@DAmei I had another look and I built a slightly over engineered workflow to try and get what you want combining some of the approached already mentioned. In your case there might not be a ground truth against wich to match but rather a lot of possible combinations.
So configuration will be necessary and maybe exclude some obvious detaches in the first place. What the workflow does:
- the address is turned into a standardised string. The composition of the string will influence the matching. So for example if you want to stress the importance of the street you might add that a few times. Or you might just want to use the start of the Company name - because this mostly is consistent
- the you would generate a Counter as an artificial ID and start fron the top
- you match all lines that would match the first row according to a Rang Filter (about the distance). If you think the matching is too wide you might want to restrict that settings further down from 25 (0.25)
- the workflow will store the already matched lines at each step and if there is no match the line is a single entry
With that you should be able to build the groups of matching addresses. Each address can only be chosen once. You might have to tweak this approach
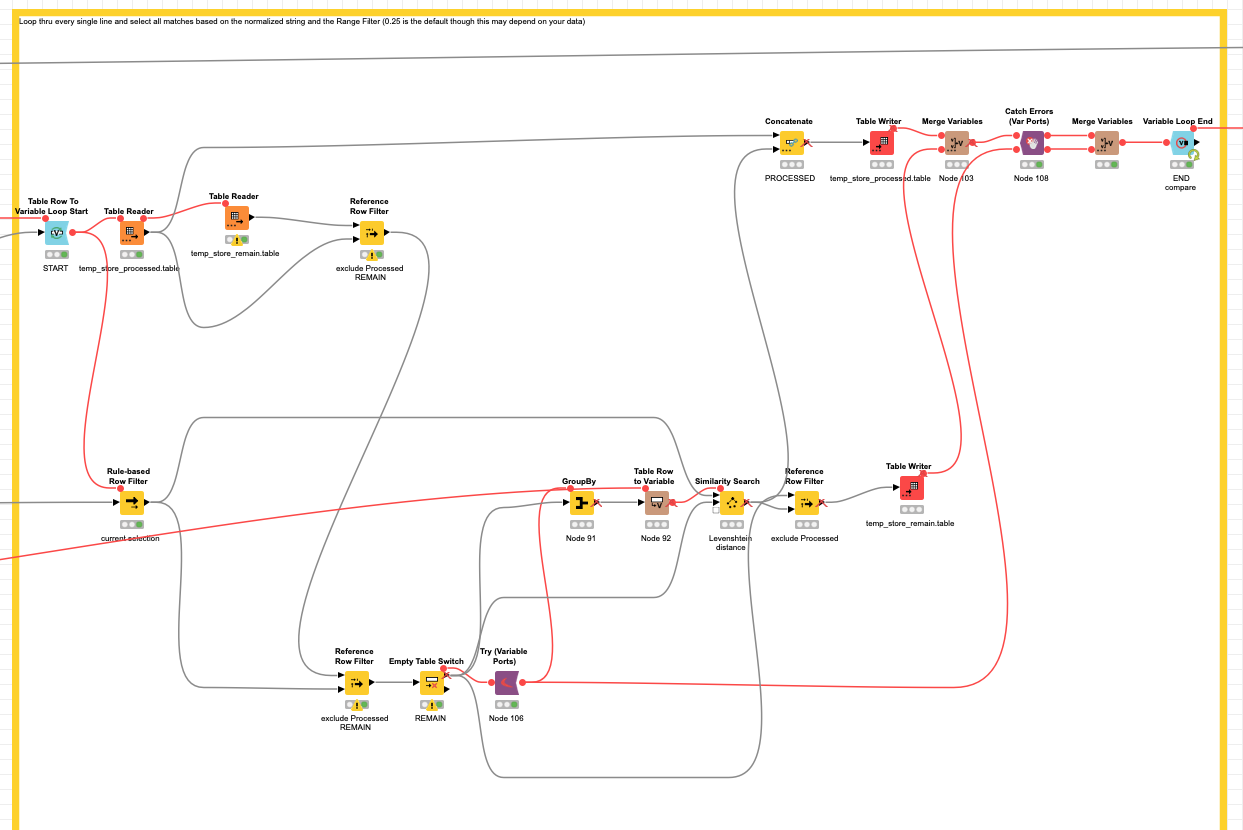
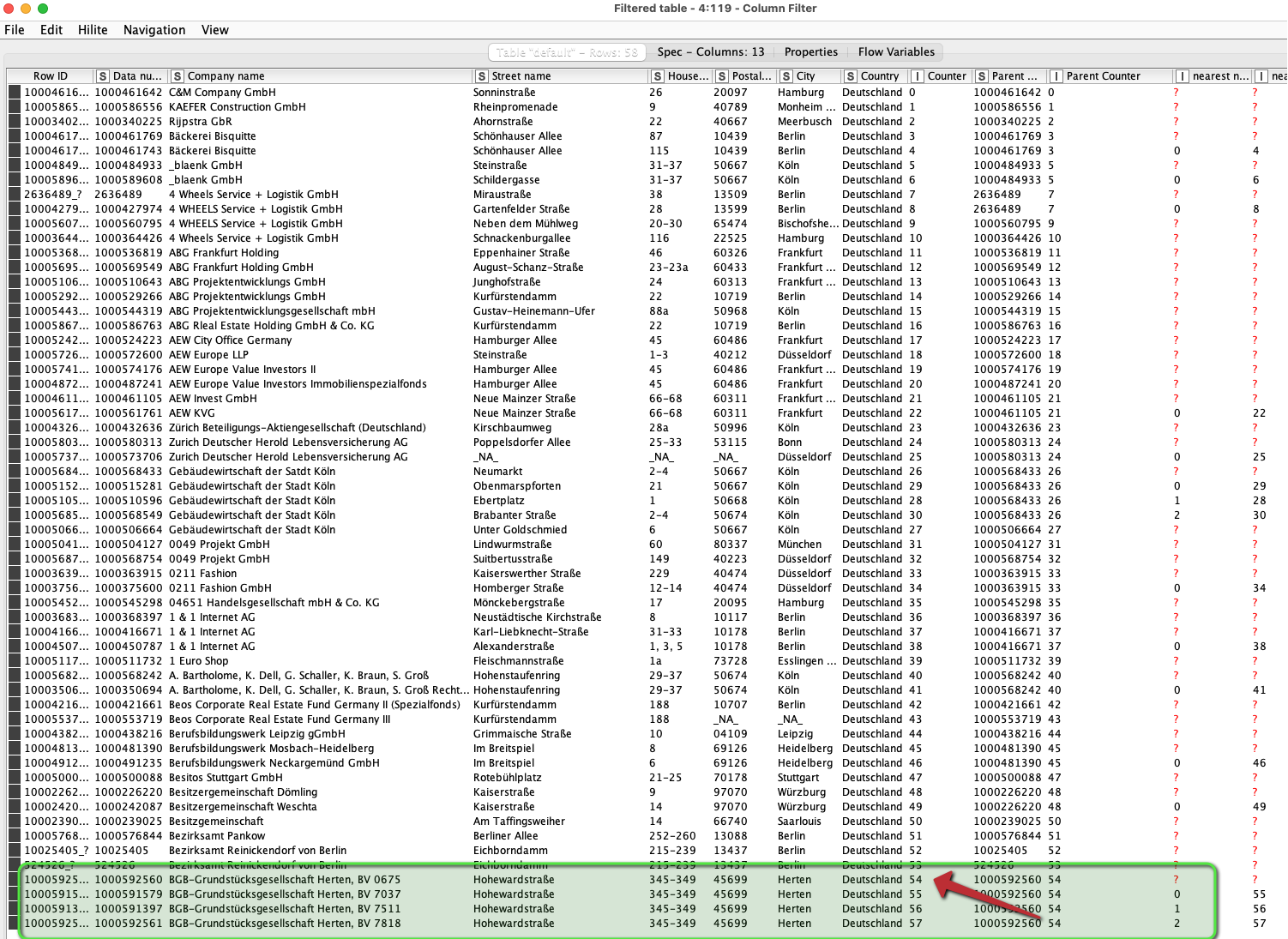
The result would have a Parent entry and add all the ‘children’.
I might have another look at further techniques mentioned in the forum/hub and bring them into a similar approach.