----------------------Tried--------------------------------
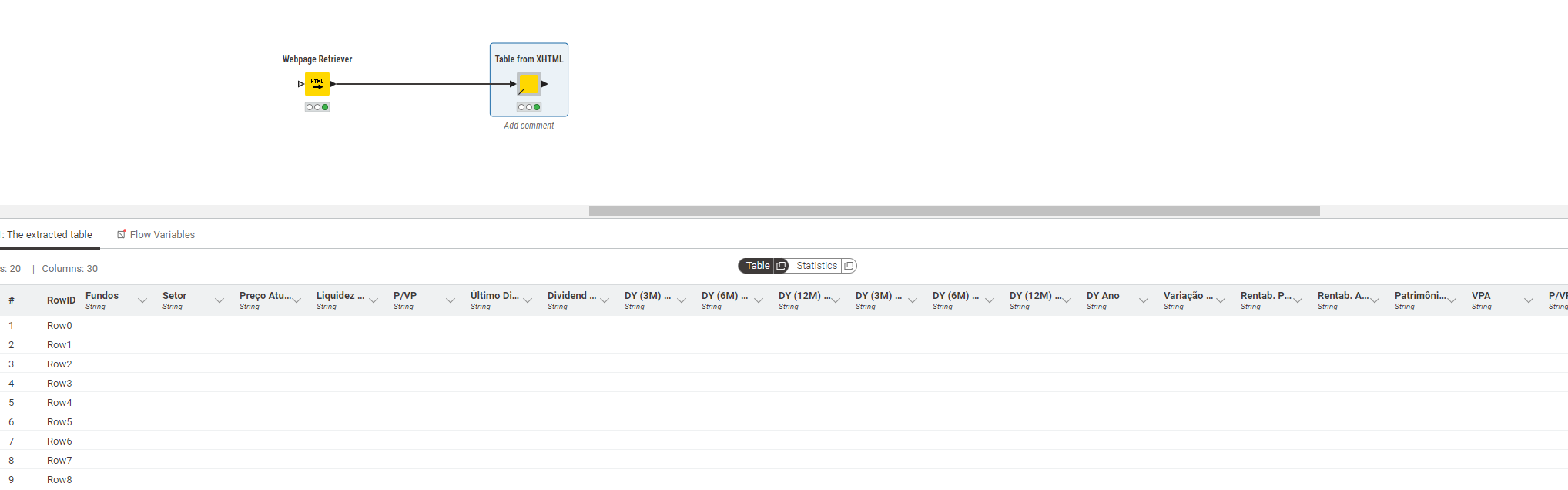
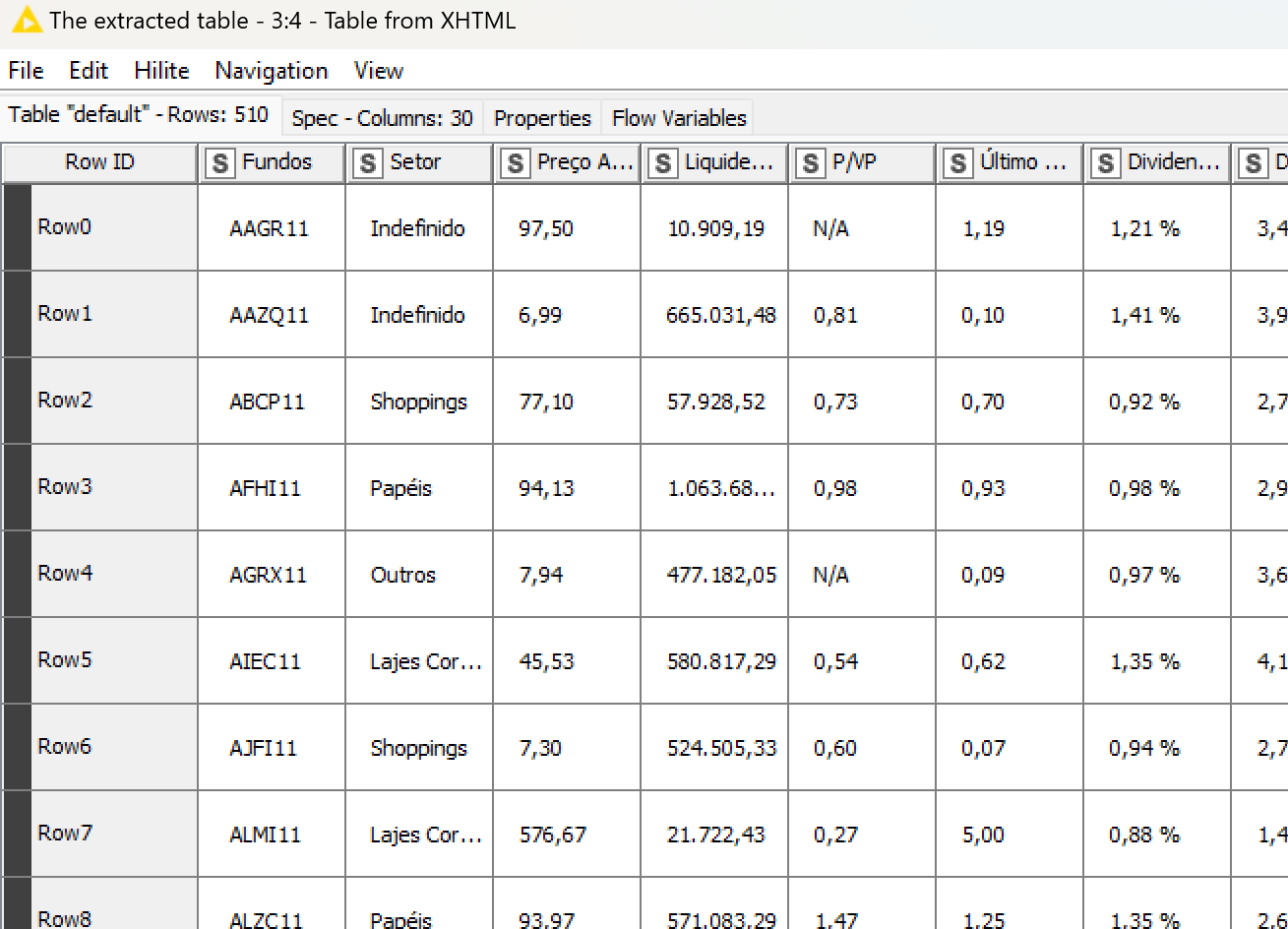
