Hey guys,
This is my second post on Knime, thank you for all the help on the previous post.
I have a school project that required us to use Knime on a data set and complete 3 tasks, the professor I have for this course is pretty strict on how she marks so I want to get your thoughts on my workflow + report before I submit in hope to improve them.
This is the dataset that we worked on:
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data
This is the description of the dataset:
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.names
These are the 3 tasks to be completed:
Task 1: Data Understanding and Preprocessing (30%)
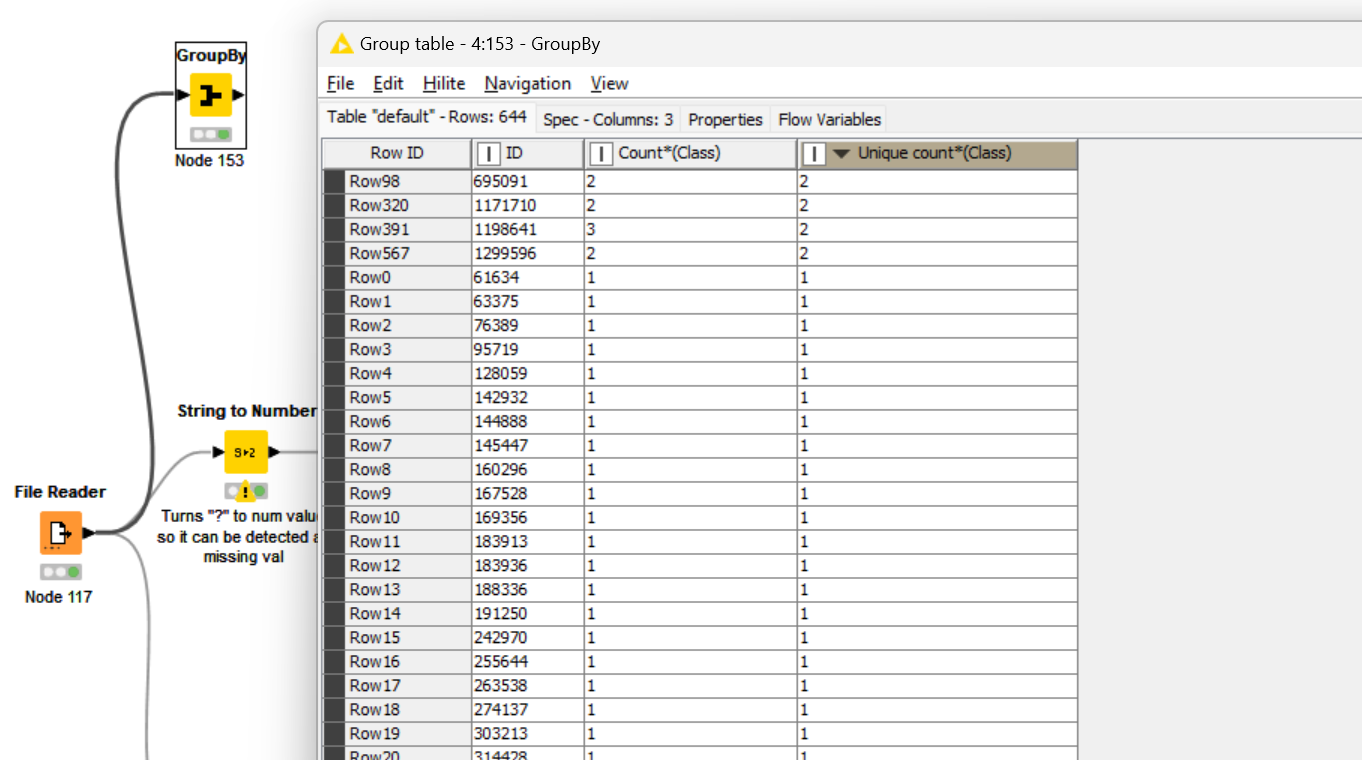
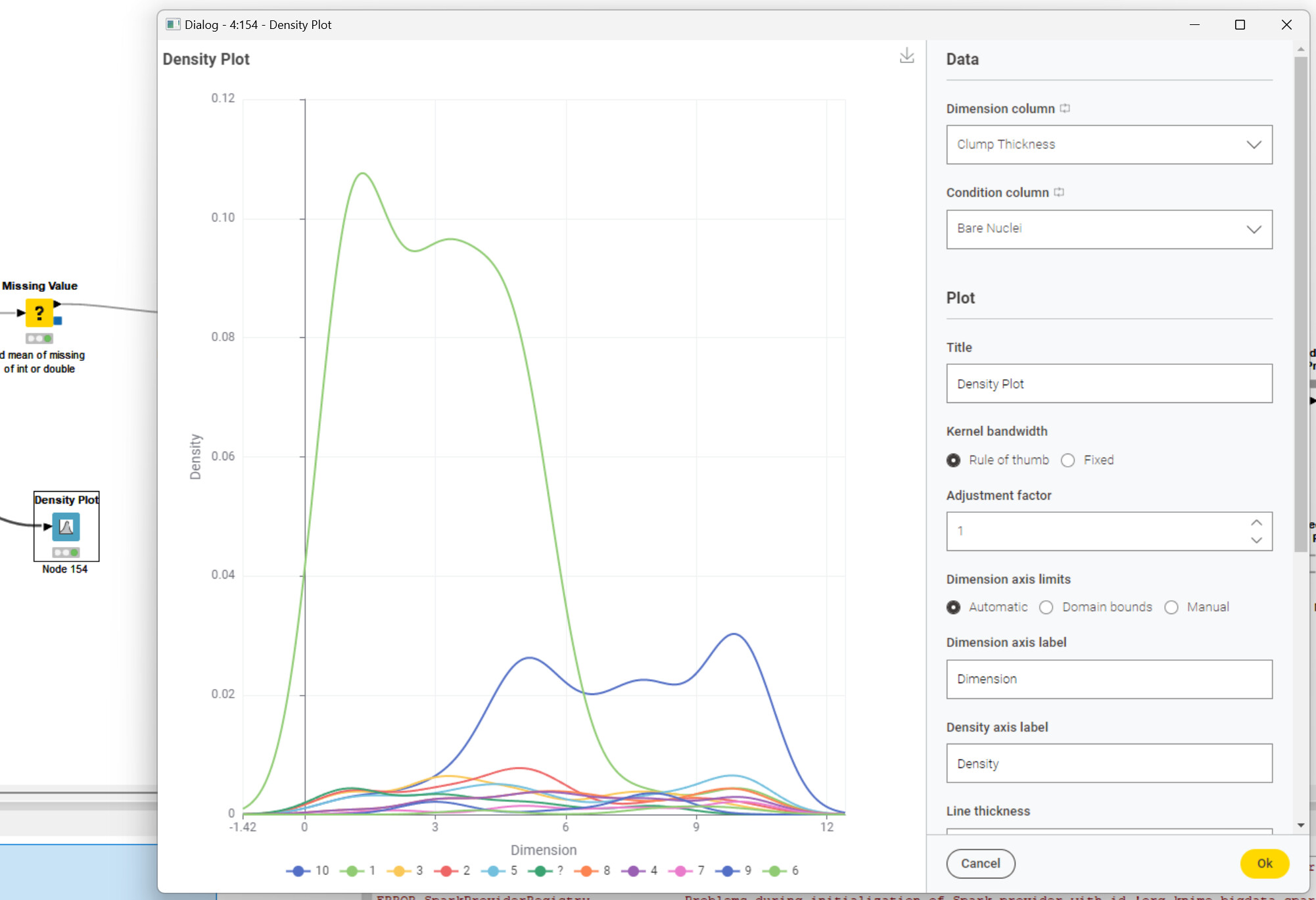
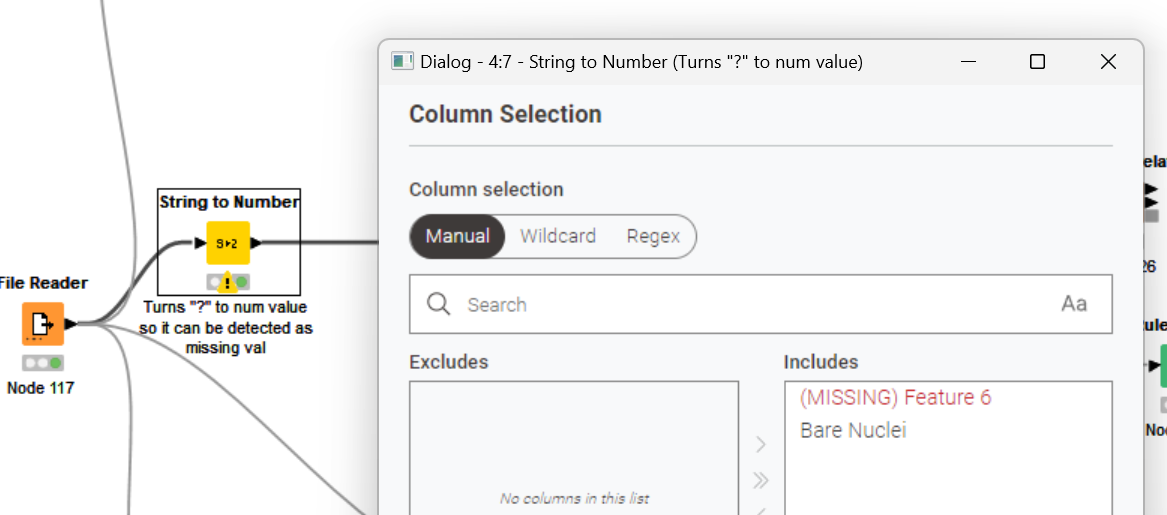
Construct a KNIME workflow to understand the data characteristics and quality, report and discuss your findings. Based on the data understanding, identify and discuss the required data preprocessing steps, and perform them in the KNIME workflow. Also visualize the data on a 2D scatter plot, with colors showing the class labels.
