I am importing Excel files from a folder that contains 2 subfolders, say <knime worspace>/data/folder 1 and <knime worspace>/data/folder 1. I use a Read Excel Sheet Names with the base folder <knime worspace>/data/ and the option to read subfolders followed by an Excel Reader in a loop.
Now, I want to modify selected columns (all but the first column) by appending to the column name a text string that depends on which subfolder is used.
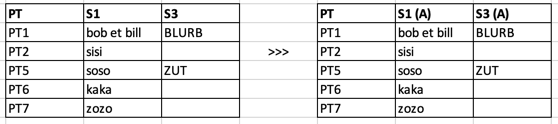
Columns from the subfolder folder 1 should be renamed Column Name to Column name (A)
Columns from the subfolder folder 2 should be renamed Column Name to Column name (B)
As an example an excel file from folder 1 should be transformed as follows
I should probably use an If Switch node or Case Switch (?).
Ideally I would the use a Column Rename (regex) node where the remaining is conditional on the path to the current Excel file.
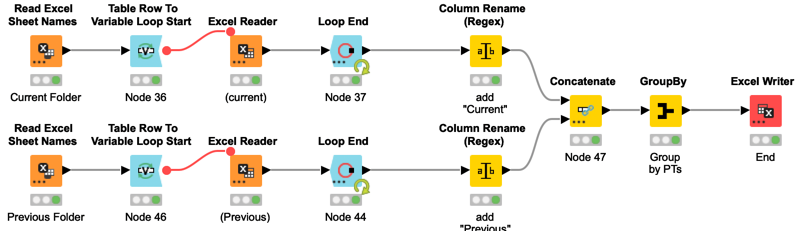
Right I am using one input loop per subfolder as follows:
See screenshot for how that could be generalised. Works for any number of directories.
You’d need a list of directories to loop over. Then comes your workflow pretty much unchanged. Two things are different:
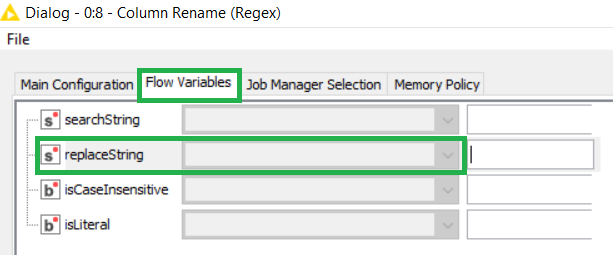
The Column Rename (RegEx) is controlled via a Flow Variable to use different replacements every iteration. For that you need to create a Flow Variable first. If you leave the default needle as it is, “$1_yourNewSuffix” should do the trick. You can set that up in the Flow Variables tab in the configuration window.
Instead of the Concatenate you’ll need a Loop End, set to allow changing table specs. If all RowIDs are identical, a Loop End (Column Append) might work as well. Advantage is that the GroupBy is then not needed, but you’d have to test that.
Working it out left to right I am stuck at the String Manipulation (Variable) node, probably because I know nothing of Flow Variables. Could you please post the configuration windows of this node (and probably of the Column Rename (RegEx) as well).
I imagine it has to do with a Path variable but I do not see it in these nodes after running upstream nodes.
Sorry you got stuck, I didn’t know that (probably) no node can access the Path variables directly
I properly built the thing, but used the Java Edit Variable instead of the String Manipulation (Variable) node because 23ish nested expressions don’t fit into anyones brain.
The Java Edit Variable node produces a Flow Variable that we will use to “remote control” the Column Rename (RegEx) node. Since that value will change with every loop iteration, we can’t just configure it manually. You know that already, or you would not have been able to set up the Excel Readers to work properly. Some settings have a Flow Variable button in the normal config, but every setting can also be overwritten with a Flow Variable in the Flow Variables tab in the node configuration window (see second screenshot in my first post).
The RegEx needle matches any string (column name) that doesn’t start with a “P”. Since the part within the brackets matches the entire string, all of it will be put into variable1 ($1) in the replacement operation. The replacement is just the original string plus some other characters that we defined in the java snippet.
Columns that don’t match will not be changed.
needle: "([^P].+)"
replacement: "$1 (A)"
or: "$1 (B)"
etc.