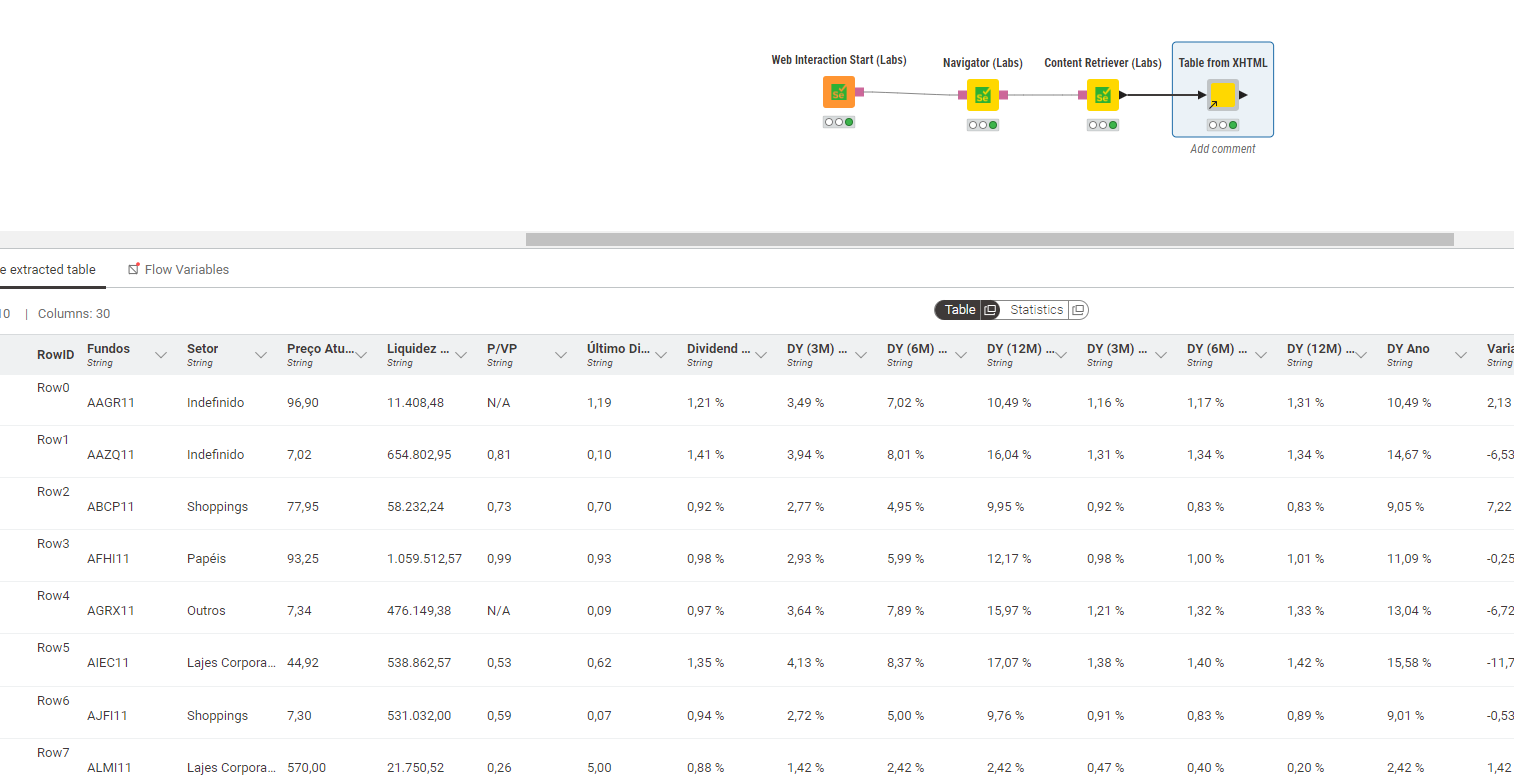
I tried using this component “Table from XHTML,” but it did not return the table.
I believe I would need to customize it.
