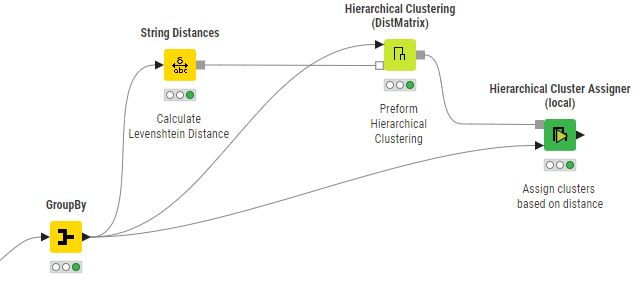
I’m working with product data, and I want to cluster data based on article codes.
I"m using string distances, hierarchical clustering (distMatrix) and hierachical cluster assigner.
The start of a string is more important than the end.
Sometimes the beginning consists of alphabetical characters or numbers like “920” or “1.14”, and the length of the important part might differ between products.
in my example below, I want “BZE” to cluster instead of the “080016” part.
name | cluster group
BZE120200 | 1
BZE080016 | 2
BGD080018 | 2
BRF080316 | 2
TGM080016 | 2
So how can I assign more weight to the first characters of a string and less to every character after (descending in weight for each sequential character)?