Dear @mlauber71,
Thank you for the reply. I can answer most of your points.
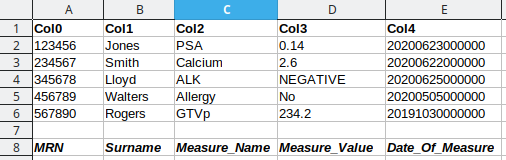
All the more important it is to make a good plan of what you want to do and right now I do not fully understand your task. You have spreadsheets from systems and you have these messages that would consist of one or more lines per patient.
I have spreadsheets with information (data points) from other systems. I do not have the messages, I wish to make the messages from the spreadsheets so that I can deliver the data inside the patient record using the infrastructure of the Oncology Information System (OIS).
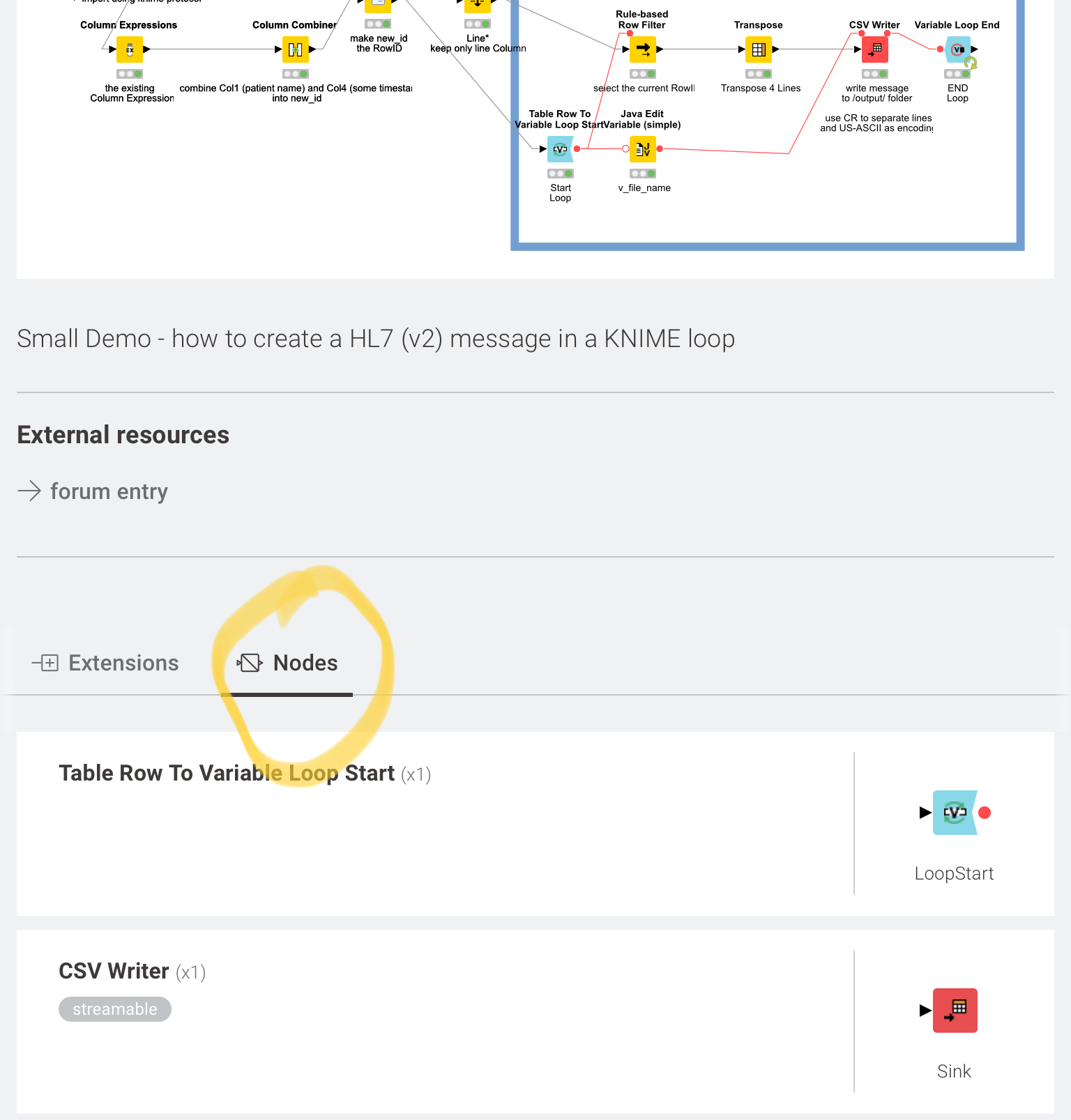
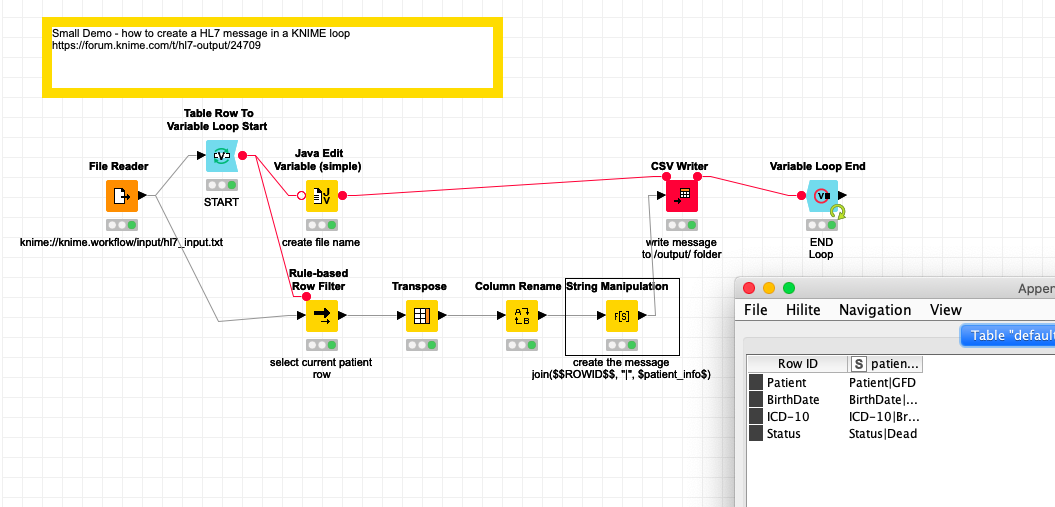
From the example I assumed there would be one file per patient - which would likely mean that the target system would have to have a function to ‘bulk-load’ the data - or you would build a single TXT file that would contain the HL7 messages in the described format. That would make difference in what to do about the data. Maybe you could elaborate further.
It is likely that there will be many files per patient. Each assessment timestamp will have a separate line. I am trying to see if KNIME will do a ‘bulk production’ of HL7 messages. The subsequent ‘bulk load’ into the OIS is via an existing HL7 gateway that checks MRN, surname and item code to authorise intake.
And the best thing would be to provide a full scenario that contains all your conceptual challenges (several lines, different number of lines per patient depending on the message) and the desired outcome. So you would be able to judge if the KNIME solution did what you would expect it to do.
With all due respect, I much prefer an incremental, ‘agile’ system where I can see if and how things work and then play in a copy to see if I can rectify problems myself. It’s how I climb the learning curve. If you say that your brief example will do what I want, I’ll start fiddling with it to see if I can get it to work.
