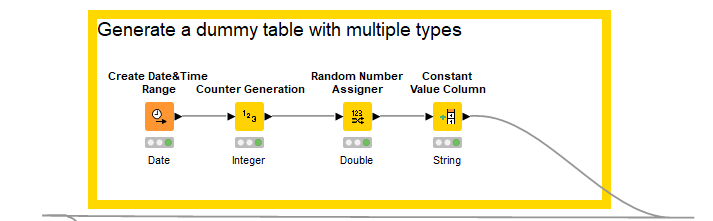
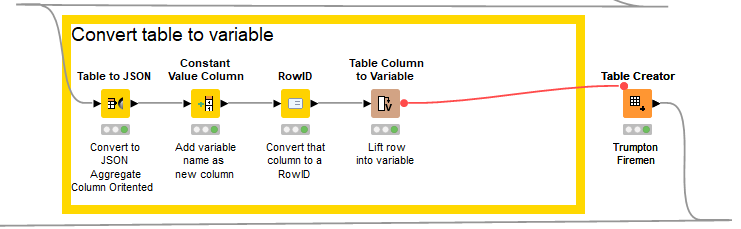
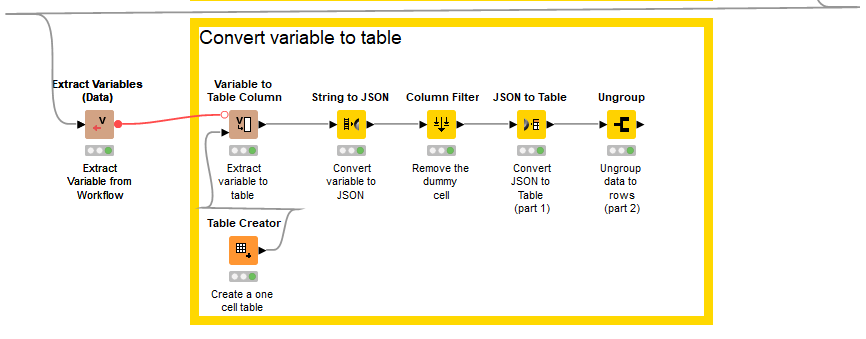
I encountered several occasions where a certain table only serves as a helper table at many points of a complex workflow. For example an exchange rate table that is used at different points of the workflow to join against many tables.
It would be very handy if you could create a pointer to an existing table and store this in a variable which then later on in the workflow can be resolved back into the data table. This would basically need a “Table to Variable” and “Variable to Table” pair of nodes that work as counter parts. It would help me to keep workflows more tidy. But I also see that people would maybe use this too excessively, but then again with great power comes great responsibility
There isn’t a set of nodes that converts an entire table to a variable and then reverses the process. However, you can achieve the same effect by serialising the table converting the serialised table to a variable and then reversing the process when you need it. Serialisation is the process of converting a collection of data objects and storing them in a single object, such as when you are saving an excel workbook in a file.
I’ve created a workflow that demonstrates the process using JSON as the serialisation format. It is not perfect and will not serialise all types of data. As the JSON format converts all numbers and dates to string it will cause errors due to the change in representation. Also, dates are converted to strings, but not automatically converted back. You should use this approach with caution. It does work, but you need to be aware of the cases when it does not.
To convert the table to var - first serialise the table with a Table to JSON node. Note that the Aggregation Direction needs to be changed from the default Row-Oriented to Column-Oriented. If left on row-oriented it is not possible to recover the original table structure. This creates a one cell table containing the serialised original table. I added a column with the name that I wanted call the variable then set the RowID to that column. The one cell table is then converted to a variable - which is what you wanted. That variable can then be injected into the workflow so that it can be accessed later.
Converting the variable back into a table is a reverse of the process. The variable is extracted from the workflow and appended to a one cell table. The string column is converted to JSON and the dummy column from the one cell table removed. The JSON is then converted to a table (part 1), however, the rows are grouped as a set in each column. This data is then ungrouped to retrieve the original table structure.
You now have your original table accessible from a variable stored in the workflow. Note that the date columns are strings, though numeric columns have been retained.
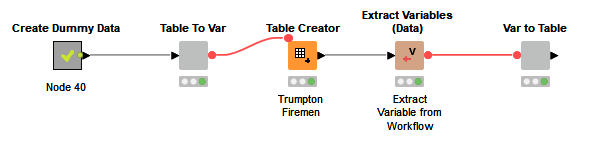
It’s a faff to do that every time, so I created two components to convert table->var and var->table which are included in the workflow. The variable name is a configurable option. This shows how the workflow now looks with components.
Hi Artem,
thank you very much for your quick suggestions! I use those nodes quite regularly but now I am really talking about a simple pointer to a whole data table. Using those nodes would clutter up my flow variables excessively and might not work for some data types such as images or documents.
Best,
Dominic
However, as you said this is not working for all data types and might be error prone. A standard implementation of creating a pointer to the table as a variable and a subsequent dereferenciation would be way more robust and, in my ideal world, wouldn’t be too complicated to implement in the background of KNIME
I would agree with that. My conceptualisation of it was more visual, in that connections could tunnel across the worksheet i.e. a tunnel entry portal would create a reference to a node output port and a tunnel output portal would provide the data to a node input port. I like you idea as it helps make the calculation graph more explicit and provides a mechanism for naming the tunnels.
I am in full favor of this. I was thinking about it today. something similar to a wireless connection that in Alteryx. It keeps the workflow a bit less cluttered by removing lines going all over the place. In alteryx its really obvious when the input and output is wireless. it shows the picture of an antenna in the input and output port
Hey guys, maybe if here are the pros in table to variable you can help me without crating a new topic.
I would also love a table to variable Node but with a different outcome than the original post.
If I have for example a table like this
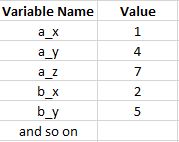
I would like to have 9 variables out of the table like this:
Do you guys know if there is an easy way doing this also with the renaming of the variable name?
It would of course be also nice to have the whole table as one variable (for less variables) but be able to access each cell like a single variable. Then it would be similar to the original post.
I agree with table caching and connection caching being a nice idea for decluttering complex workspaces. I’ll vote on this.
@dobo
A simple way to cache a table for downstream use is to write your “exchange rate” table to the workflow data area with a Table Writer node when you create it. Then, wherever you need it downstream use a Table Reader node. That way you don’t have to connect from way upstream to way downstream in your workflow (make sure to connect the reader to a node just upstream via the Mickey Mouse ear variable ports so you don’t read before it is written). This also helps with the complex data types that aren’t as easily handled in JSON.
@Flo1124 Flo1124
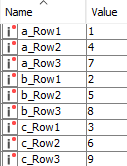
Use the Unpivoting and Table Column to Variable. Here’s an example using row number instead of letters.