Background: I am trying to use the Guided Labeling for Document Classification on my own dataset, which includes some larger documents scrapped and captured in CSV files (as compared to the small movie reviews coming witht the example) No other changes to the workflow has been made.
When running the process as is, I get a heap size error in the last node (Deploy). I have 32 GB physical memory on my Windows 10 machine, but even if I set the heap size to 8 or 16 GB and select to save table to disk in the memory policy of the various nodes, I still get a heap size error. And when I ramp the heap size up all the way to 28, 30 or more GB, instead of a heap error and after about 5 minutes KNIME just crashes and exits without any error messages.
Any help with this matter would be greatly appreciated.
hi @petervk,
sorry for the few days delay regarding this workflow here below.
The java heap space is due the interactivity of the tag clouds.
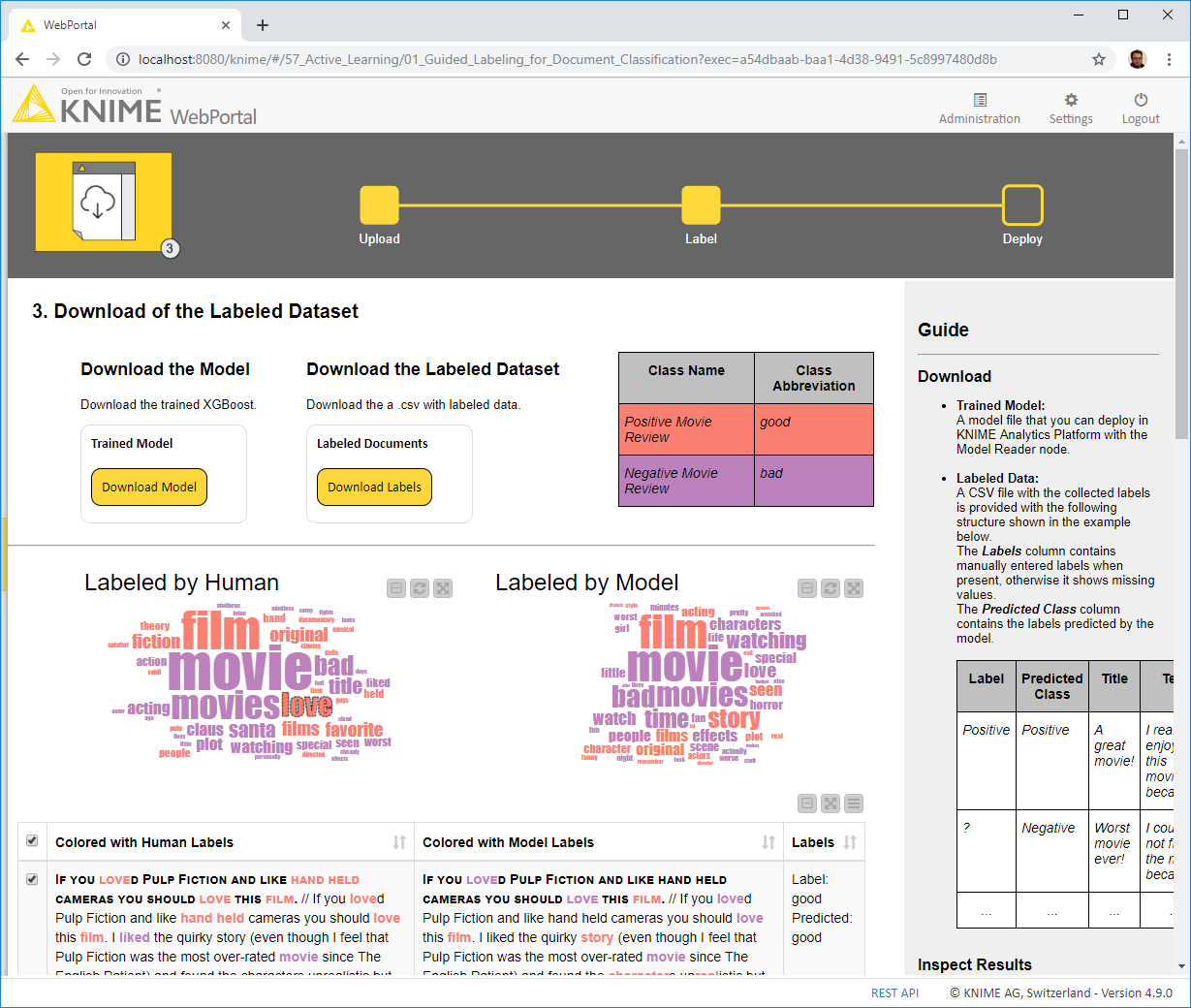
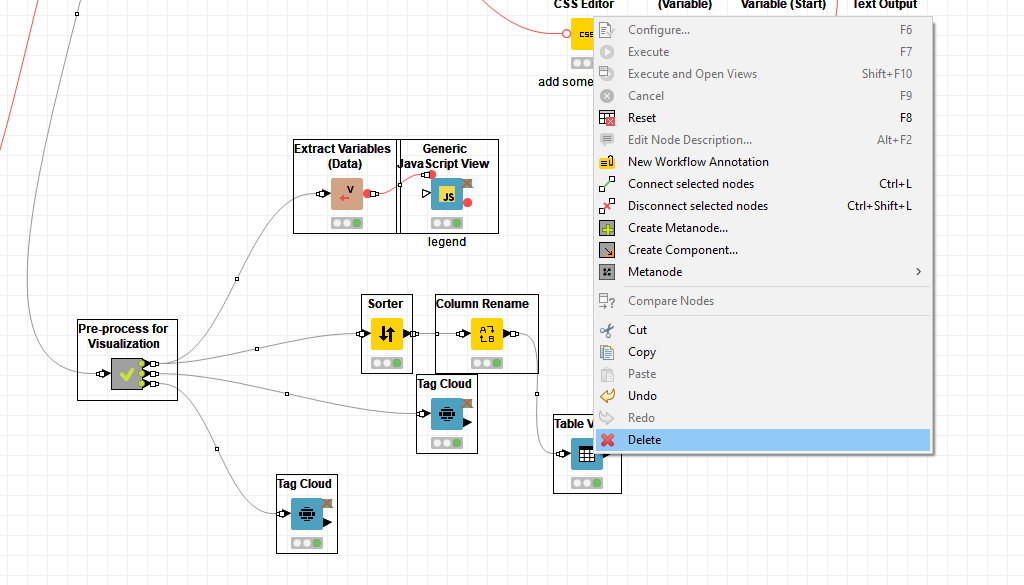
Basically in the final page of the application you can have two tag clouds: one based on the human labeling and one based on the model labeling.
When selecting a term in either tag cloud (in the image above “love” is selected) a table below fetches the documents using this term and highlights where the term is used. This gives you a quick inspection when comparing how the human-in-the-loop labeled rows and how the model did.
