I have found an example workflow in KNIME Hub, which could be potentially very helpful to find out adress duplicates in a given reports. (access to the Example Workflow)
But… I have no idea how can I use the node “String Distances” to configure, for example “Distance Selection”, “Gram Size”? Whether it is necessary to using “Groupby” also in my case study? (I show you here my dataset for testing and also my workflow). Concerning to my user case, is it possible to customize distance measure and then to use the Similarity Search node in order to normalize account names and addresses according to my case study? How can I do it well?
Thank you very much in advance for your comments or your correction of my workflow.
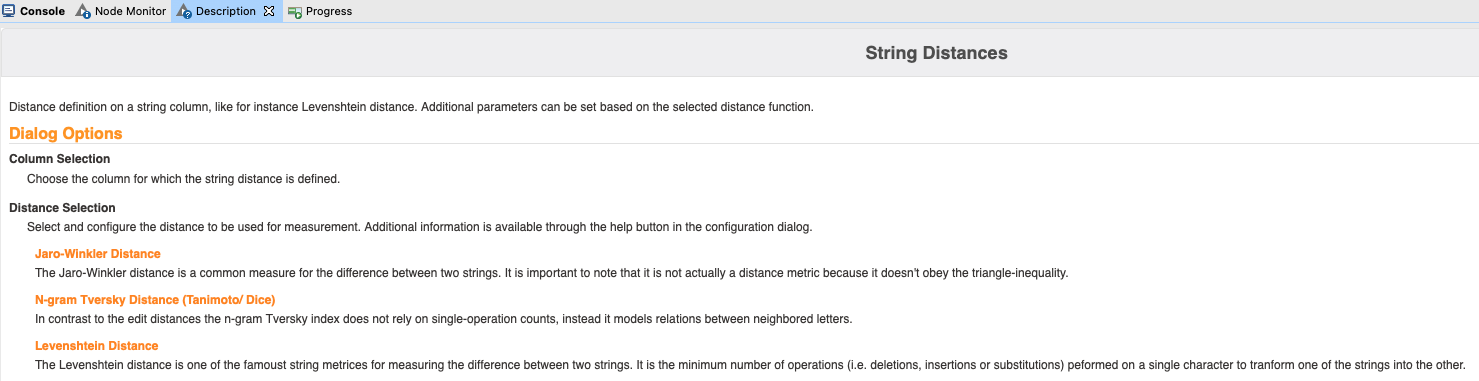
Every node has a description where you can see the different Distance Selection options and some information about them. Since these are each different algorithms, you then need to look up the material concerning that algorithm to use it correctly. To do so, simply click on the orange text for each algorithm and you will be taken to the relevant wikipedia page.
What do you mean by “use the Similarity Search node in order to normalize account names and addresses”. The term normalization has a very specific meaning in NLP (natural language processing), so I just want to be sure we are talking about the same thing.
Something else to note is that the example you used had labeled data which you do not seem to have (?) I don’t speak German so I’m not sure. If you could provide english column names, that would be great.
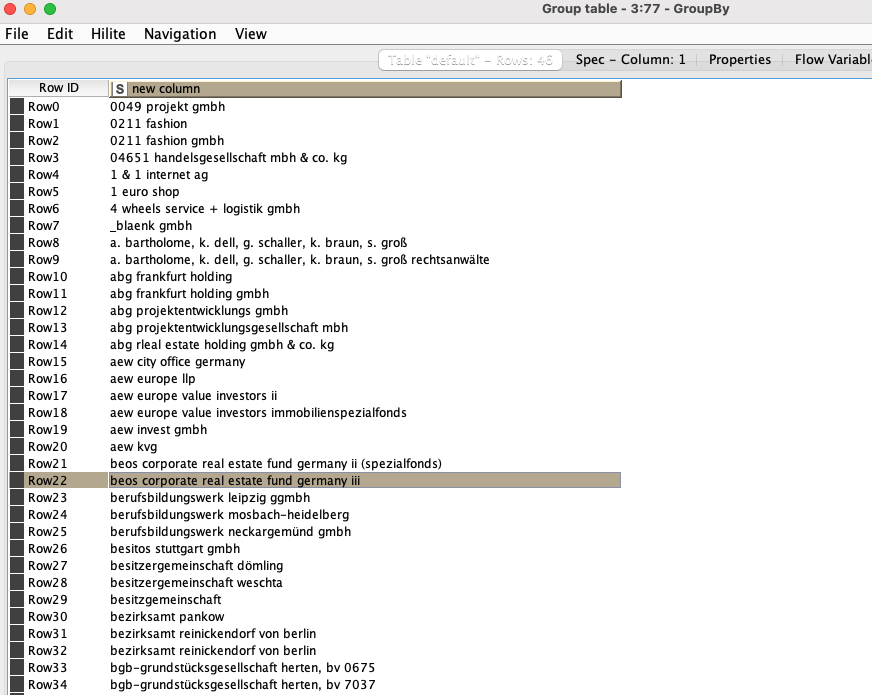
So your approach will be slightly different. For instance, I did Excel → String Manipulation (strip(lowerCase($Firmenname$))) → Groupby and took your original list down by 20 items.
thank you very much for your comments. I have already done some research about Jaro-Winkler Distance, N-gram Tversky Distance, Levenshtein Distance etc. To be honesty, it is difficult for me to make general understanding about all of these definitions, because I do not have any background in this field…
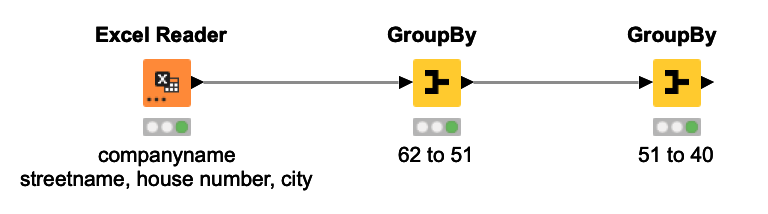
But… I have still tried to figure out how I can get a decent result by changing diffferent N-gram, for example, 8-gram size, 15-gram size or 28-gram size in String Destances node for streename, 1-gram size oder 5-gram size in another String Distances node for house number etc. But it doesnt work well. I think, you have given me a good idea. I should at first use String manipulation and Groupby to combine the streename and house number in one column together. It makes the next step "String Distance" easier, doesnt it? I will try it at first.
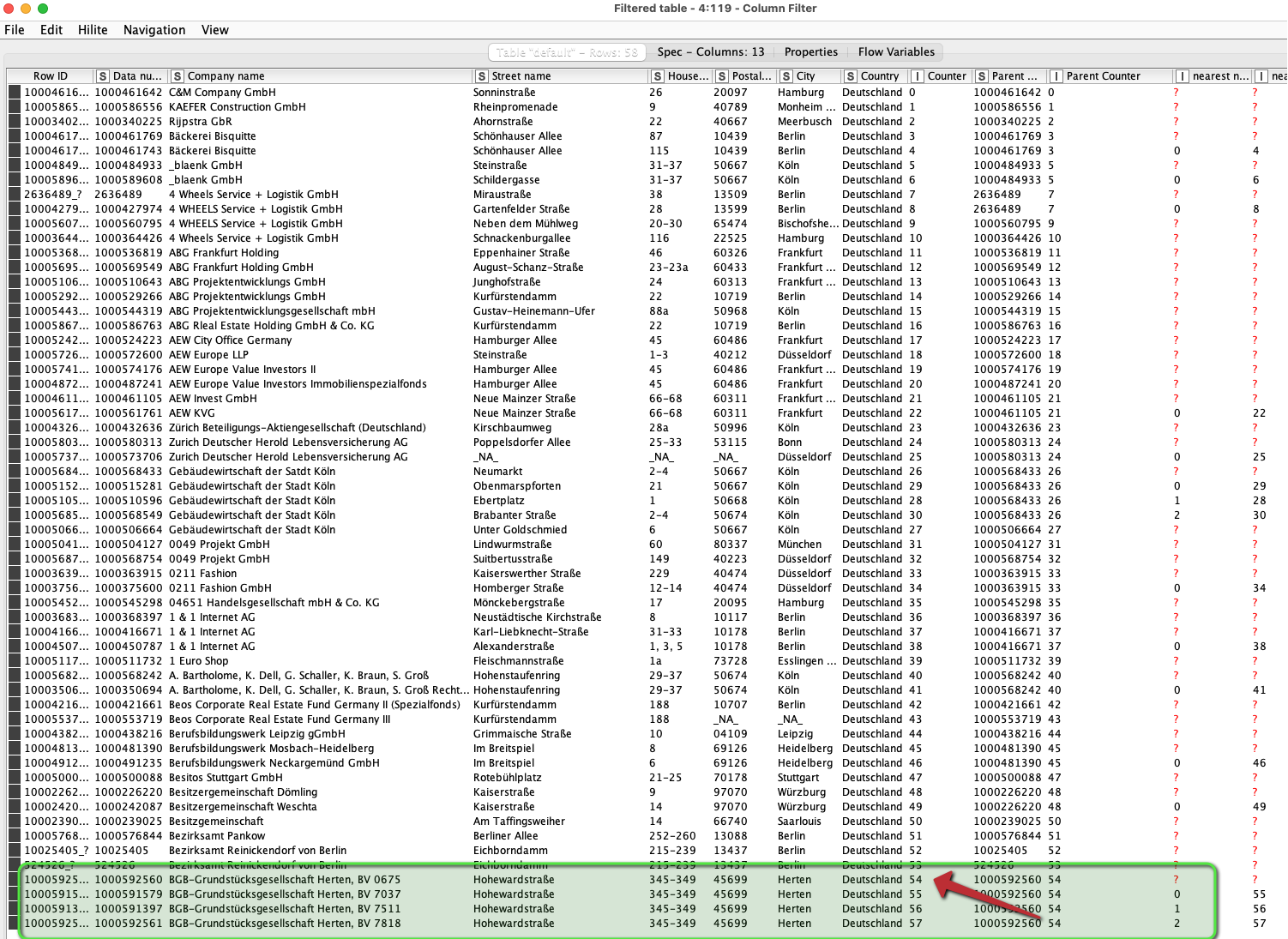
My rule is actually very simple and I just want to find out the data, which hat not only the same/similar companyname but also the same address (the same streetname, house number and in the same city).
I have uploaded my testing data in english. Thank you very much for your time and your comments in advance.
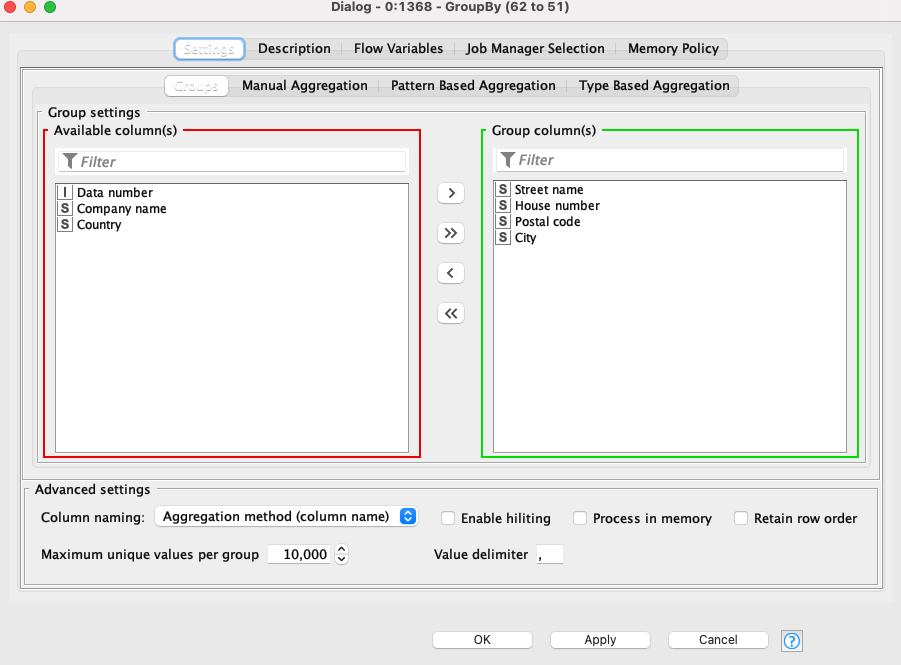
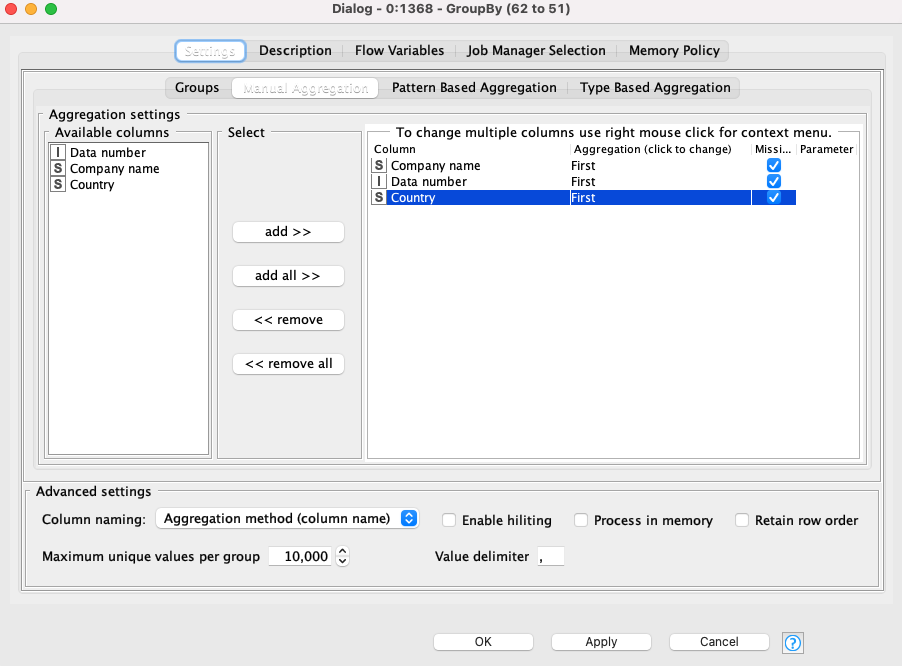
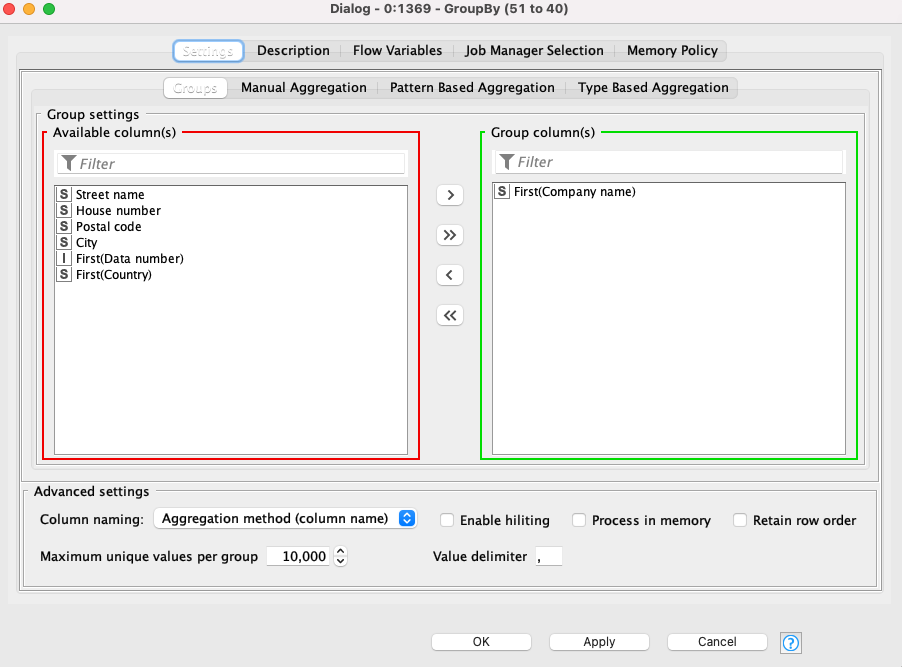
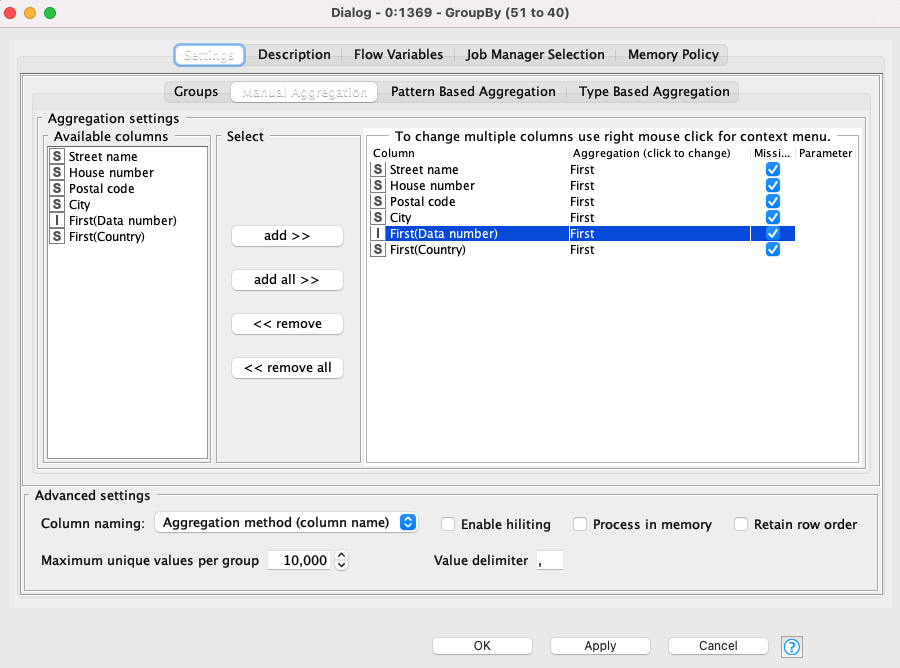
You first groupby the street name, house number, postal code, and the city (this generates a list of unique rows with those 4 matching reducing your list by 11 rows):
If this is still not sufficient, then please manually label all your rows as “original” or “duplicate”. That is, make a new column and label each data point so that we can try making a more complex workflow.
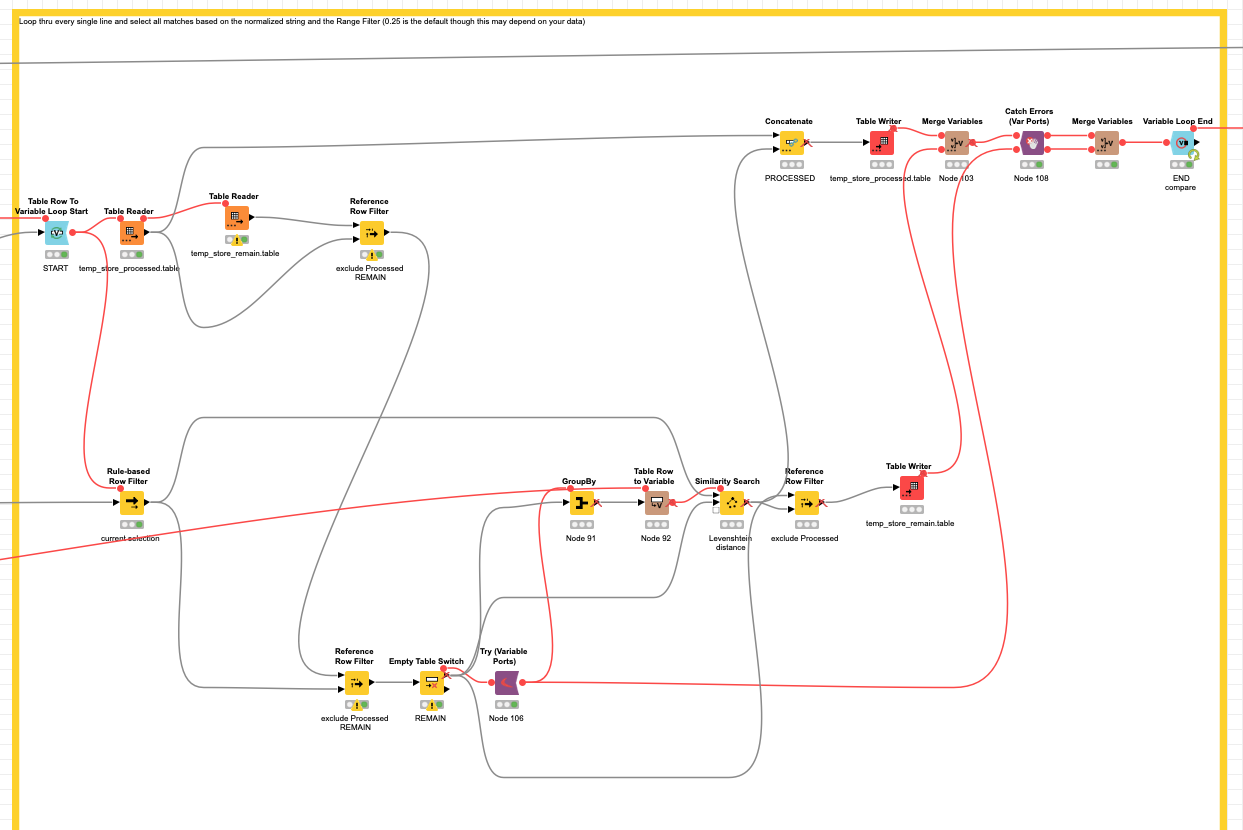
@DAmei I had another look and I built a slightly over engineered workflow to try and get what you want combining some of the approached already mentioned. In your case there might not be a ground truth against wich to match but rather a lot of possible combinations.
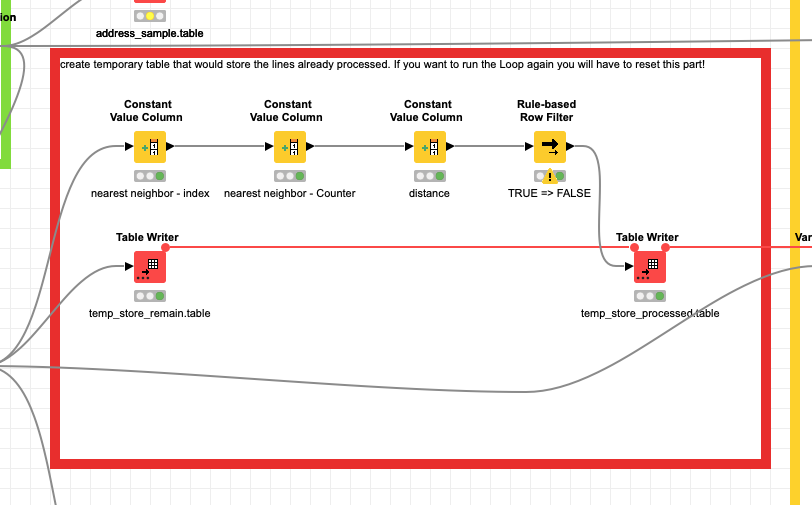
So configuration will be necessary and maybe exclude some obvious detaches in the first place. What the workflow does:
the address is turned into a standardised string. The composition of the string will influence the matching. So for example if you want to stress the importance of the street you might add that a few times. Or you might just want to use the start of the Company name - because this mostly is consistent
the you would generate a Counter as an artificial ID and start fron the top
you match all lines that would match the first row according to a Rang Filter (about the distance). If you think the matching is too wide you might want to restrict that settings further down from 25 (0.25)
the workflow will store the already matched lines at each step and if there is no match the line is a single entry
With that you should be able to build the groups of matching addresses. Each address can only be chosen once. You might have to tweak this approach
thanks for your comments and the further question. Actually, the concrete qualified duplicates are not available, which can be used to compare with. I just want to find out which could be duplicates or just the possible duplicates, if they have the same adresse and the similar firmname etc.
