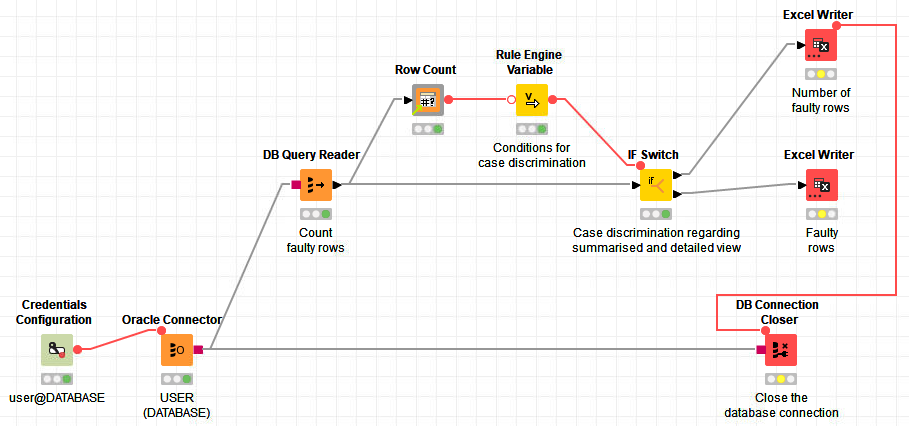
@iCFO @mlauber71 Your approaches seem to be better. I have replaced the Count faulty rows SQL query with the sub-workflow SQL query that SELECTs the detailed faulty rows. Then, I replaced the Table Row to Variable node with the Row Count node.
I installed the Row Count node by downloading and installing it locally in the following manner:
- I went to
File -> Import KNIME Workflow…. - Where it says
Select file:, I clicked onBrowse…and selected theRow Count.knwffile. - The
Select folder:is set toLOCAL:/.
After doing this and clicking on Finish, the Row Count node appeared in my KNIME Explorer and I was able to use it.
You may ask yourselves why I have installed the node in such a way. Well, other approaches like dragging and dropping did not work. When I tried to open File -> Install KNIME Extensions…, I received the following error message:
Problem Occurred
'Contacting Software Sites' has encountered a problem.
No repository found at http://update.knime.com/partner/4.6.
I am, however, able to open this window by clicking on Help -> Install New Software…. But I do not know how to properly proceed from there in order to install the node so that it appears in the Node Repository.
Please keep in mind the special circumstances that I have to deal with when I am using KNIME. They seem to be responsible for these cumbersome approaches that I have to take.
Coming back to the workflow, I would now like to export the number of faulty rows to an Excel file following the top branch of the IF Switch and export the detailed faulty rows to an Excel file following the bottom branch. The bottom branch can be easily constructed by replacing the Call Workflow (Table Based) node with a simple Excel Writer node. But how can I do what I would like to do when it comes to the top branch?
In order to solve this problem, I would like to perform another SQL query on the IF Switch top branch table and move this result to an Excel Writer node afterwards. When I was thinking about how this can be done, I came across this post where it is suggested that it is possible to write a table into a local SQLite database, perform SQL queries on it and use it again. This could solve my problem if I can get it to run properly.
Do you know how this can be handled? Can this page help me to solve my problem?
Right now, my workflow looks like this: