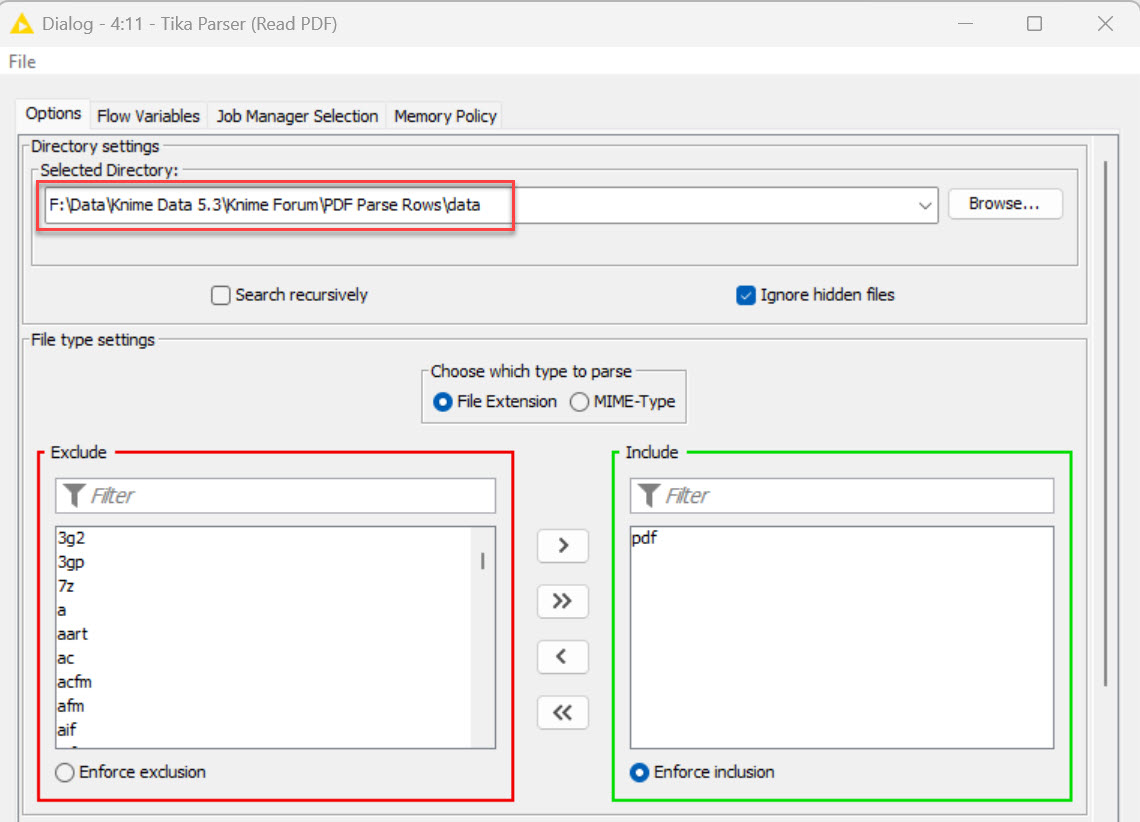
Hi all,
My first post. I have PDF for construction specification. The PDF lists the spec numbers like this “11 04 22”. I’d like KNIME to read the PDF and extract similar strings.
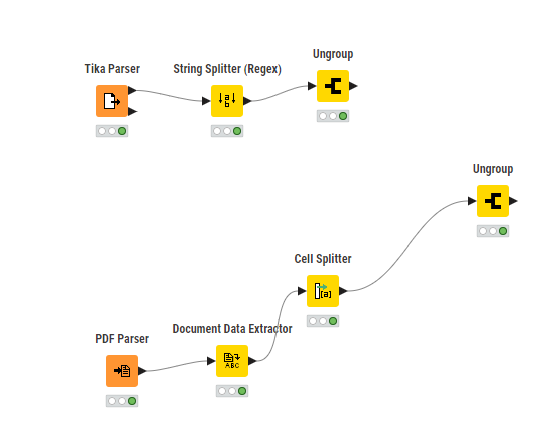
So far, this is what I have tried:
The top approach in the screenshot above gives me only one string.
The bottom approach splits the string “11 04 22” into three rows:
11
04
22
Which is not what I want.
Can anyone please help me!
Thank you.
