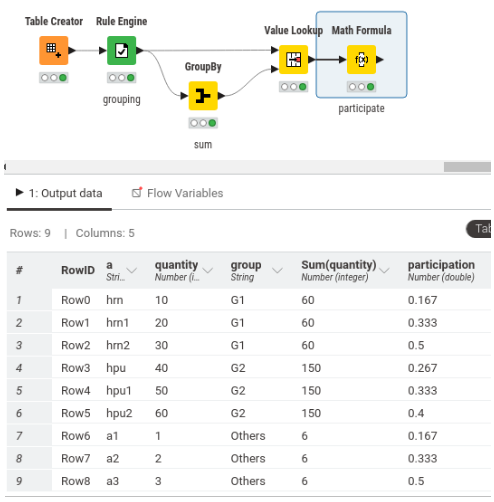
I am working on a data analysis project and need some assistance with calculating the participation of values within different groups in my dataset. Here’s an overview of my challenge:
I have a dataset with two columns: “A” and “Quantity”. Column “A” contains values like hrn, hrn1, hrn2, hpu, hpu1, hpu2, and the “Quantity” column has corresponding numerical values (e.g., {10, 20, 30, 40, 50, 60}).
What I need to do is create a third column, “Participation”, which calculates the participation of each value in its respective group. The grouping is based on the prefix of the values in column “A”. For example, values starting with “hrn” belong to one group (let’s call it G1), and those starting with “hpu” belong to another group (G2). It’s important to note that there could be an undefined number of such groups, not just two.
The calculation should be like this:
- sum_hrn = sum of quantities for
hrn,hrn1,hrn2 - sum_hpu = sum of quantities for
hpu,hpu1,hpu2
The “Participation” column should then show each value’s participation within its group, calculated as value/sum_of_group.
Could anyone guide me on how to achieve this in KNIME? Any advice on nodes and workflow strategies to use would be greatly appreciated.
Thank you in advance for your help!