Hi @mlauber71
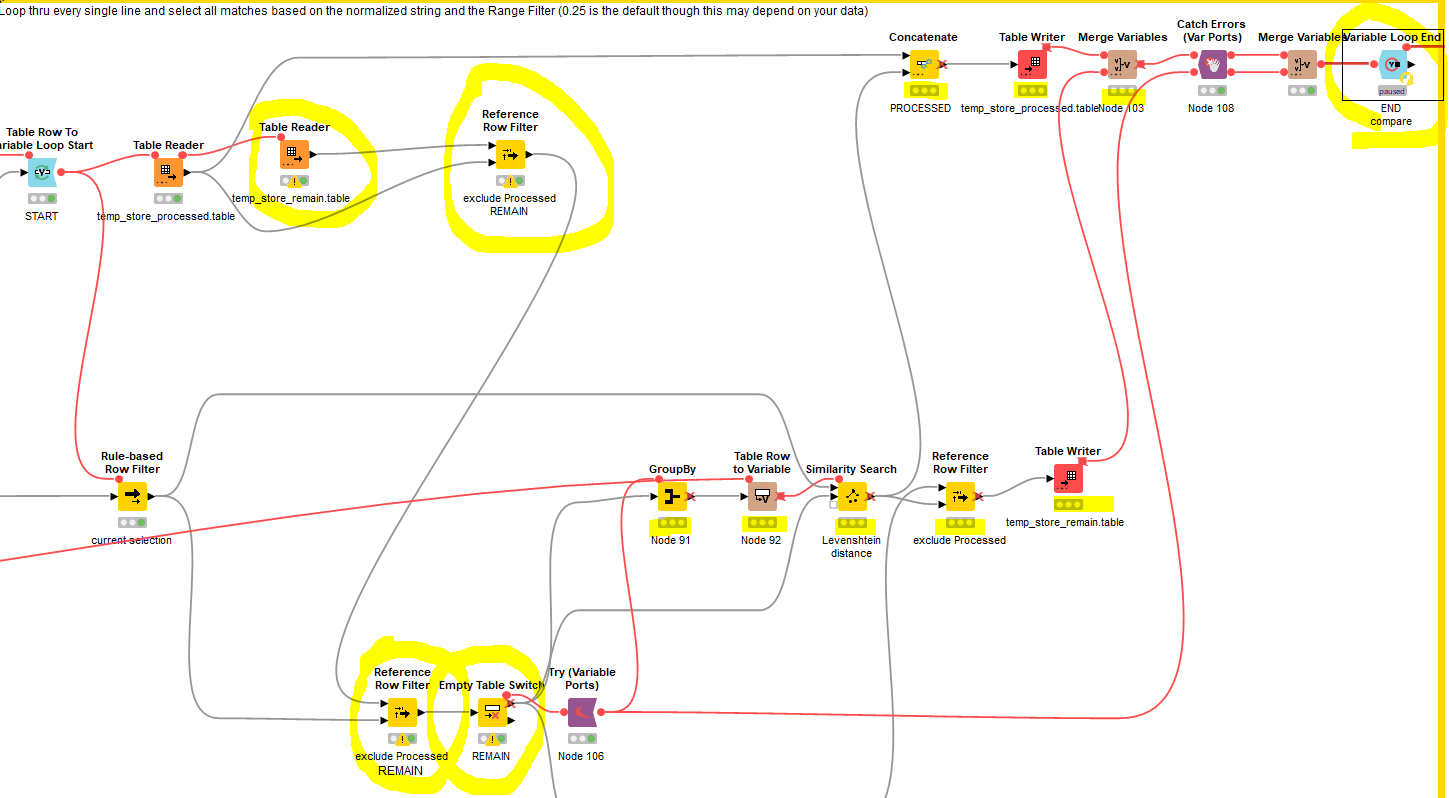
thank you for your answer. I have tried to start “step loop Execution” in order to execute the rest of workflow. But it does not work very well. Let me show you what happened in the following screenshot.
Hi @mlauber71
thank you for your answer. I have tried to start “step loop Execution” in order to execute the rest of workflow. But it does not work very well. Let me show you what happened in the following screenshot.
@DAmei I think you will have to reset the whole workflow and start again. The two temp files will have to be fresh at the beginning of the loop. Some steps in the loop will not have a match since they might be unique.
thank your @mlauber71. let me try it again ![]()
Hi @mlauber71,
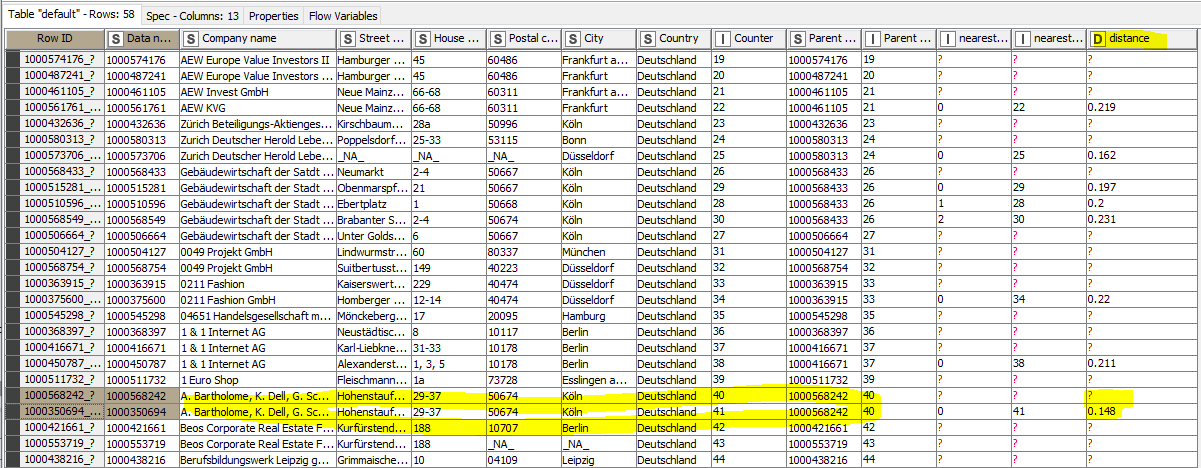
after I reset the workflow, I got the result like this (see the screenshot). I am wondering if you could tell me how I can use the data of Distance in the last column of the list to define the potential duplicate?