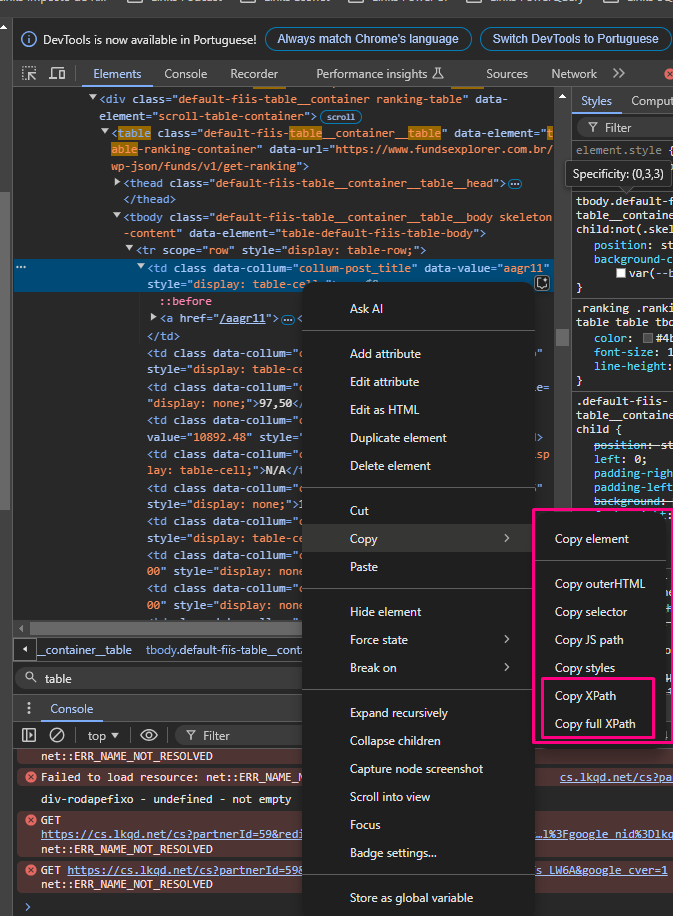
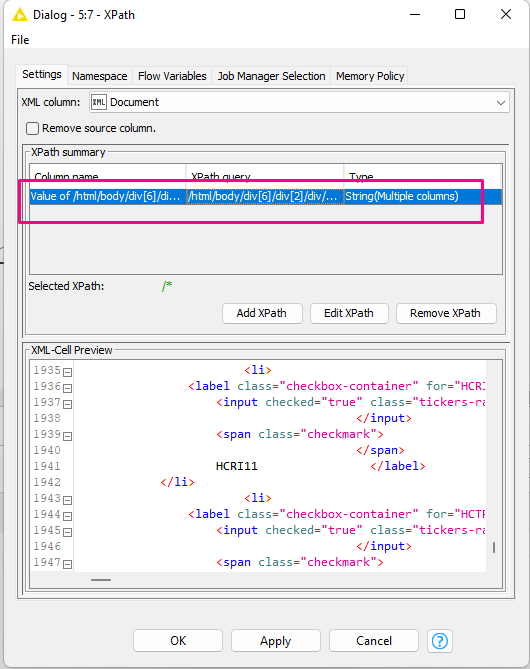
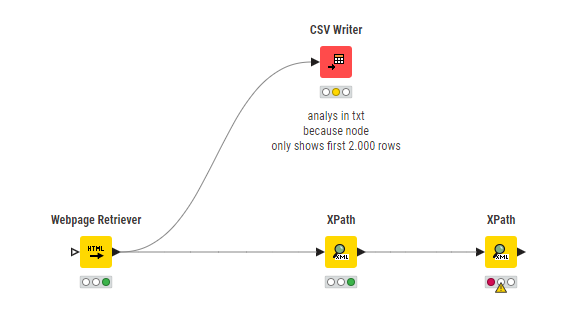
---------------My Experience with