Task 2: Classification (30%)
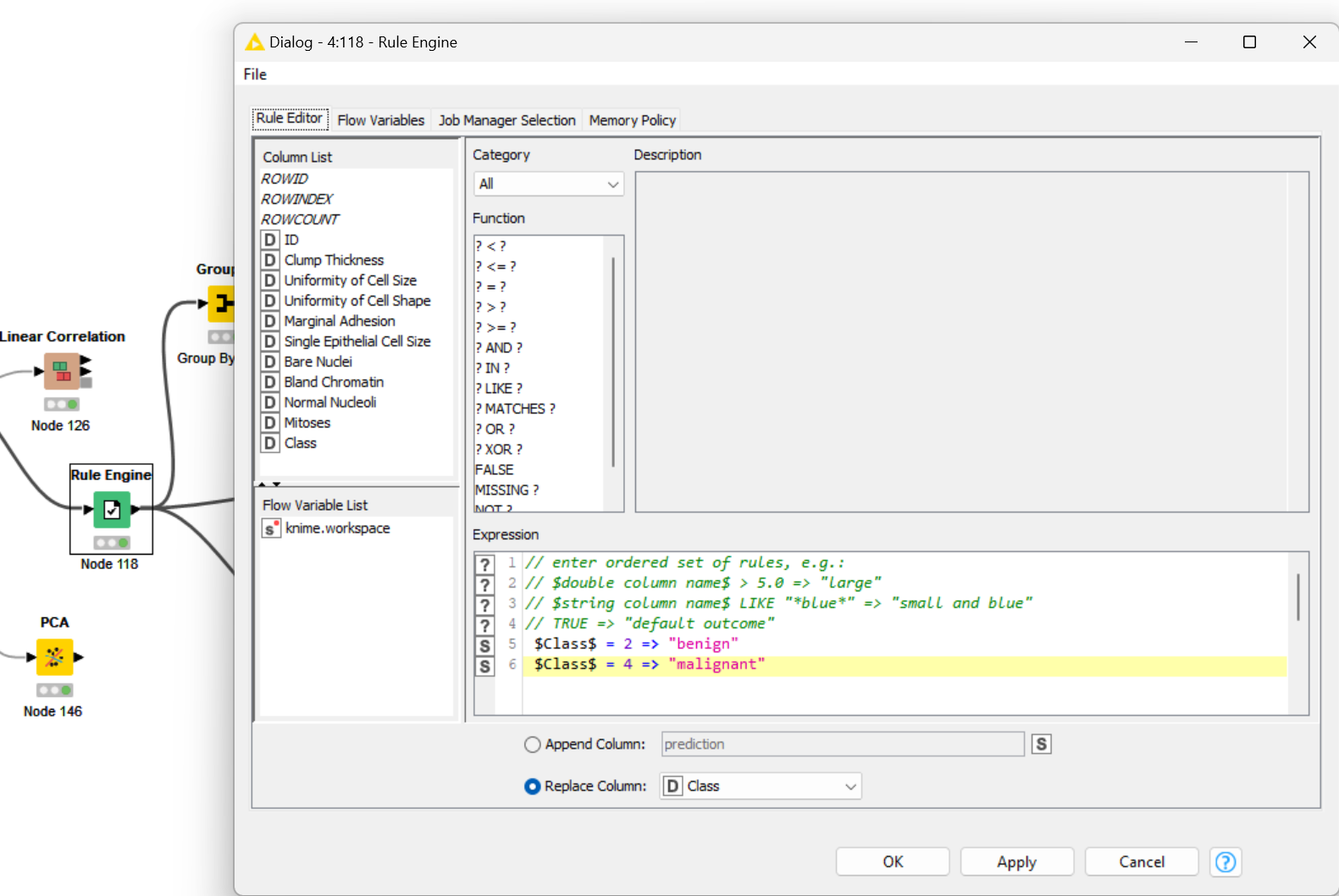
Next, add to or construct another KNIME workflow to build at least two classification models using the dataset by experimenting with at least two different algorithms and/or their hyperparameters. You can use any classification algorithms. In the report, describe the adopted algorithms, also discuss and justify your selection of algorithms and parameters. You may use experiments to support your discussions and justifications.
Task 3: Model Evaluation (20%)
Finally, add to the KNIME workflow to evaluate the trained models using appropriate performance measures and evaluation methods. In the report, describe the adopted performance measures and evaluation methods, discuss and justify your selection of performance measures and evaluation methods, present and analyse the results, also discuss the result reliability.
This is a link to my workflow, uploaded to the public-knime-hub:
And this is my report:
Also, this is a previous critique by my professor on my previous-work where I did pretty bad. I tried my best to amend all the mistakes.
Thank you in advance for any help.