Greetings. I am trying to partition over 2 million rows of data into groups of 100’s. The straightforward way I know how is to use the Partitioning nodes (as shown in the attached screenshot), but because my data is huge, it would mean I’ll have to do it more than 20k times! Is there any way I can do this efficiently?
Thank you. I have looked at several examples of workflows that use that node. It seems like it needs its partner which is the Loop End node right? Can you help me with the positioning of the nodes within the context of my own workflow?
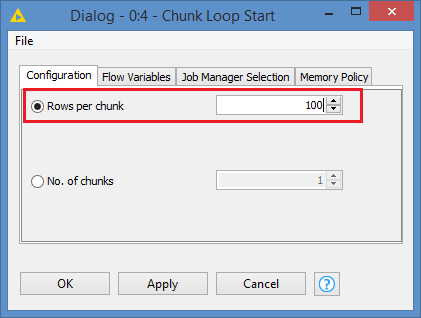
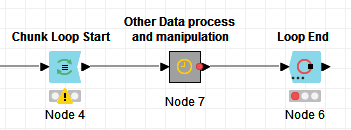
Hi @badger101 , yes, any loop needs to have a start and end.
For example:
So, that would come either after the Duplicate Row Filter or the Math Formula, depending on why you are giving each of them a count number.
FYI, it’s better to use the Counter node to generate a count number, or you can use my component that generates an auto increment number in a column for you
Component:
Thank you. This is the solution for what I was asking. I will mark it as Solved. Although I noticed now my end goal isn’t achieved cause I might be asking the wrong question, hence I’ll make a new topic.
@badger101 you could try and adapt this workflow by calculating the number of chunks and exporting the result to separate files instead of one single CSV file.
Yes, I’m assuming you most probably want to know what to do next
But as far as creating batches is concerned, it’s been answered here. I look forward to your question in the next thread, and hopefully we can help you there.