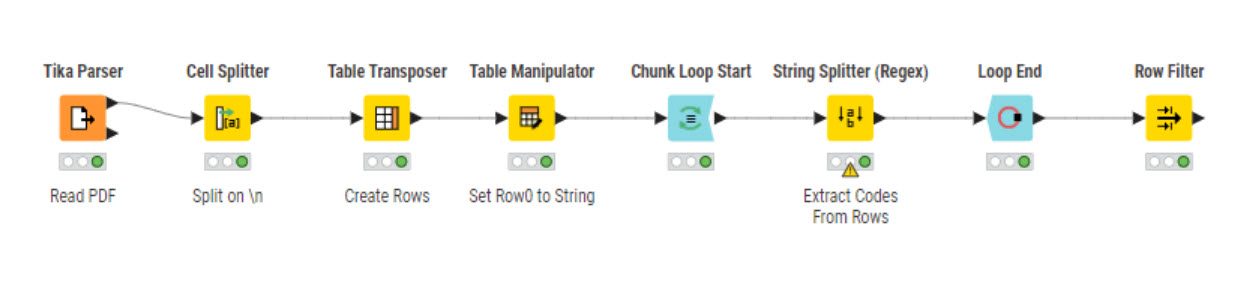
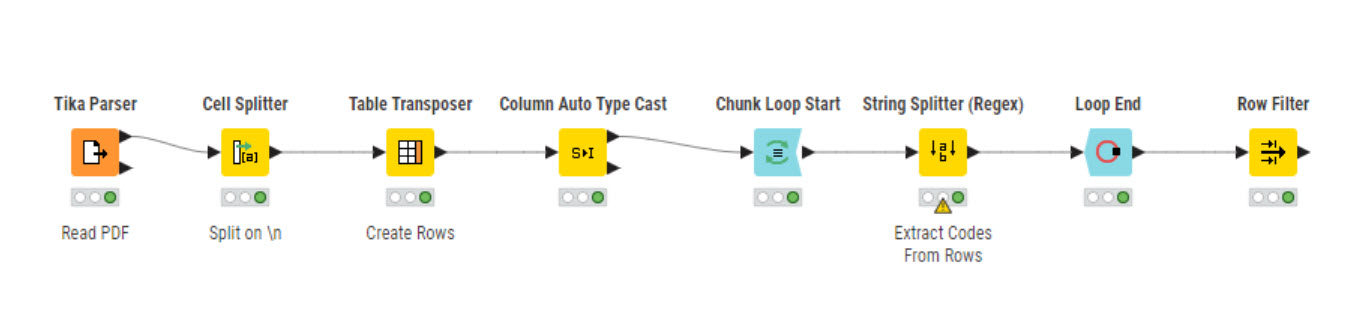
It would be easier for someone to help if you could share your workflow. Make sure to include the pdf(s) with the workflow. In the meantime try using a chunk loop after the Tika Parser.
Hi rfeigel,
Adding chunk loop after Tika gave the same results. I found the best solution is to convert the pdf to excel sheet but this means that I have to do additional cleanups before I import into KNIME.
Not sure if you can see the screenshots above but is there another workflow you want me to share?
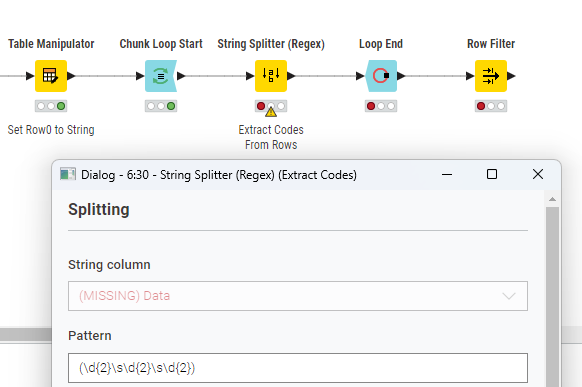
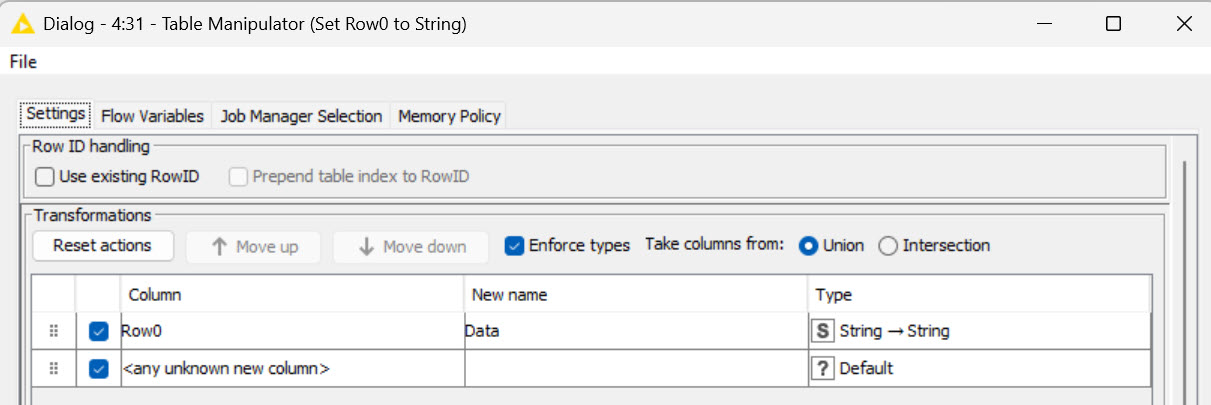
This is strange, for Row0, there is no option to change the type to String. I deleted the Table Manipulator node and inserted a new one but still refuses to show me String. Any idea why?
Are you trying to parse a different pdf than the one you originally posted? If so, please post. Did you make changes to my workflow? Here’s a workflow using the Column Auto Type Cast node which "automatically’ converts non-native data formats.
I don’t have a good explanation. The problem happens in the Table Transposer node. I have seen this before. The node doesn’t always seem “smart enough” to assign a data type to the transposed column(s). Adding the Column Auto Type Cast node downstream has always fixed the problem for me. So don’t worry about it.
Ok. Thank you very much for sticking with me to the end and finding a solution. I did a test and converted a word document to pdf and your workflow worked flawlessly!!