I have a base file(F1) which needs to randomly distributed on the basis of another file(F2) which has rule give. for exp
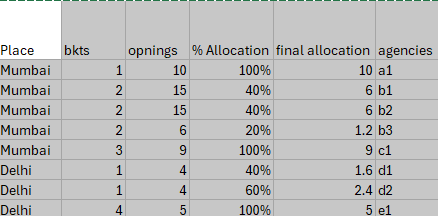
this is the format of the file F2 where colm1, colm2 are joining columns from F1. colm 3 and colm 4 are variable columns, and are used to calculate final allocation, which is the maximum allocation for given agency.
The allocation needs to be done randomly , I found a node Random lable assigner but it seems very lengthy and not optimal for a big data set.
The relationship between the two tables is not very clear. And there’s no information about the structure of F1. Could you provide more detail and if possible upload samples of both files?
Hi @rfeigel ,F1 is a product level table.
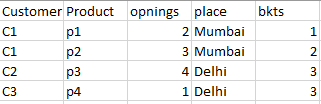
here C1 has 2 products and he is in Mumbai, I will take max of bkt to join from F2 and add up the openings on customer level which will be 5 in this case.
Now this case should be randomly allocated to agency b1 or b2 but not to b3 as it’s capacity is only 3. Same goes for C2,C3 as well, but we will have to take consideration of max limits of agencies.
For example If C1 allocated to b2 then we cant allocate C2 to b2, because b2 has maximum limit of 6 openings and C1 and C2 together has 9 openings.
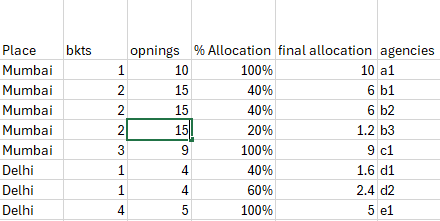
I am giving updated version of F2 as well, as in previous one agency b3’s row was incorrect.
I’ve spent a lot of time reading your latest post and have no better understanding what you’re trying to accomplish. Rather than describing details, could you back up and discuss your business case and the various constraints. it would be helpful if you defined the column headers more completely. If you can, please post data rather than screenshots and any preliminary workflow you have. Bear in mind that Knimers have no idea about your issues and depend entirely on a clear description of the problem.
2 Likes
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.