Xpath----------------- I have a little experience with Xpath from reading XML. I’ve created this workflow and achieved the desired result. But with HTML I’m lost.
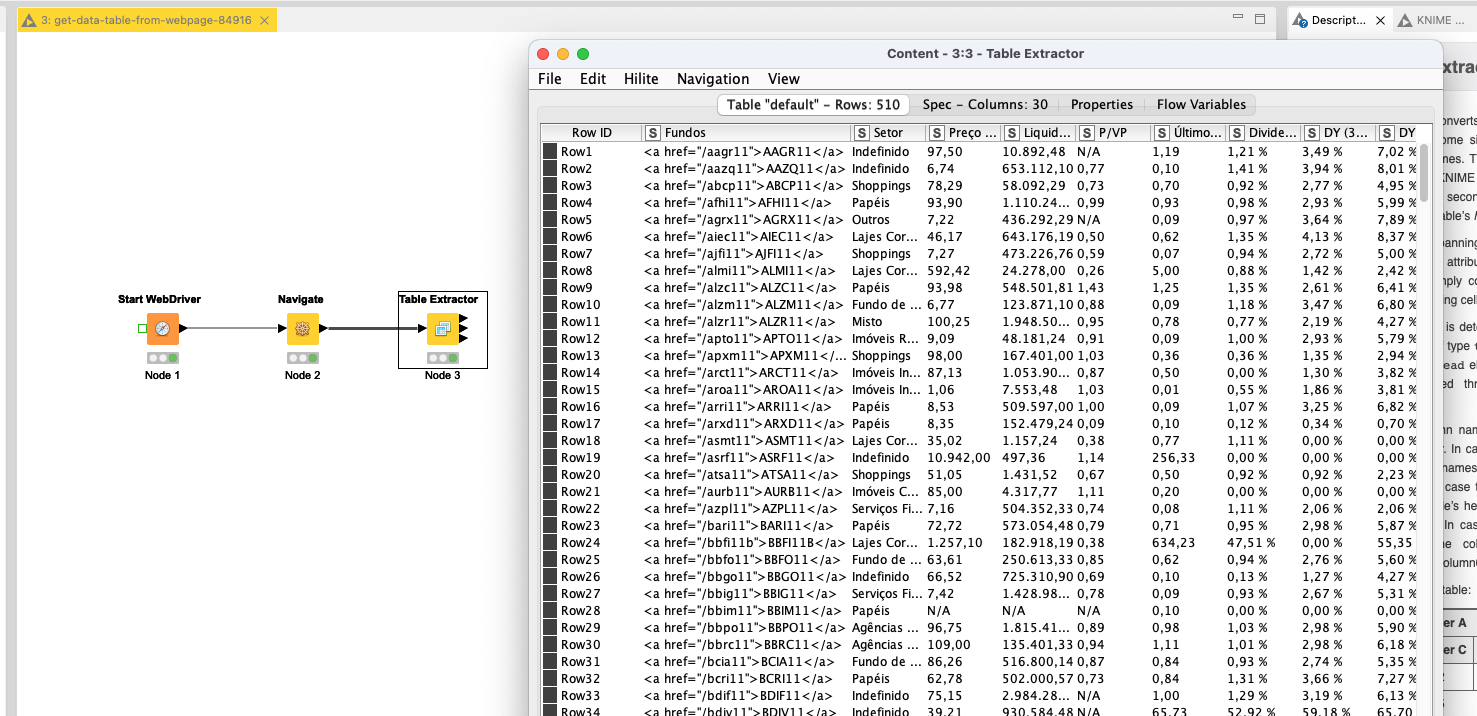
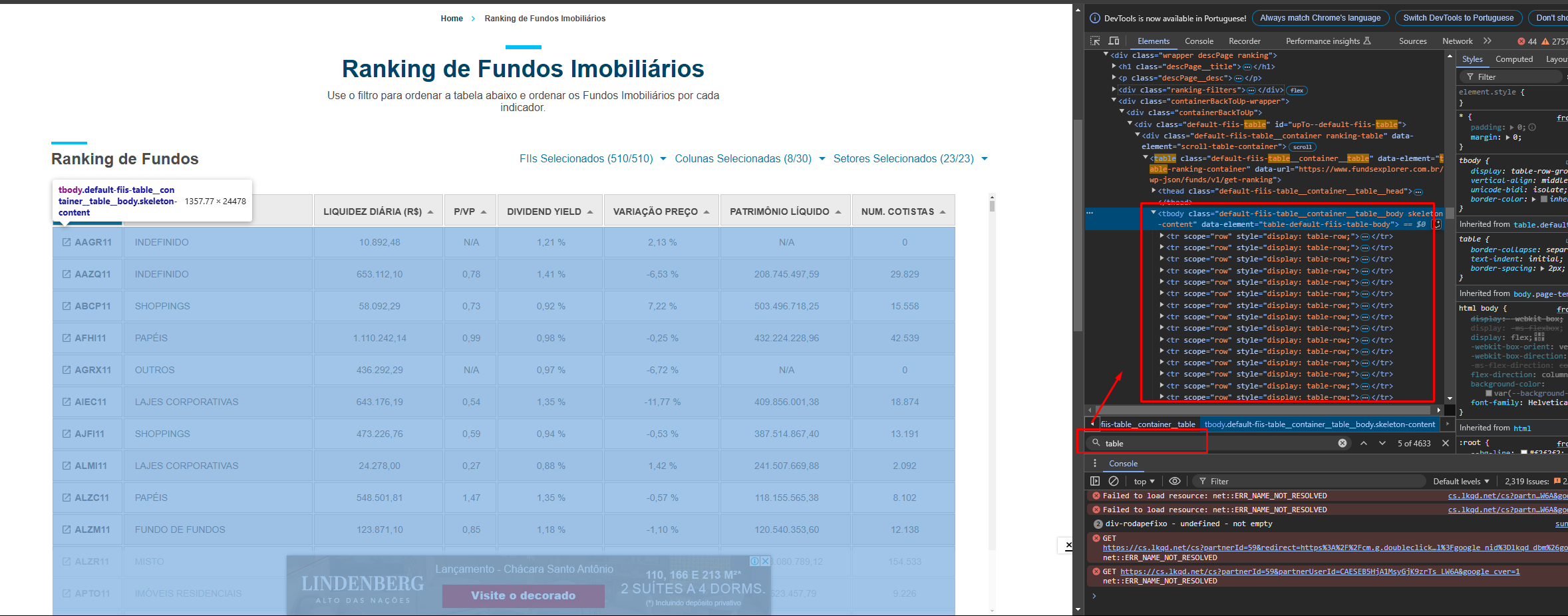
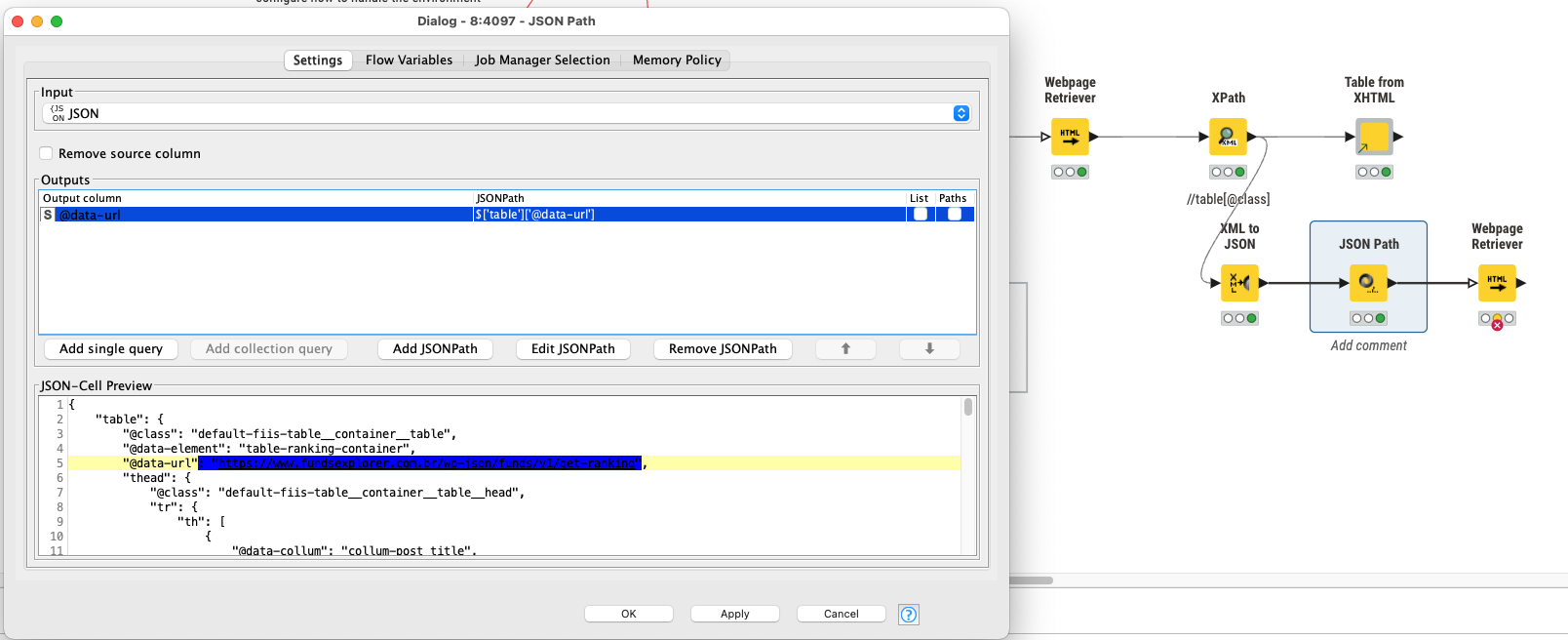
@Felipereis50 the nodes do work although there is a problem that the website does not seem to provide the numbers under certain circumstances. So the cell are always empty.
