Hi @knimedt
Welcome to the KNIME forum.
You can achieve this by using a Column Rename (Regex) node. Simple use [\n\r\t] and it will clean-up all your columns (keep Replace empty).
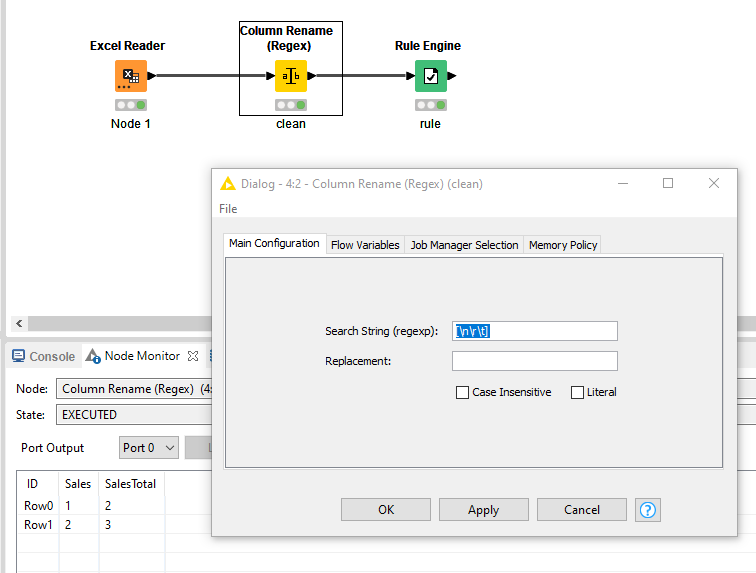
Before:
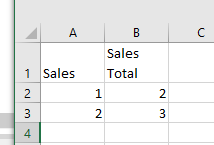
After:
Hi @knimedt
Welcome to the KNIME forum.
You can achieve this by using a Column Rename (Regex) node. Simple use [\n\r\t] and it will clean-up all your columns (keep Replace empty).
Before:
After: