I know you can assign the first row of a file to be the column header row when reading in a file. But what if you have a node output in your workflow where you want to assign the first row of the output as athe column headers. Short of renaming the columns manually and filtering out the row with the column headers I'm not sure of a good way to do this. I guess I could oputput a csv file with the headers and then read it back in with the first row as the header but that seems a little roundabout just to assign the column headers. Any suggestions?
2 Likes
What about: Transpose >> (Filter) >> Row ID >> Transpose, should work?
Thanks Gabriel. It's not the most elegant way to do it but it works. I should be able to put this in a metanode so I can re-use. Would be nice though to have a node that would allow you to assign the first row as the header row (like you can for the csv file reader.
This certainly works, but it is a slow process. It would be nice to have a Promote to Headers node.
4 Likes
Was hoping to find a solution to this problem here. Would be great, if a node as proposed above would become reality. For the time being I’ve resorted to using a metanode with the following contents:
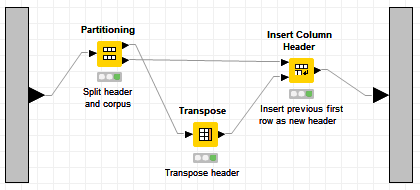
Obviously the Partioning node is configured as “Absolute: 1” and “Take from top”, and the “Insert Column Header” as "Lookup Column: " and “Value Column: Row0”. Maybe someone else will find this useful.
17 Likes
Fantastic - this is beautiful solution @G47_2 .
I spent hours reading various posts and trying to find the right solution online and this one came unexpectedly beating all the previous attempts.
Great job. Thanks
1 Like