There are more than 150 thousand data set in the report and it is impossible that I finde out them manually. Also, wir try to aviod to use excel functions.
thank you very much for your attention and your comments . Is that possible that you share me your workflow above-mentioned, in which the loop nodes are used? I would really like to make a better understanding of this workflow and then try to customize one for my question.
Thanks a lot in advance .
thank you very much for your comments. I have inserted two gourpbys into my workflow. However, I can not get a decent result at the end of the workflow. I think your idea very meaningful and the question now might be… how can I tweak the parameters in the String Distances nodes for street number and house number? I have uploaded my freshest workflow and maybe you have a better idea?
so cool . Yes, I can download this workflow now. Thank you very much for sharing your workflow with me . I will firstly try to understand the whole concept and the relationship among the nodes you have used. Thank you @mlauber71
Thank you very much for sharing your workflow with me. The first part of your workflow helps me with selecting the absolut duplicates very well. I was soooo excited about the result. Thanks!
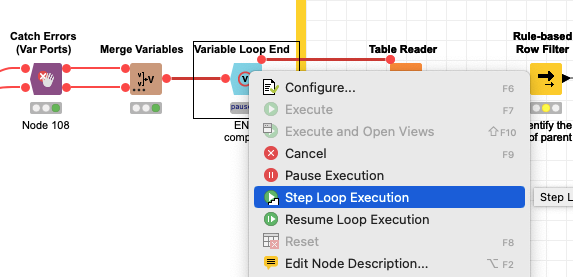
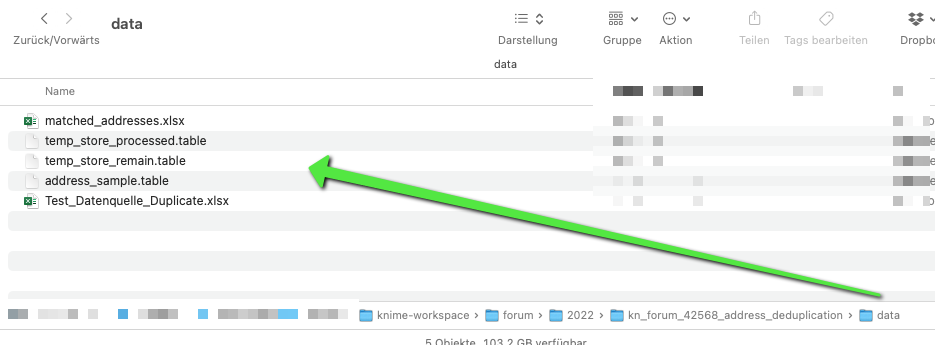
After that, I have met a tiny problem in your workflow. I am wondering if you could tell/show me how did you generate the Table Writer nodes“temp_store_remain.table” and “temp_store_processed.table”? Because I could not see what happened inside. Furthermore, the workflow from the Table Reader node“temp_store_remain.table” can not be executed any more. So I have no idea what could happen at the end of the workflow.
Thanks for your comments in advance and wish you have a nice day.
@DAmei galt you liked the initial approach. You should be able to reset the whole workflow and let it run again to see what is going on. The temp tables are getting created once before the start of the loop. They will have changed at the end so in order to start the loop anew you would have to recreate them.