Hi, i need to know an information. I have a set of clustered data, with several missing value in different feature. I want to calculate for each cluster mean/median of all feature for use them to replace missing values of all istances. Anyone know a method for this?
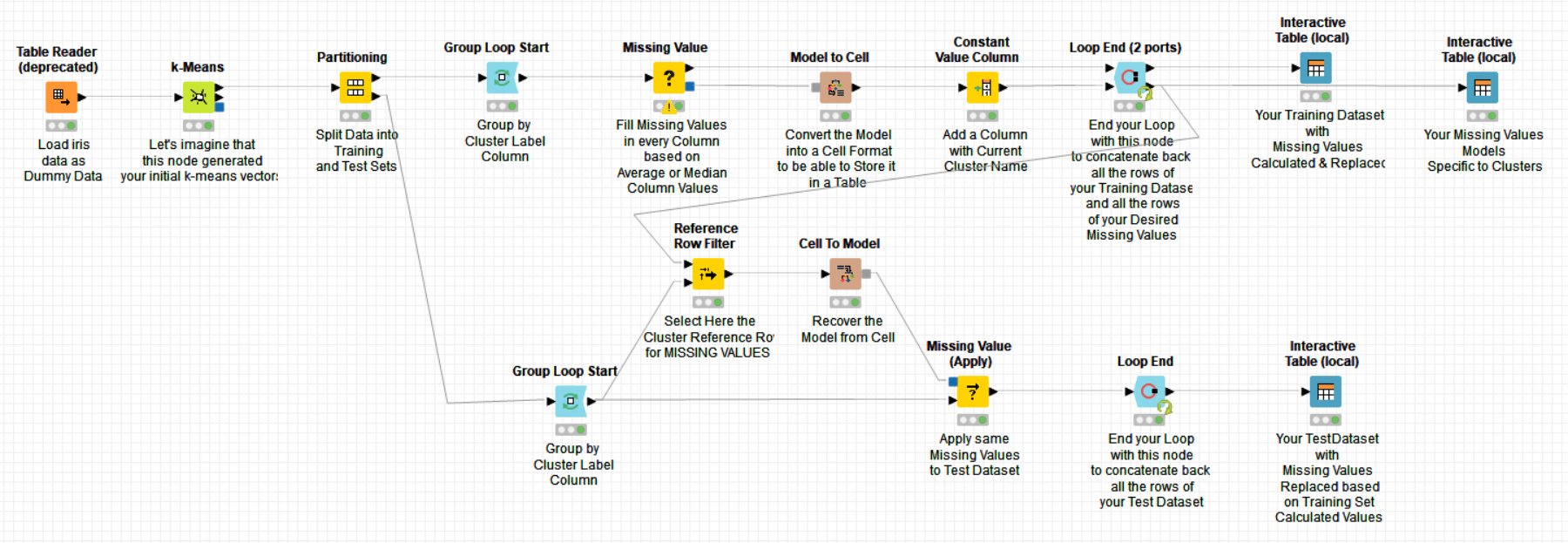
I guess you have a table with for every row data a column with its cluster number or label. If this is the case, you could use a - Group Start Loop - (ended with a generic -Loop End- node) which would select the rows by your different cluster label at each iteration. Inside the loop you could use the -Missing Values- node that can calculate the mean or the average of all the column values which are not missing in a cluster and this for all the columns.
It’s great! it was just what I was looking for! Thank you so much!
Another thing, this method is fine, but when I must manage the missing values of the test set, I cannot include them in this cycle, but I should only apply the management of the missing values (through the missing value (apply) node). In this case, how could I do?
@m1k glad it worked and thanks for your kind comments.
This second question is a bit more involved but what you could do is for each cluster and column determine which was the calculated missing value, keep it in a table and then use this table as a reference table for the missing values in your Test Set. This would be only possible if your Test Set is also tagged with cluster labels from the beginning.
Hope the idea described above is clear enough. If not, please let the forum fellows just know and we will try to help you from here.
@aworker 's solution uses the missing value node which has also an additional ouput port to apply on test data. Maybe you can leverage that output in his second proposal
br
HI @aworker
sorry I have not built one because there was no data provided and also you have already done the “heavy lifting” and provided the solution. Great job, I really enjoy reading your solutions in the forum Kudos
br
@m1k here you have a workflow which should answer your second question. I did not use a set with missing values as reference but if you replace the data set used here by yours with missing values, it should do the job. Otherwise, let us know and we will amend it.
Interesting, thanks for sharing.
Have you tried to apply the missing value output directly to the test data without the looping and compare results?
br
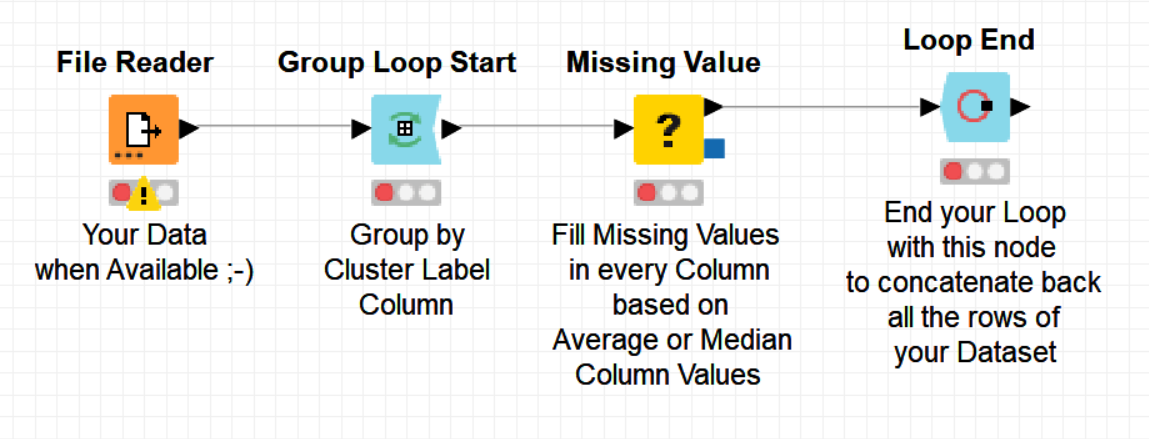
Could you provide with feedback about the second solution I posted ? Did it solve your second question ? Generating missing data distributed over several different columns is a bit cumbersome so I would be grateful if you could share your missing data to verify on the workflow that it does the job as expected.
Imputing missing data with means or medians can be dangerous as it can alter the correlation structure of your data. An alternative would be to use a data analysis method which handles missing data like NIPALS-PCA which is available in the R package pcaMethods (part of bioconductor). This is easily implemented in an R node. NIPALS-PCA purely build models on the available data without imputation. The data however needs to be missing at random rather than in blocks.
It is not the case here because @m1k is calculating the average or the median values of samples within every individual cluster which makes sure that the samples with replaced missing values still remain within the convex hull of every cluster defined by their K-Means in the space of the descriptors. In other words, samples still remain within the space delimited by their assigned clusters.

 ?
?
 !
!