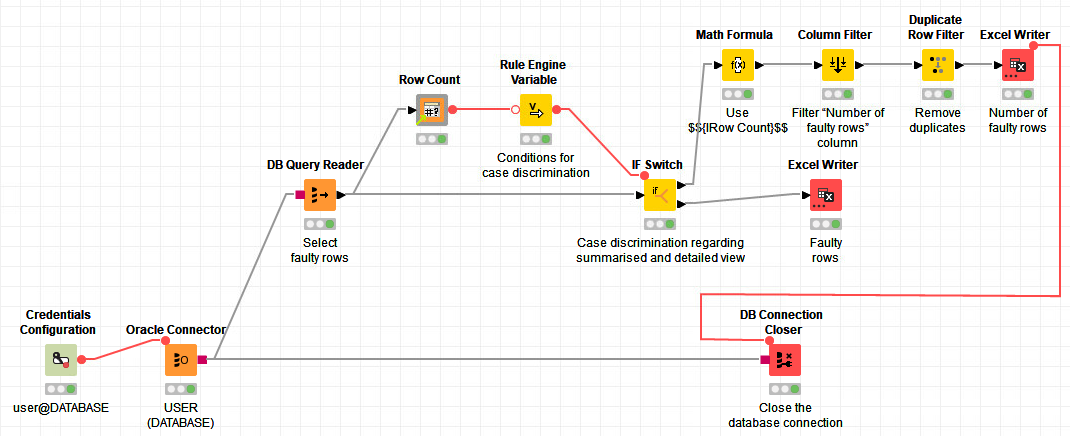
Case 1: Faulty rows do exist
The Math Formula node Use $${IRow Count}$$ uses the Row Count from the Flow Variable List. So, in the Expression box, my expression is just $${IRow Count}$$. Append Column: is selected and Number of faulty rows entered as a name. Also, Convert to Int is checked.
The Column Filter node Filter “Number of faulty rows” column only includes the Number of faulty rows column and excludes all the others.
Let us assume that the number of faulty rows is 400. The Duplicate Row Filter node Remove duplicates is set to Remove duplicate rows because the table now just contains one column that contains the number 400 in 400 rows.
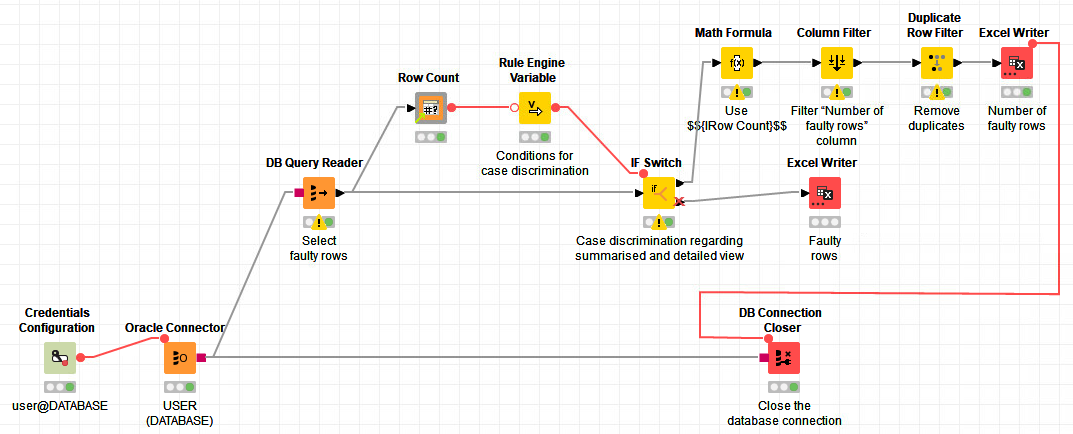
Case 2: Faulty rows do not exist
If the table does not contain any faulty rows, just the Number of faulty rows table is exported. But it does not state that the number of faulty rows is 0; it represents the number of faulty rows as a null value, that is, as an empty cell in the Excel file.
