@AAM i used your example and set up a workflow that hopefully takes you further in the right direction. Feel free to test it and ask additional questions.
I saw you used an advanced Column expression. I left that as it was.
In your case I would suggest to use a Loop and handle each message (consisting of several lines as one case and export that into a txt file). Therefor you would need a unique ID that would also server as a file name.
I like to use the KNIME protocol that makes it easy to point to files relative to the workflow so you can easily exchange examples.
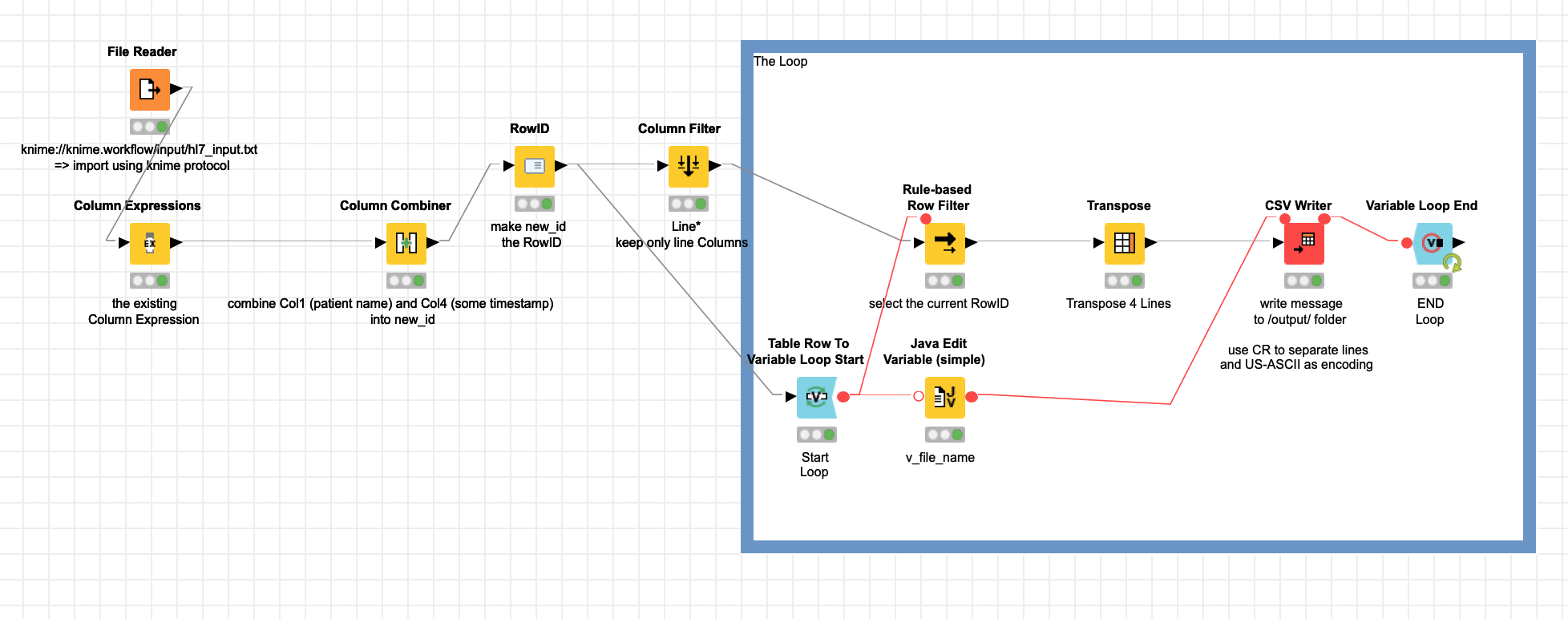
new_id would serve as a unique ID to identify the case later. It is the name and the ? date. You could easily extend this to make it unique and suitable
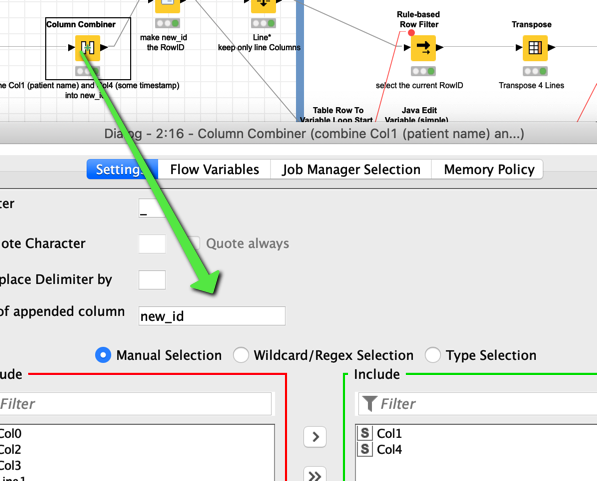
This new_id will be used as RowID for further reference