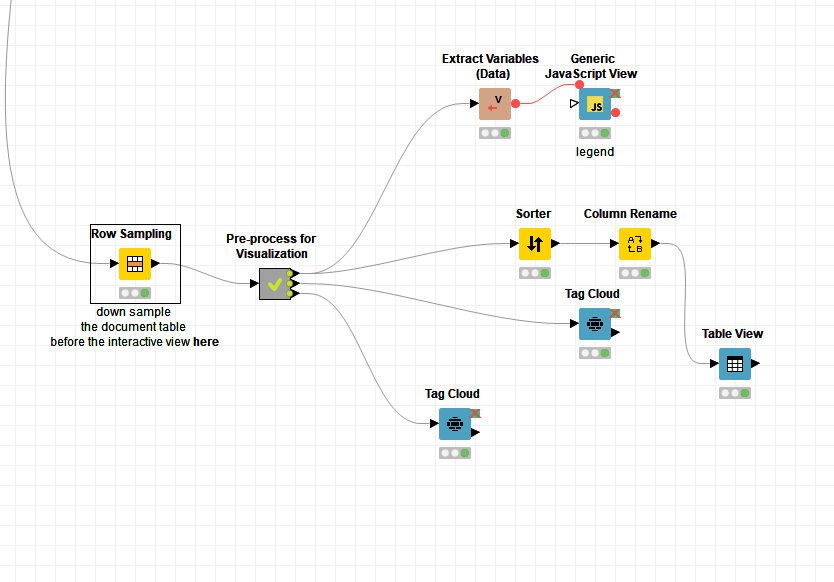
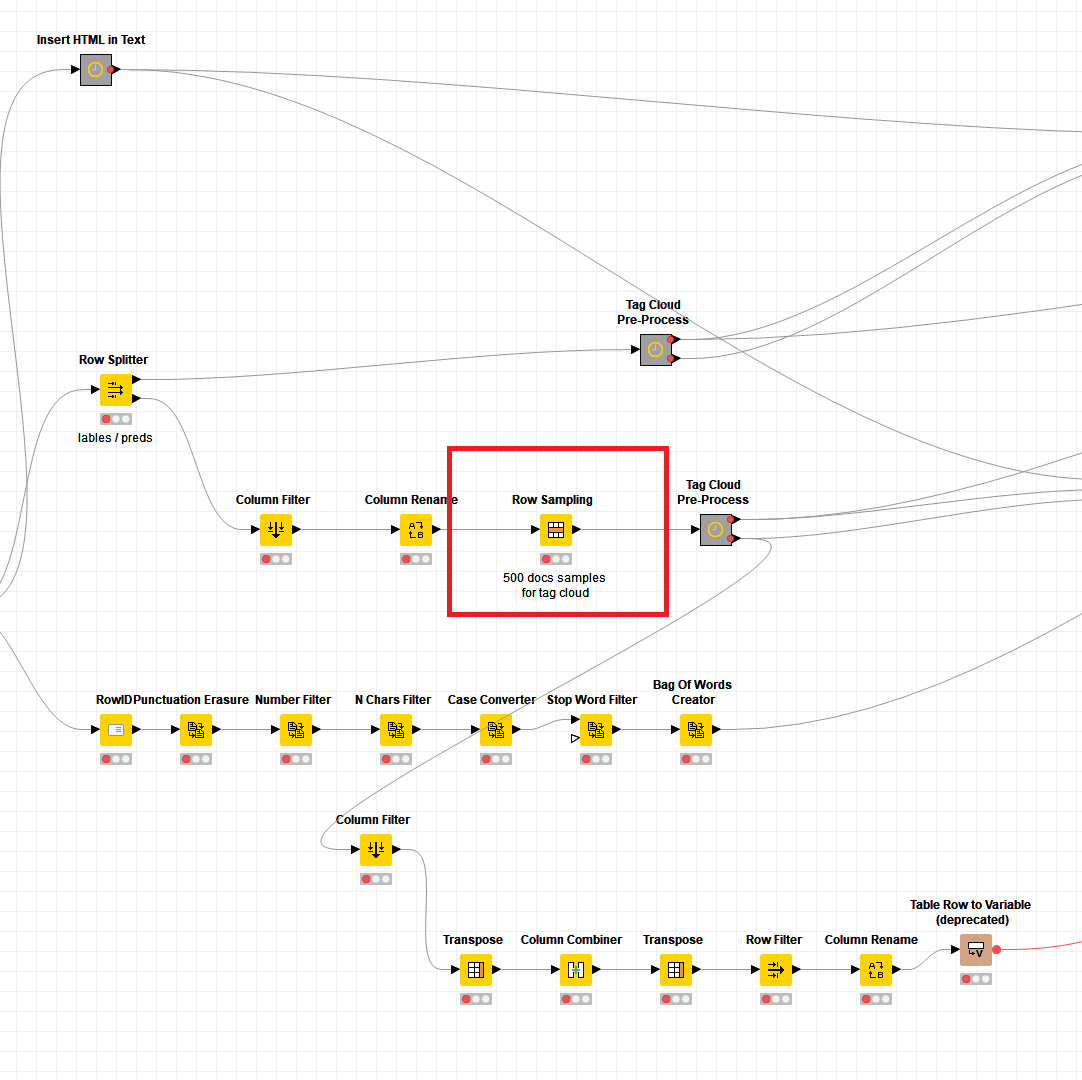
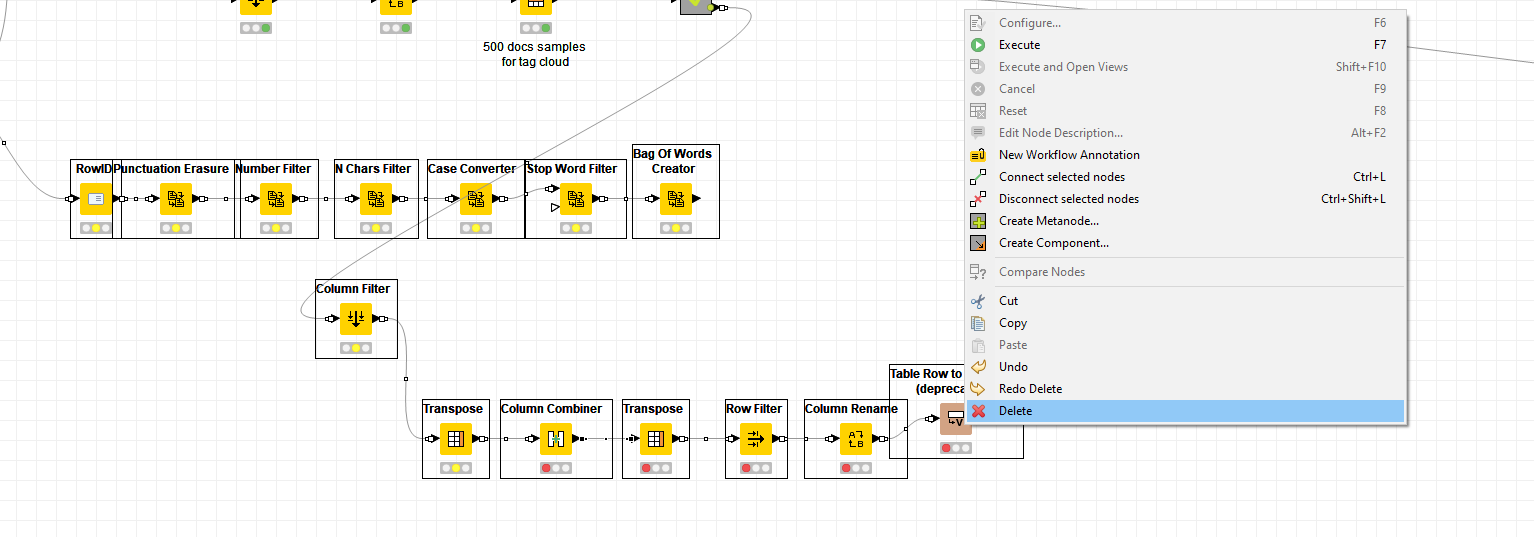
To make this possible in the Component “Deploy” and inside the metanode “Pre-process for Visualization” we link the table of terms with the table of documents by overpopulating the table of documents. This means if a document has 30 terms showing in the tag cloud it will show in the document table 30 times. This is done only for the sake of the interactivity.
The interactivity requirements increase then the size of the data quite a bit and it is probably what breaks your workflow. To avoid this you can try any of the options below:
Decrease the number of displayed documents in the view by adding a Row Sampling here. The smaller the value, the longer your documents are.
If you want to limit only the number of unlabeled documents (labeled by the model but by the human) you can use the available node already in the metanode currently set to 500.