Then I sense that there is the question of updates and current status. I am not sure if your ‘HL7-receiving-system’ would handle that based on IDs (or names ?) and date/time - or if the KNIME system would have to deal with it - that could have some implications what kind of workflow one would have to build.
I don’t understand what you are saying here. You have already produced a prototype that does what is needed, i.e., a spreadsheet produces single HL7 files (*** actually, I think I have just found the answer to my problems which I will check and share later if it works!)
KNIME also offers the possibility to connect to several databases and systems not sure if there is a connection to the mentioned one.
There is no connection to a database required here. KNIME does connect to our database but the rule here is that nothing gets written in except by vendor-approved methods (as opposed to database-approved methods) and that mandates HL7 format that goes through the normal HL7 gateway input mechanism.
Then in the example I tried to note with each node what has been done so it is easier to follow the method. Maybe that can be clarified and explained further.
I shall look at the nodes again, obviously the first time I find it foreign, but I’ll try a few more times. My problem is that I have the brain of a doctor, and there is a very, very, large learning curve to climb to understand what you have done, so I find it only possible to follow examples provided by experts. I can’t spend the time needed to become fluent in ‘Computer’, and I don’t use it often enough to maintain any fluency anyway. I know what I want to do, but the actual coding/configuration requires expertise that I can’t develop except by spending full time learning.
Concerning the let’s say planning of this task. You might want to think about getting some help with that at your organisation. Maybe a talented student interested in data science (or hire a consultant) - or do you want to handle it all yourself - with KNIME that of course is possible since the workflow concept makes it relatively easy to scale up from a small desktop workflow up to steering big data systems for a major Telco company.
Unfortunately I work in a hospital where help for my information problems is not going to be provided, I have asked many times and I just get the dregs (“when I have finished all the things I need to do”). I am stuck handling this myself, OR not doing it. Though I see the need for data scientists in hospital departments (rather than IT departments), I am at least a decade in front of the curve in this view. A data scientist that I could train in data meaning would be wonderful, but the problem is that data scientists get employed and paid by managers to build dashboards showing managerial data rather than patient outcome data (as most departments don’t have outcome data). Until clinical data scientists are appointed (which will be after I retire!), the only way to collect, curate and manipulate this medical data is to do it myself.
If you want to do more yourself it could make sense (besides seeking help in this forum of course which is very welcome and people are happy to help) to invest in some video courses to get a better feeling for the KNIME system. Also to make sure the output quality is what you need since with medical questions you are dealing with peoples health might be on the line.
I have spend a great deal of time getting myself trained in KNIME and pulling resources together for my reporting needs of existing data. I have come to understand that I need specific examples to work on to learn, and even then I have to continually return to those examples. It has served me well so far. I noticed that you seem to have posted that Demo to a repository - I’ll check that out so you might be able to see some of what I have done so far.
And as it happens KNIME is offering a free introduction right next week. And besides that there are plenty of learning resources here on this site.
Thanks for that I’ll have a look.

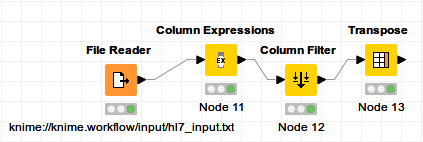
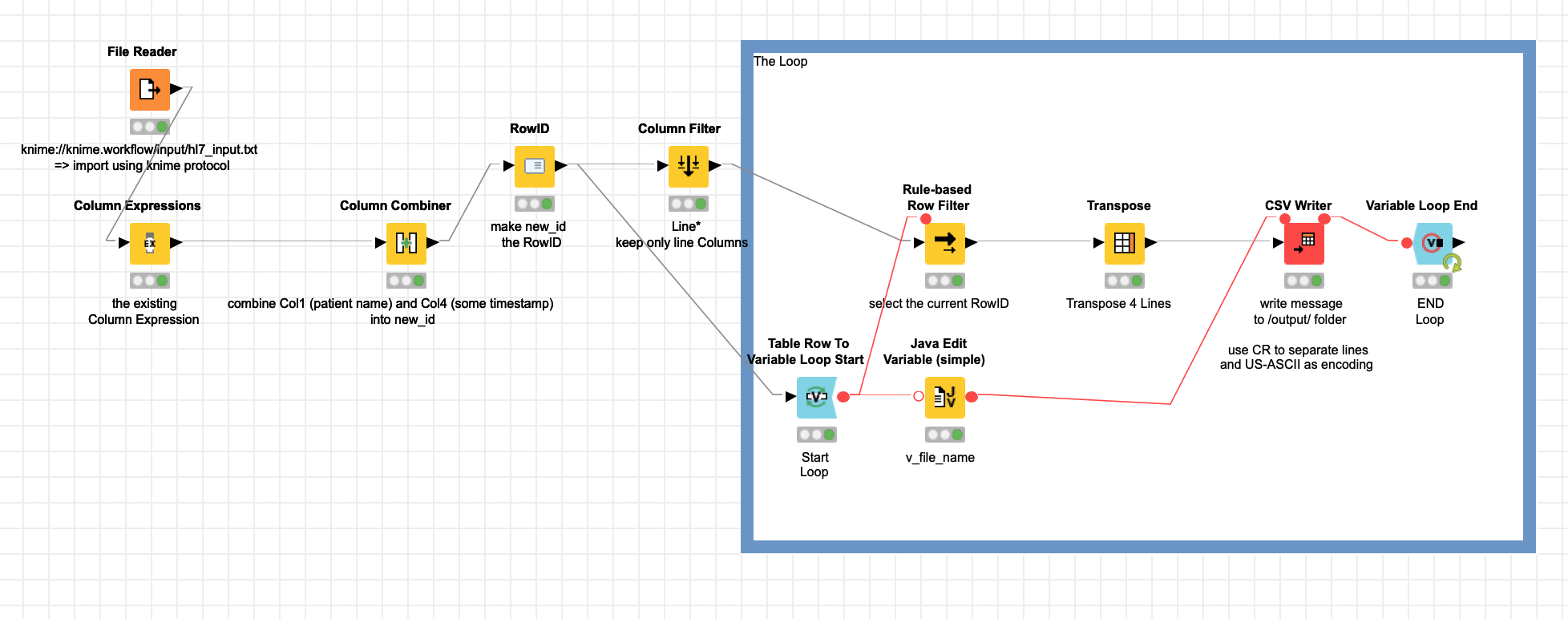
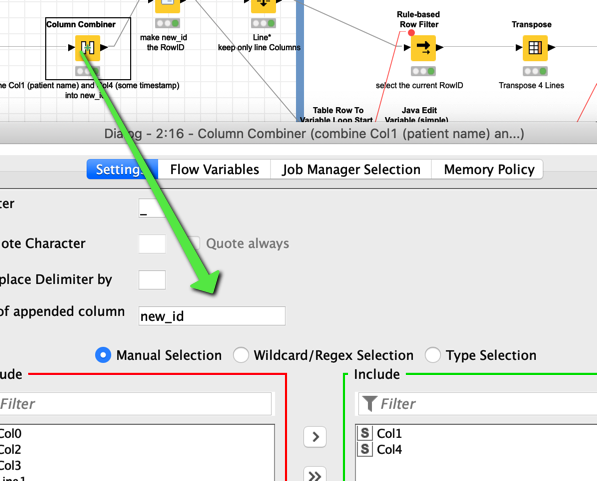

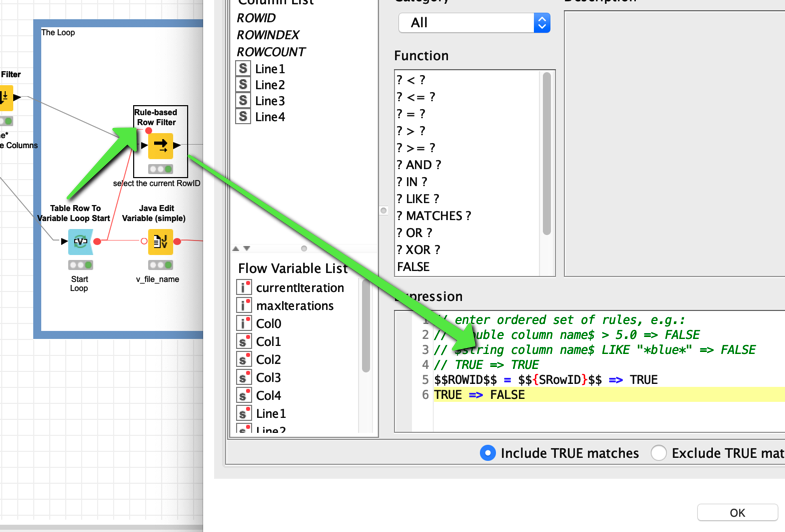

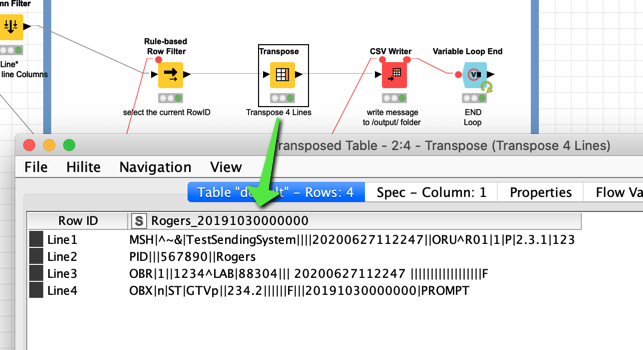
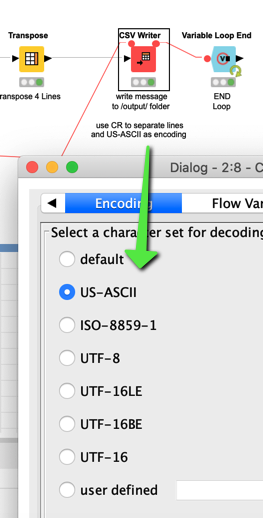
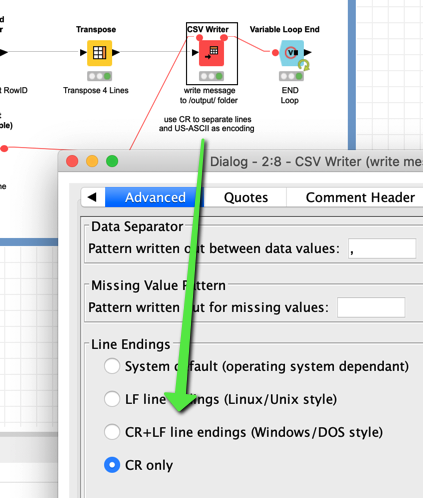
 ) if it is possible to make the line character more flexible although it might confuse people.
) if it is possible to make the line character more flexible although it might confuse people.