Table Row to variable Loop is my favourite loop. It uses a table you have somehow produced (in this case all your lines you want to convert) and gives you all the information you need at your fingertips. Once you have familiarised yourself with the concept it will become your swiss-army-knife of automating your tasks.
The Rule Based Row filter so some simplified language to write conditions.
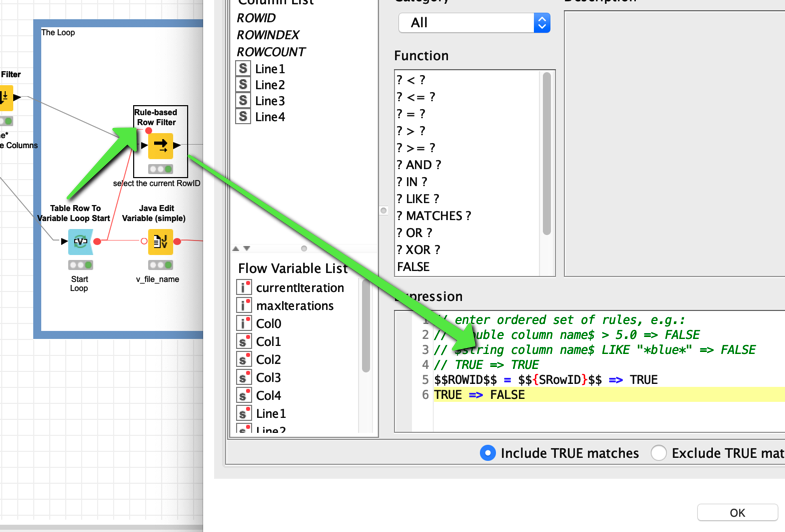
In this example you use the information from the Flow Variable to construct a file name - with the unique ‘new_id’. But you are free to construct every Filename you want and path. In this case the results will land in a subfolder of the workflow - regardless of where this workflow is.

Then you transpose the current case. The new_id is the column and the lines contain the information. If you would add more lines there would be more.
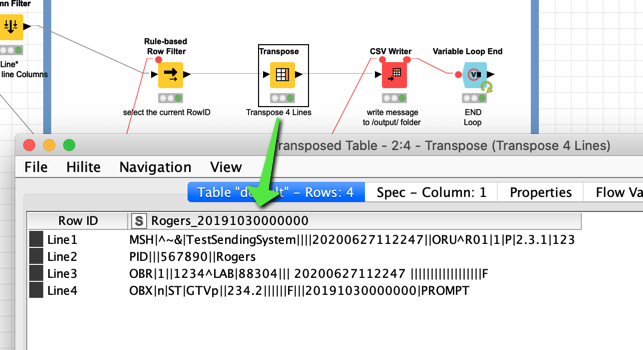
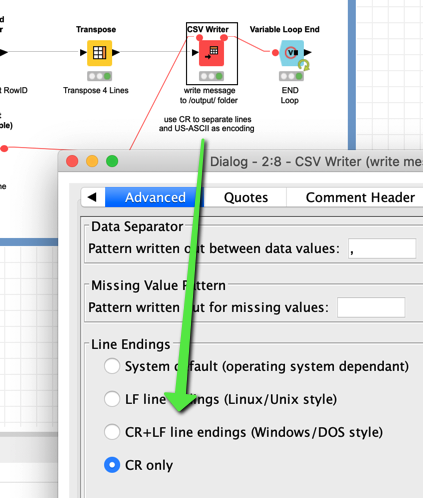
Then the CSV writer would write everything to disk. You could choose various encodings. UTF-8 would be a modern standard. In this case I choose US-ASCII as this might suite your needs but you would have to check out which encoding HL7 would accept. With US-ASCII there are some obvious limitations (special characters …).
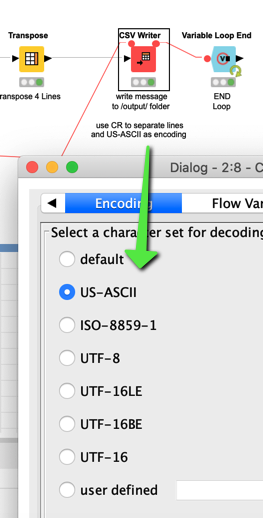
Ten you could choose the Line endings. CR should be ASCII 13 - carriage return. If this is not the case we would have to find other measures. This might be a good time to ask KNIME (@ScottF ?  ) if it is possible to make the line character more flexible although it might confuse people.
) if it is possible to make the line character more flexible although it might confuse people.
And then at the end of the loop you have the results as individual files:

Here is the full example for further investigation. If you have additional questions please ask. It is very possible that there are several ways to do this. I like using the loops with Table Rows - I think it gives me control and I can easily change settings.
kn_forum_hl7_message2.knwf (55.8 KB)