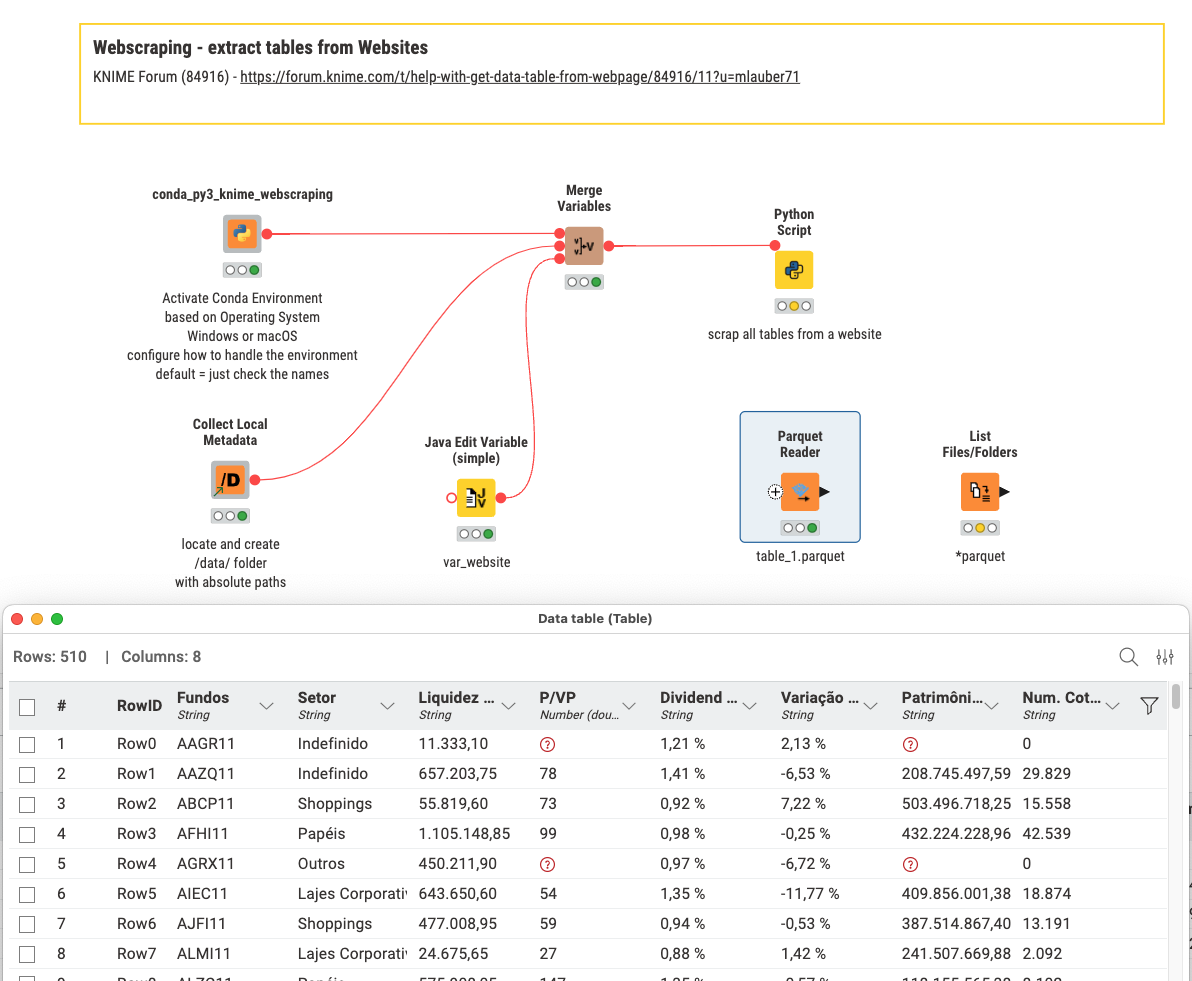
Here is a Python code trying to deal with that. It is built so as to extract all tables into Parquet files in a directory you can specify.
I tried starting the installation of CONDA, but I couldn’t do it.