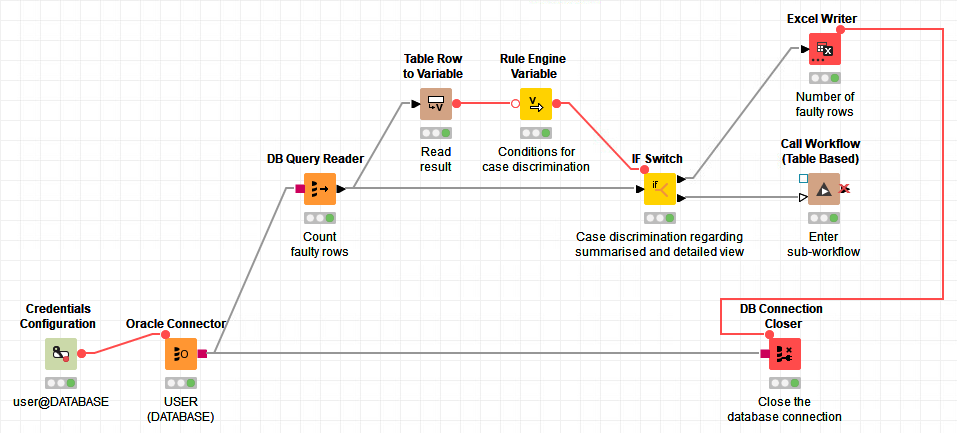
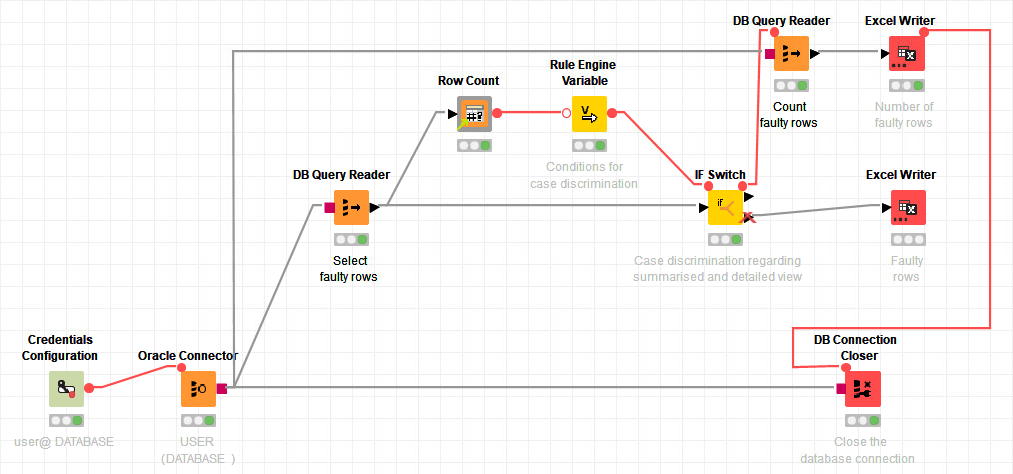
@mlauber71 I was able to easily integrate @iCFO’s last answer into my current workflow which now almost completely satisfies what I would like to achieve. Now, the solution contains one DB Query Reader node instead of two. I also found out that the connection from the Excel Writer node Number of faulty rows to the DB Connection Closer node Close the database connection can also be drawn from the DB Query Reader node Select faulty rows.
Your approach contains two DB Query Reader nodes: One for selecting the faulty rows and one for selecting the number of faulty rows. But I think that I can use your proposed nodes as well in order to solve the problem!
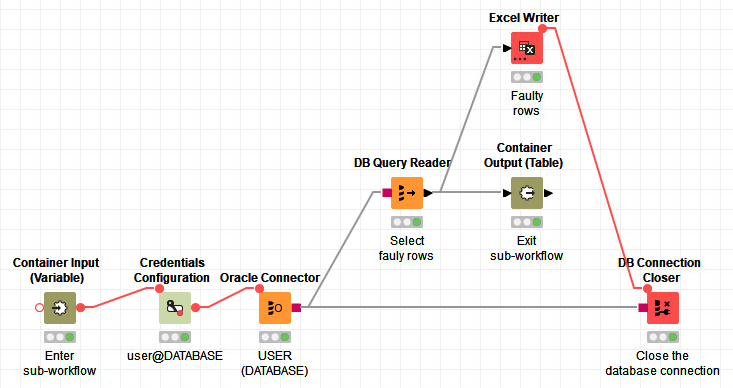
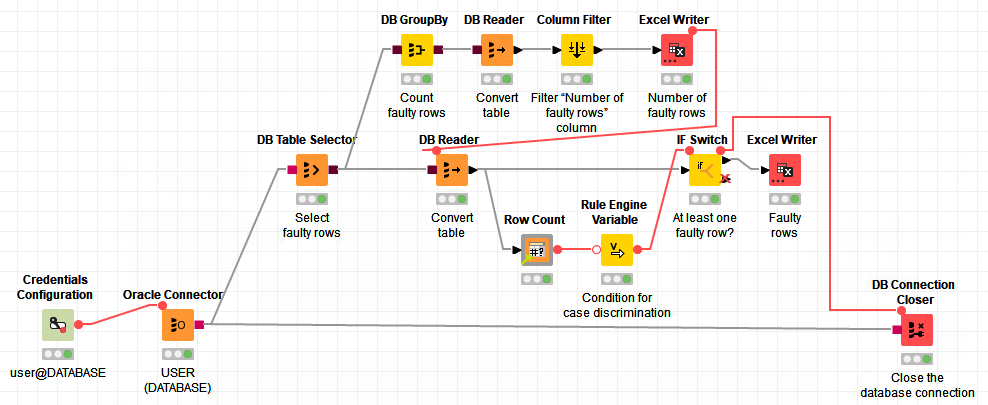
This is how my alternative workflow looks like:
The DB Table Selector node Select faulty rows contains my SQL statement that selects the faulty rows.
Top branch:
- The
DB GroupBy node Count faulty rows groups by an ID column. First, I went to Settings -> Manual Aggregation and added the column from Available columns to To change multiple columns use right mouse click for context menu. and changed the Aggregation (click to change) to COUNT. In the Advanced settings section, I checked the Add COUNT(*) box and set Number of faulty rows as a column name.
- The
DB Reader node Convert table is used in order to operate on a locally stored table.
- The
Column Filter node Filter “Number of faulty rows” is used in order to include the Number of faulty rows column.
- The
Excel Writer node Number of faulty rows outputs the number of faulty rows to an Excel file and tells the DB Reader node Convert table to start its operation.
Bottom branch:
- The
DB Reader node Convert table is used like in the top branch.
- The
Row Count node counts the number of faulty rows.
- The
Rule Engine Variable node Condition for case discrimination contains the two lines $${IRow Count}$$ >= 1 => "top" and $${IRow Count}$$ <= 1 "bottom". The New flow variable name is prediction.
- In the
IF Switch node At least one faulty row?, Flow Variables -> PortChoice is set to prediction. After the node is finished, the database connection is closed. (I suppose that it can already be closed after the DB Reader node Convert table is finished.)
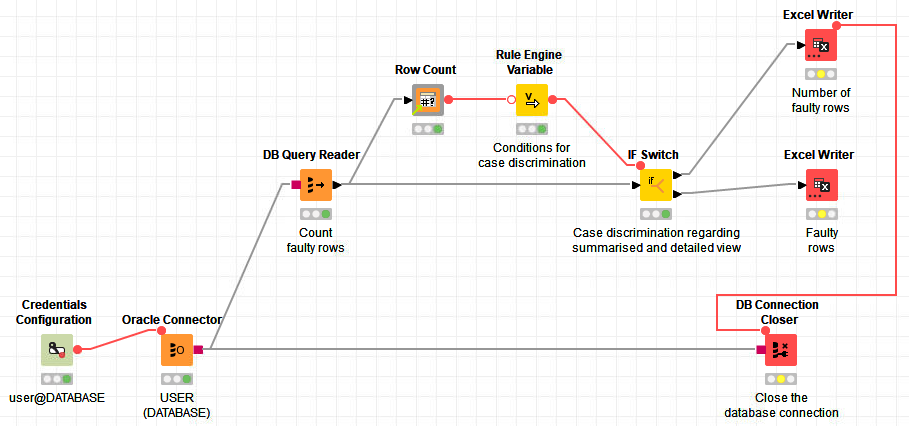
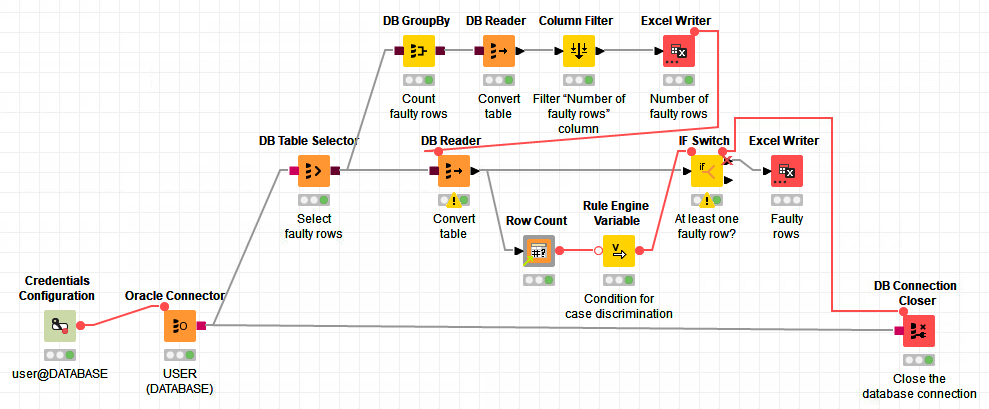
This solution does what I want, even when the number of faulty rows is 0:
What do you think of the different approaches?
