Hello everyone,
I am quite new to KNIME and would like to scrape a website to retrieve a list of items which are unrelated in the HTML structure but need to be related into a table.
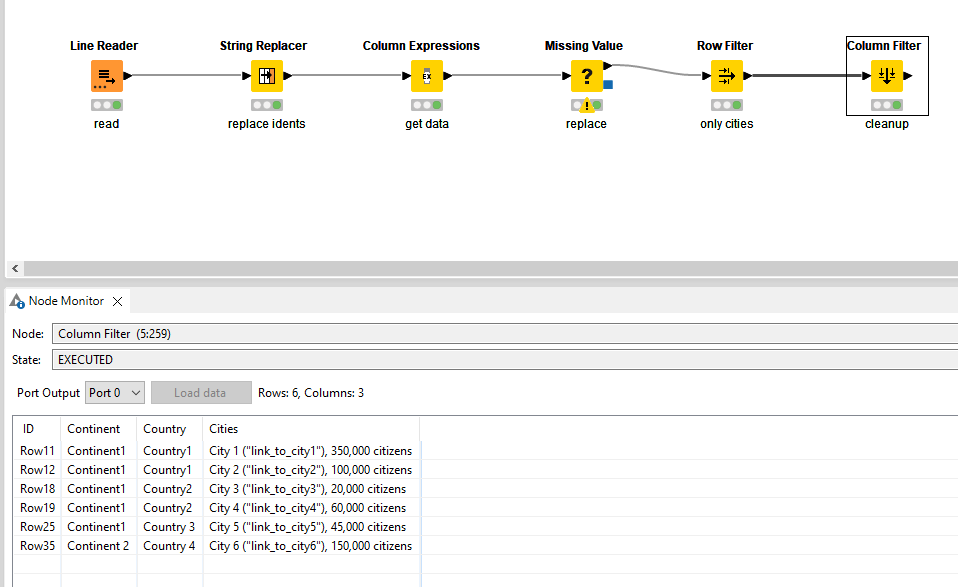
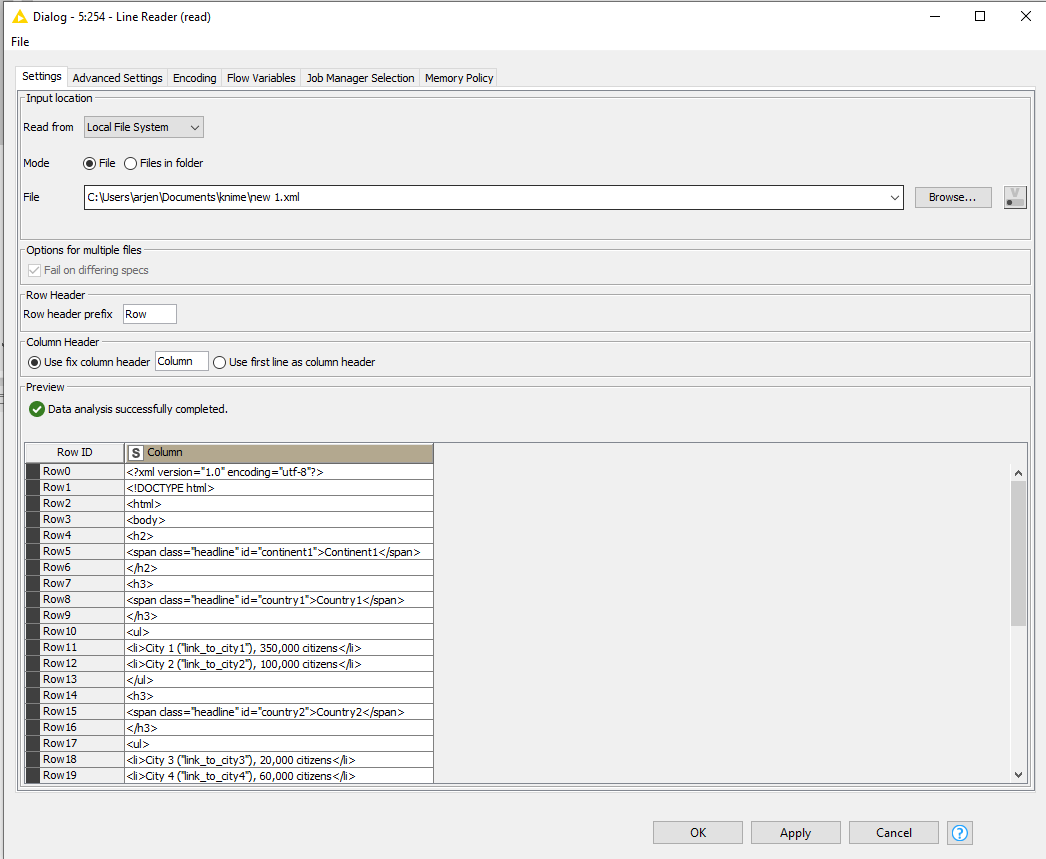
I have the following XML generated by the Webpage retriever node (cleaned it for clarity):
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html>
<html>
<body>
<h2>
<span class="headline" id="continent1">Continent1</span>
</h2>
<h3>
<span class="headline" id="country1">Country1</span>
</h3>
<ul>
<li>City 1 ("link_to_city1"), 350,000 citizens</li>
<li>City 2 ("link_to_city2"), 100,000 citizens</li>
</ul>
<h3>
<span class="headline" id="country2">Country2</span>
