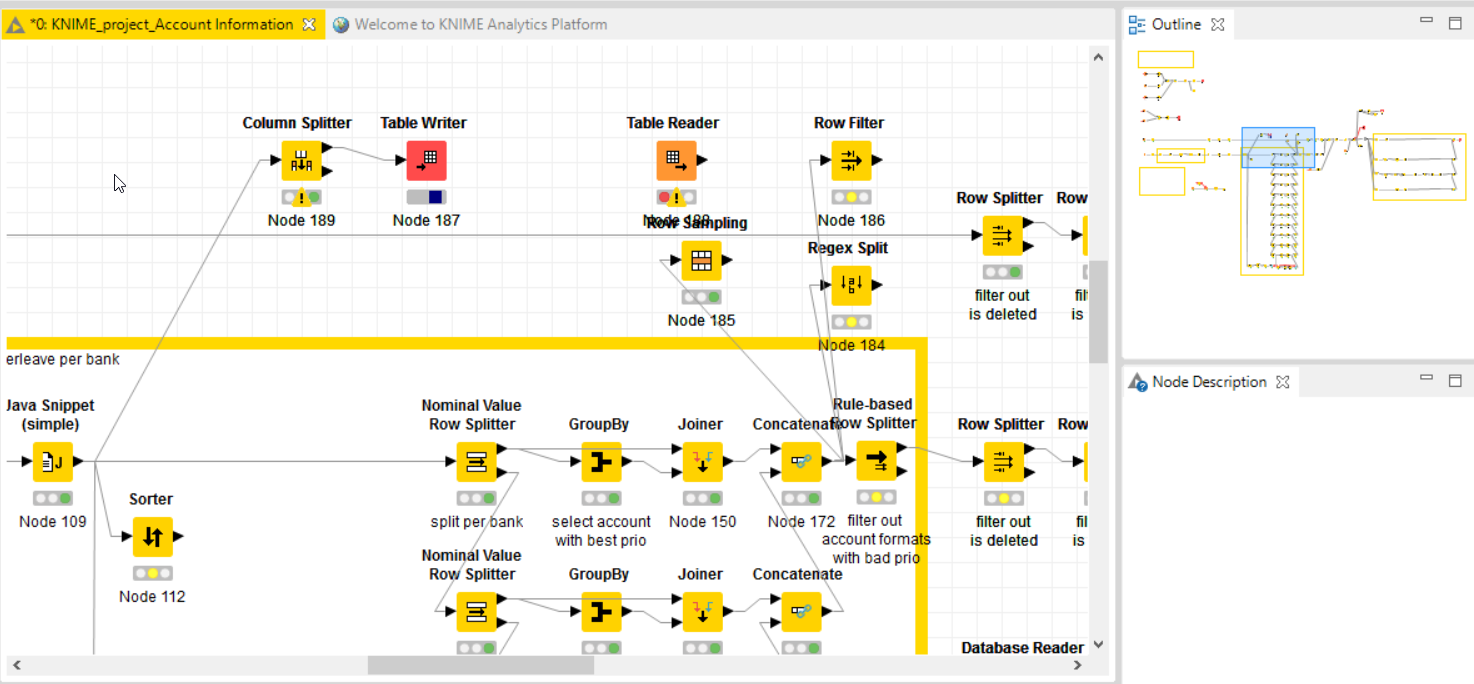
i am trying to chop the preceding steps off, by writing an intermediate dataset (same size) to disk via the table writer; but there it just keeps on running + 12h on-end with 100% cpu and 0 bytes written to the output file…
any idea on how to work around this ? (without having to move the processing steps do a hadoop system)
Thx!!