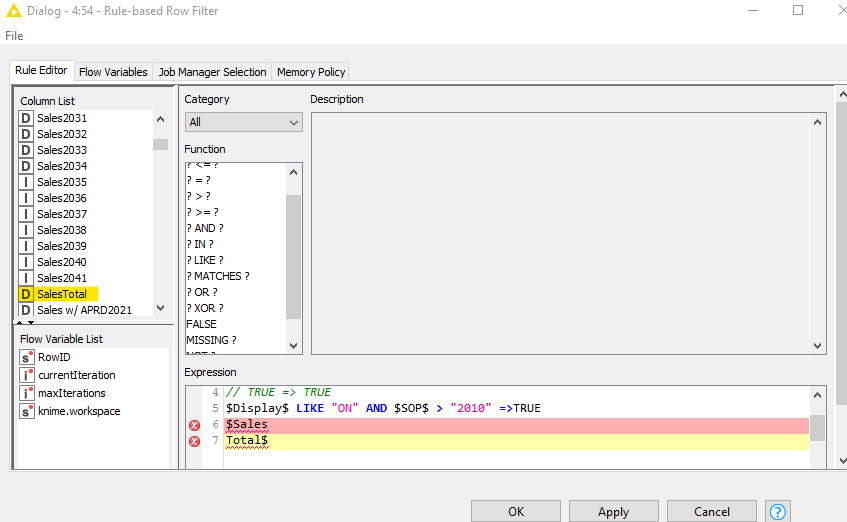
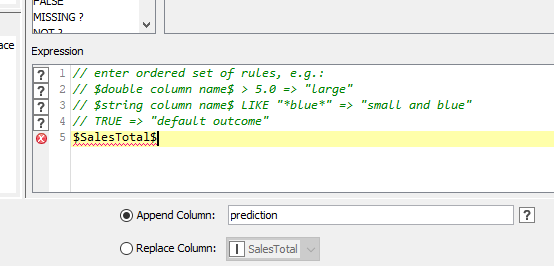
I am having trouble with the syntax/expression in Rule-based Row Filter node. My source file (excel) column has a line break in it, therefore I am getting an syntax/expression error while refering to that column.
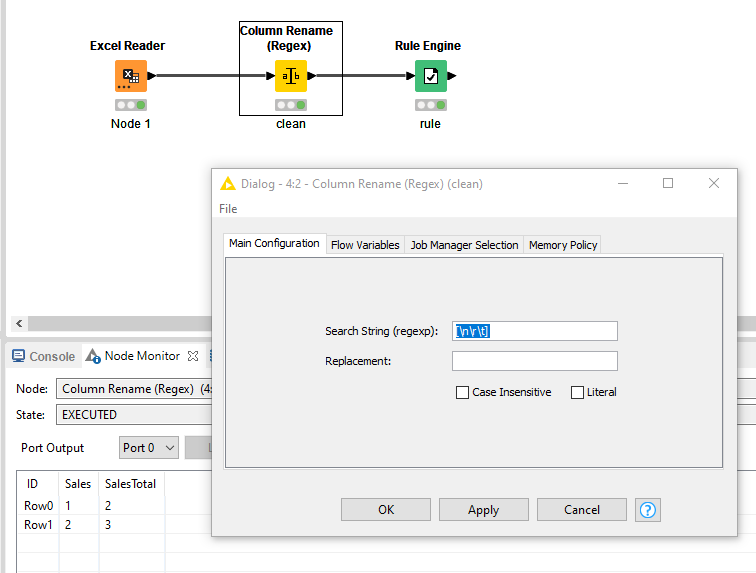
@knimedt welcome to the KNIME forum. You could try and clean your column names before using them. You use a regex with ‘allowed’ chacaters (you might have to add special cases like “/” if you want to keep them in your case) and remove all others:
Thanks @knimedt for posting this interesting question and welcome to the KNIME forum community.
Thanks @mlauber71 & @ArjenEX for your neat and complementary solutions !
@ArjenEX this is the first time I see a -Column Rename (Regex)- node where the “Replacement” field is left empty (instead of using $1 $2 …) and it works !
Is there any place where this option is documented ? Is this something inherent to regex or rather a -Column Rename (Regex)- node KNIME feature ?
To my knowledge, this node has full Regex capability.
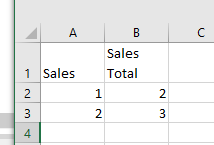
Practically speaking, I believe it’s basically doing regexReplace($Column Name$,"[^\\n\\r\\t ]","") as @mlauber71 also showed in his solution but without requiring any additional nodes.
The way I have been using it is for this exact cleansing purpose or to added prefixes to equally named columns in different data streams so that I recognize the source more easily after doing joiner operations (using the $1 etc.)
Great it hear! Please mark it as solution so that other users can also benefit from this in the future
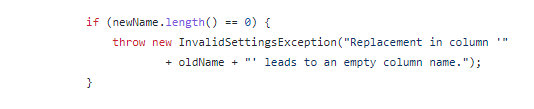
@aworker If you are really tired of your job you can always check the sourcecode of the node what is going on and reverse engineer the requirements a bit, assumingly you can navigate your way through Java.
Note: also approachable by the Find Source button at the bottom of the NodePit page and go to the correct .java file.
In this case, the only requirement I see for the replacement is that after processing the set string, the new column name cannot be empty. Next to the usual IndexOutOfBoundsException catch.
@ArjenEX you solution is very elegant thank you for that I would like to point to one characteristic of my solution that might be interesting if you have to deal with very messy data (headers) often. It allows you to define which characters are allowed and would throw out all the rest. So @knimedt if your source would come up with other funny characters they would also get removed.