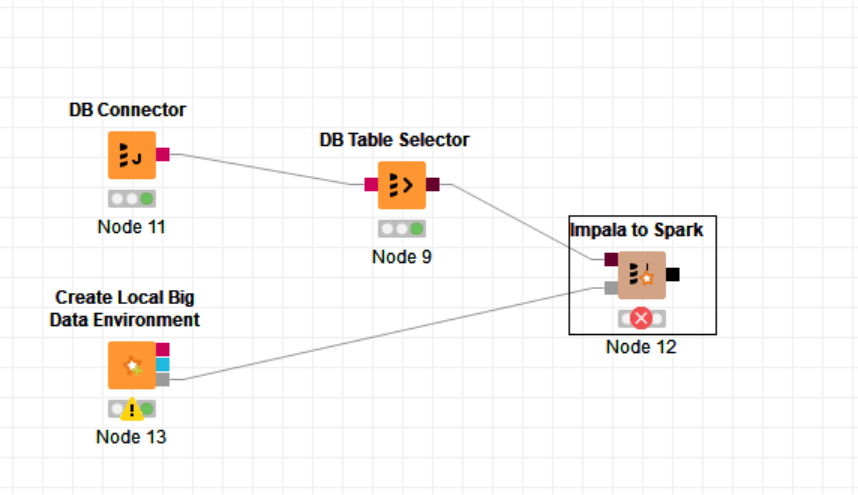
Hi - I’m trying to create a simple workflow that reads a impala or hive table and then use the impala to spark or hive to spark node . these nodes are always returning table not found. I had verified my previous node has selected the table includign the schema name .Have added create spark context node too. Same issue when connecting DBLoader too.
Error and image below: Any help is greatly appreciated !!
ERROR Impala to Spark 2:12 Execute failed: Table or view not found: myschema.testtab; line 1 pos 14;
'Project []
± 'UnresolvedRelation myschema.testtab
(AnalysisException)
ERROR Impala to Spark 2:12 Execute failed: Table or view not found: myschema.testtab; line 1 pos 14;
'Project []
± 'UnresolvedRelation myschema.testtab
(AnalysisException)
Thank you ,I thought about it too and used this node with knime table and that worked where i used spark to table and table to spark. I actually looked for some other node to create spark context. but found only 2 other nodes one (is create spark context(livy) and other was create spart context (job server) we do not have job server in our environment . So unsure which node to use in order get a spark context created. Basically i wanted to read hive table and process it using spark .so looking for similar examples. thanks again.
Hi - I went through the example workflow attached where the create local big data environment is connected to the DB loader and the spark context is connected to hive to spark node. However if i do the same thing my DB loader does not work as it is expecting hdfs connection. it errors with invalid file path. Then if I add hdfs connection then db loader loads data into hive fine. But for hive to spark node, there is no way to reference the hive database or hdfs and again it errors with same table not found . I found another option on create local big data environment node to add the custom hive data folder . That did not help either. Please let me know how i can have hive connected to spark . Is there any other node i could use here ?
If you want to bring data from KNIME to Hive and then spark you will have to have HDFS writing access and a give a folder where a temporary file could be strored. The either KNIME would handel the transfer by creating a parquet file and telling the big data environment about the structure etc. - or you could do it yourself by uploading a CSV or Parquet file from KNIME to HDFS and then create an external table via Hive. Examples can be found here.
You would have to make sure you have proper access to your Big Data cluster, the driver is ready and you have all necessary rights to access HDFS. This can be tricky at some points. You might have to consult your server admin and/or KNIME support.
The good thing is. The nodes and workflows that work on KNIME local big data environment also do work on the Big Data cluster (Cloudera eg.) - with the additional benefit that a cloudera cluster would also support Impala. KNME is actually very good at handling the connections to a big data environment and is easily able to scale up from a local example to a quite large cluster.