</h3>
<ul>
<li>City 3 ("link_to_city3"), 20,000 citizens</li>
<li>City 4 ("link_to_city4"), 60,000 citizens</li>
</ul>
<h3>
<span class="headline" id="country3">Country 3</span>
</h3>
<ul>
<li>City 5 ("link_to_city5"), 45,000 citizens
</li>
</ul>
<h2>
<span class="headline" id="continent2">Continent 2</span>
</h2>
<h3>
<span class="headline" id="country6">Country 4</span>
</h3>
<ul>
<li>City 6 ("link_to_city6"), 150,000 citizens</li>
</ul>
</body>
</html>
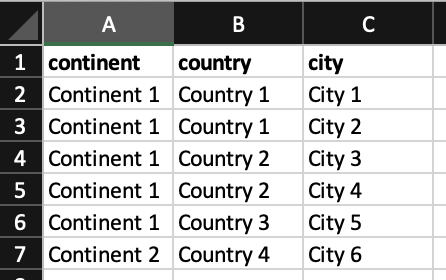
I would like to retrieve the continents, the countries and the cities into 1 table like below:
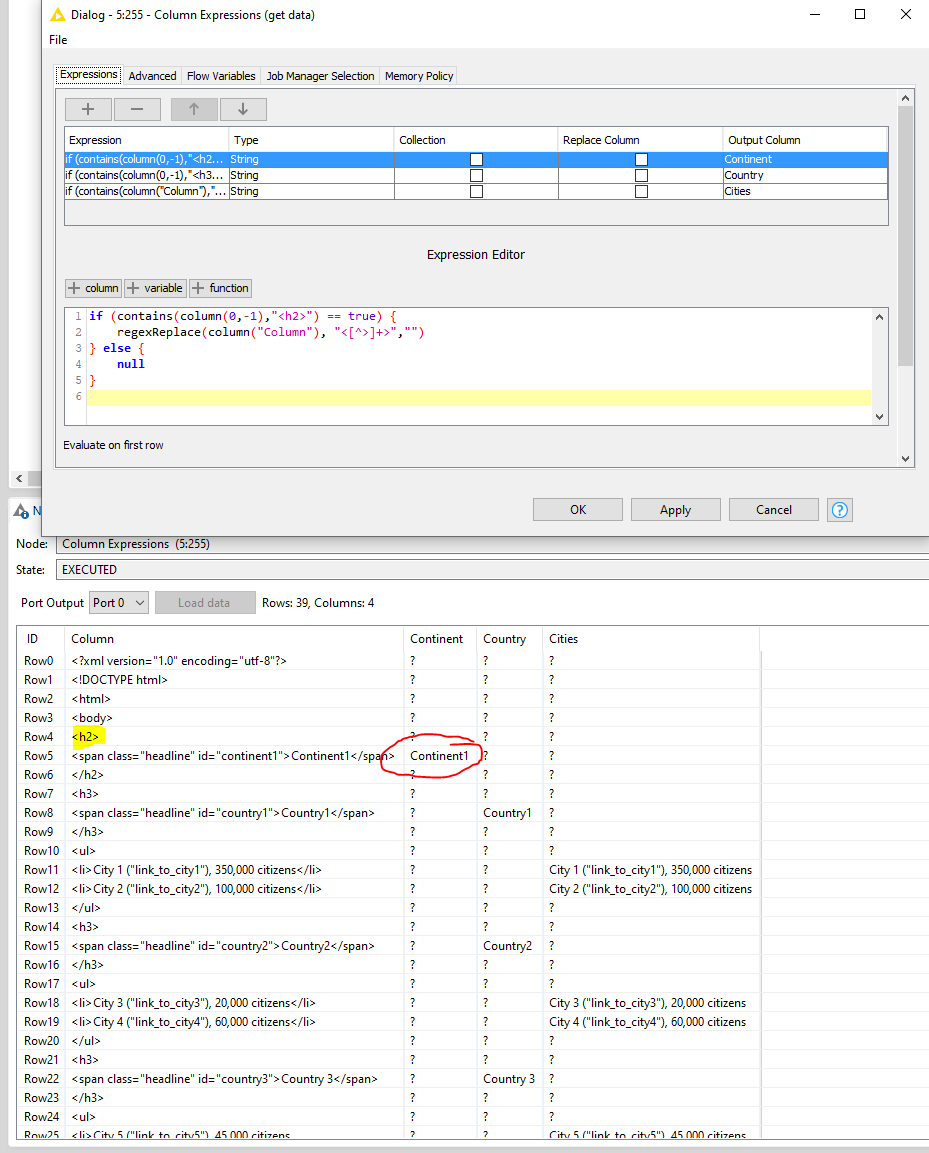
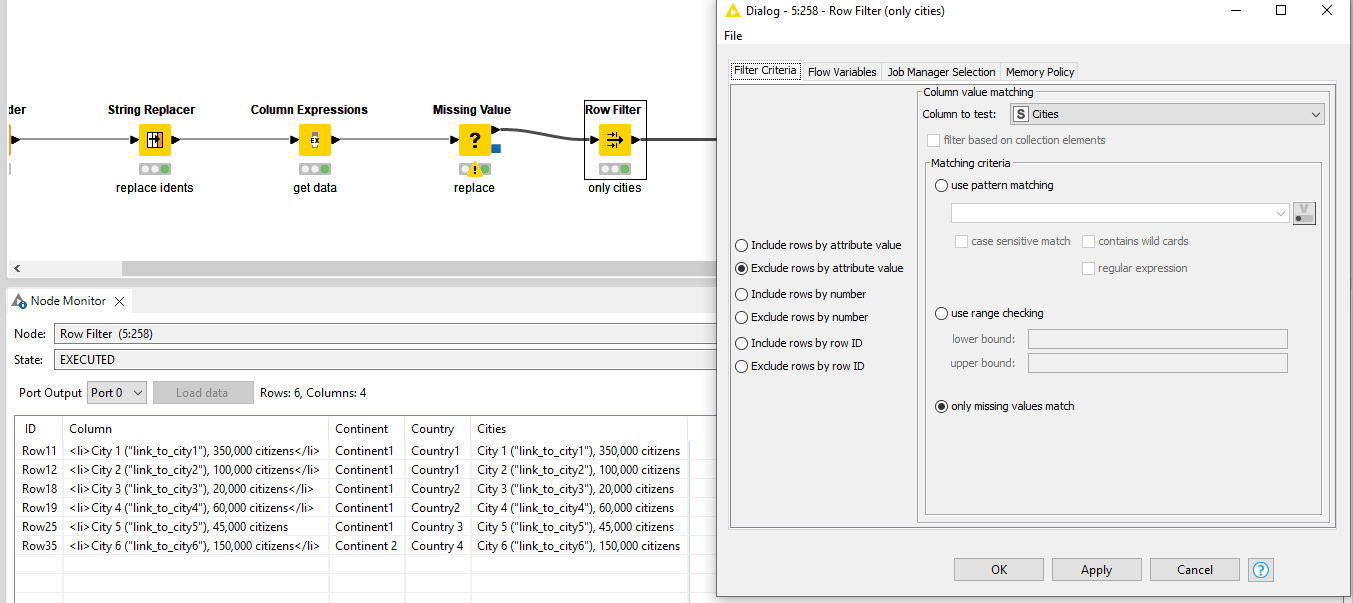
Unfortunately there is not a real hierarchy in the HTML structure so I cannot detect if city is related to a certain country and if country is related to a certain continent, other than by sequentially going through every record perhaps. However, from what I understand, HTML parsing using RegEx is not recommended and I see people recommending using XPath node instead.
Having read XPath syntax documentation, I feel it should be possible using the right XPath expression to get the data correctly our of the document.
However, I am not an expert on XPath syntax so would be interested to see if anyone has some suggestions to tackle this challenge.
<h2> contains the continent level, <h3> contains the country level and the <li> tags contains all the cities.
Many thanks in advance,
Rob