I need help; what am I doing wrong, or what data or kind of data does it require?
It would be helpful if anyone could demo it in the workflow with any data.
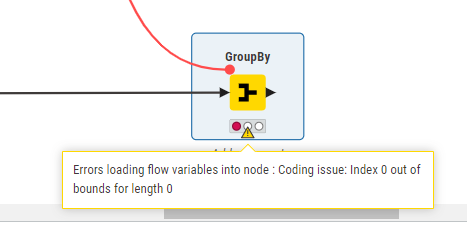
The below GroupBy is working fine and doing its job. I want the same result but with the use of variables.
I just need to know how to configure upper GroupBy with the use of variables and get the same result. I know it can be done. Just don’t know what the specifics of GroupBy when working with the flow variable tab.
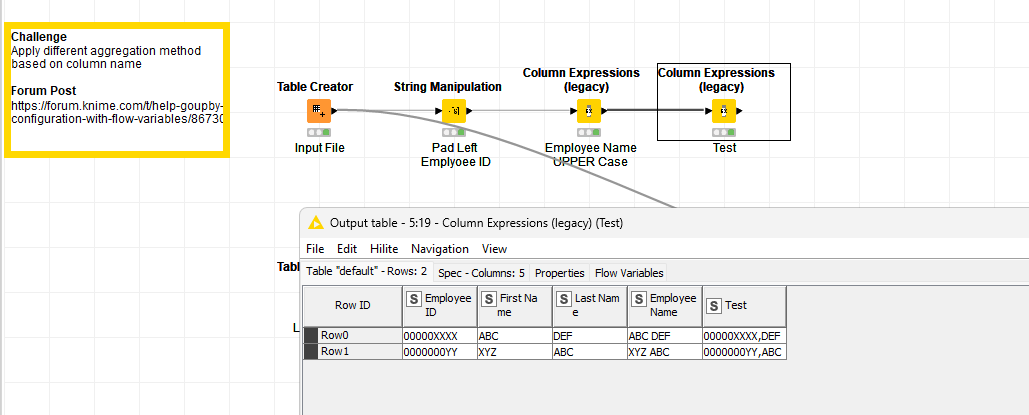
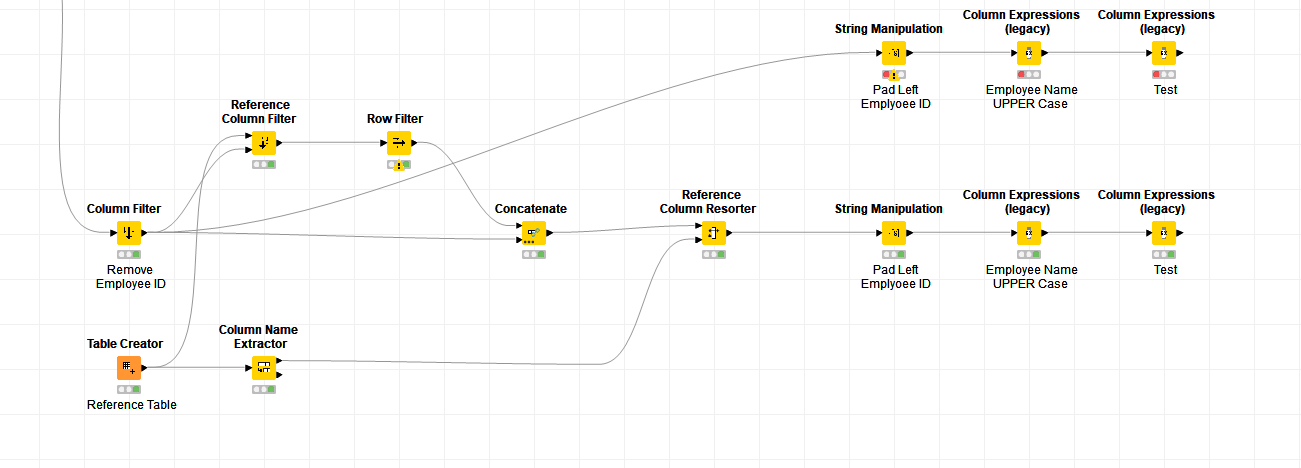
JOIN and PAD have already been achieved till Loop End. I am checking the workflow @mwiegand you’ve provide this might help.
@mwiegand I checked the flow I want that GroupBy that is working (in the flow you have shared). But I want to configure it with variables and should work in that way.
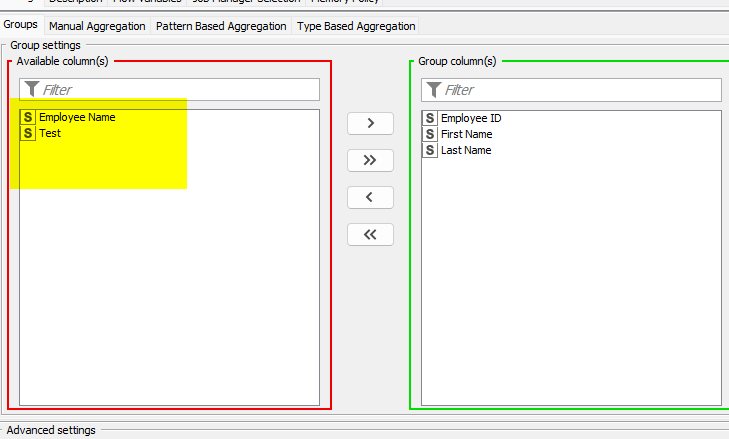
The whole point here is the below column I cannot hard code; these might be there or will not depending on how the user configures the Logic File. It might be the case there will be new columns, and that is why I want to have it in variables.