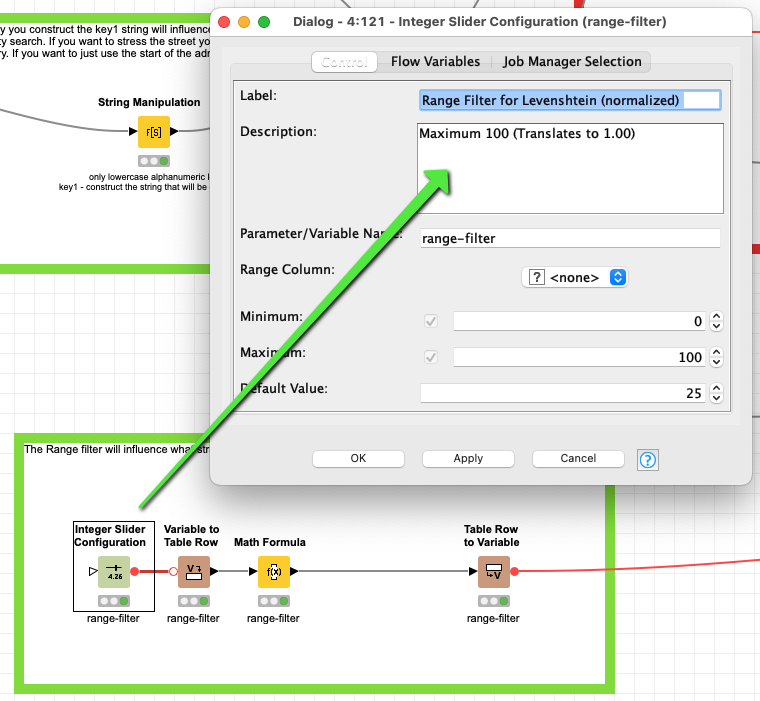
@DAmei you could use the slider to set a value between 0 and 100 - the lower the more strict the definition of a duplicate gets. In your example data there is a seeming identical value while the name is very long in the field. You will have to experiment with the settings.
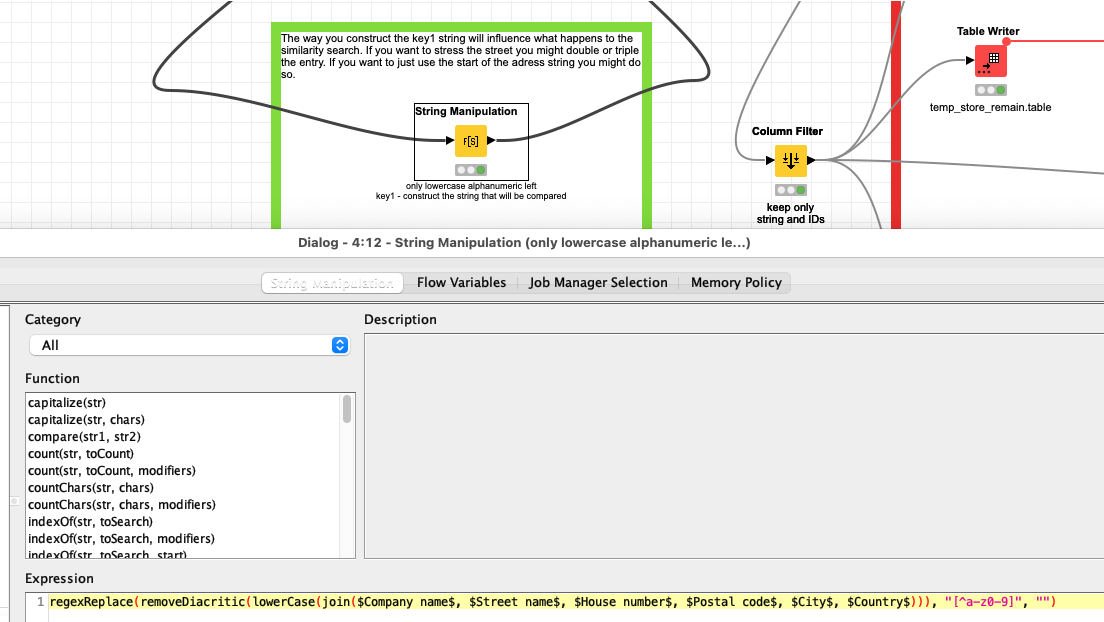
And also you might think about limiting the number of characters you would use to construct the company name. If you want to stress the importance of a component you could use that a few times, to give it more weight.
These would be examples to be shorten the names if you want to have them as duplicates.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.