I’m using a corporate computer, and there are restrictions on installing programs.
I won’t be able to complete it.
Based on your analysis, Xpath wouldn’t be ideal, correct?
I searched on YouTube and found some tutorials on how to perform web scraping, specifically for the site I mentioned, and I only found examples using Python.
Many of them use Python libraries. (Beautiful soup)
Perhaps I could replicate it using Python Node based on the tutorial, but if I need to install any library on my computer, I won’t be able to proceed.
In any case, if I can’t manage it, I’ll have to resort to using Power BI as a source to capture the table.
Thank you in advance, and I’ll consider the thread closed.
@Felipereis50 having the ability to install software (namely Python) might be crucial to actually using analytics tools. In this case the Webpage Retrieval and so on do work in principal, but the data itself seems to be dynamically provided by some sort of sub-page which is not in itself accessible.
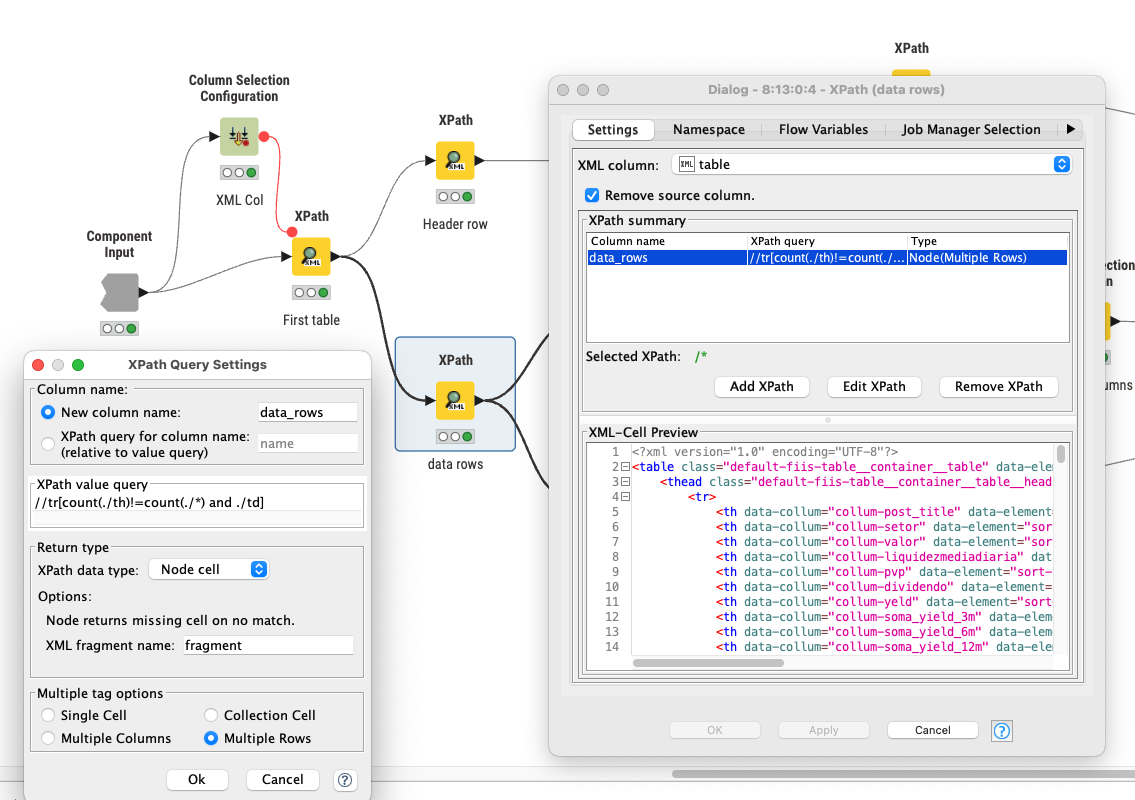
The " Table from XHTML" component does search for the (first) table element //table[1] and then for the data rows and so on if they are there. The path syntax can be somewhat confusing first but with a little trial and error you can manage … given that the data is actually there in the retrieved html/xml document.