By looking at the second solution, I could replace the DB Reader node Convert table in the top branch with a DB Column Filter node Filter “Number of faulty rows” and place the DB Reader node Convert table afterwards. But are there any other improvements that can be done? Or is the second approach still too complicated?
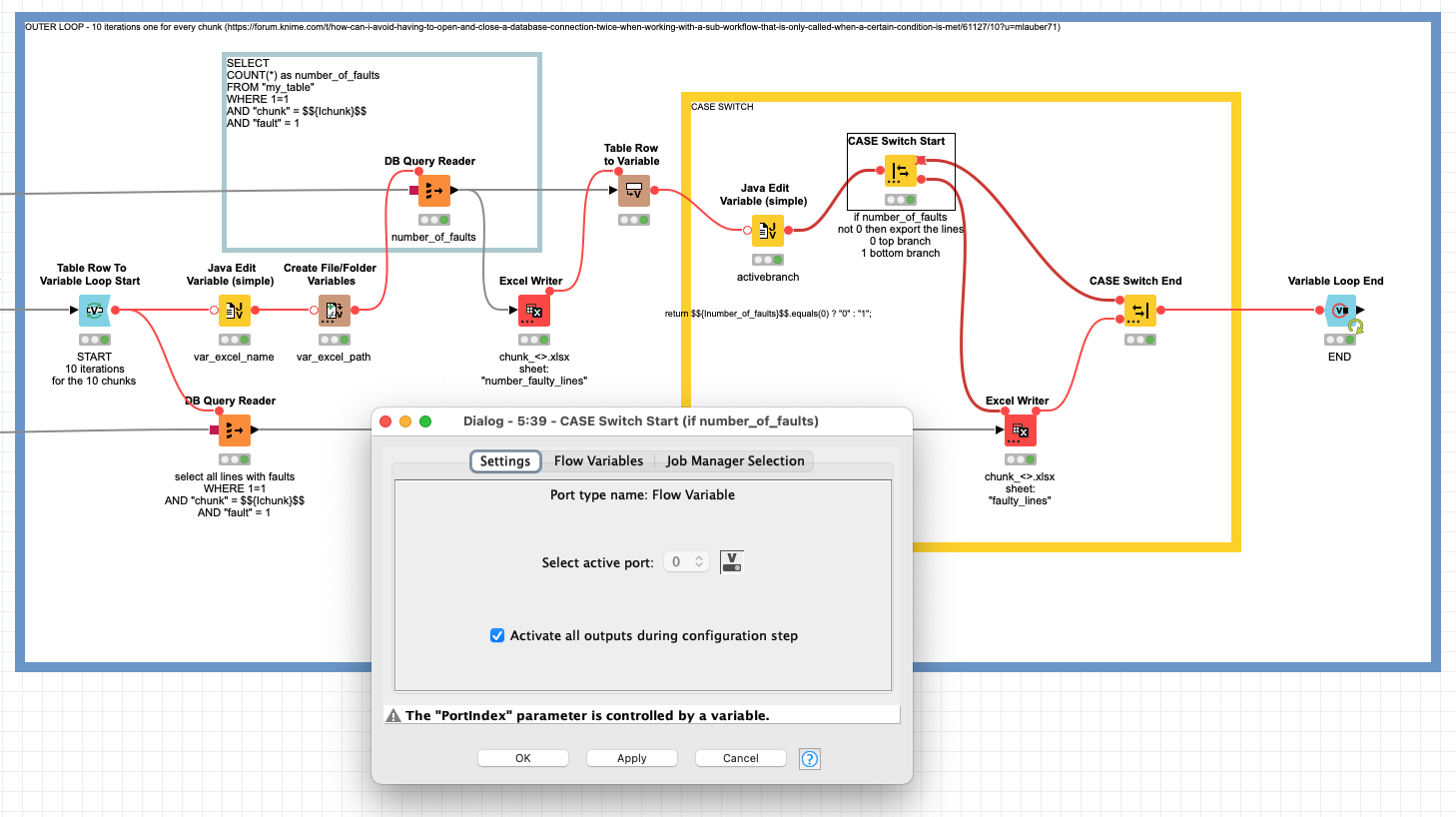
(Please note that I was not able to set the Rule Engine Variable in such a way that would have allowed me to leave out $${IRow Count}$$ <= 1 "bottom". If I had left it out, the IF Switch node would not work properly! Is there a better way to solve this particular sub-problem?)