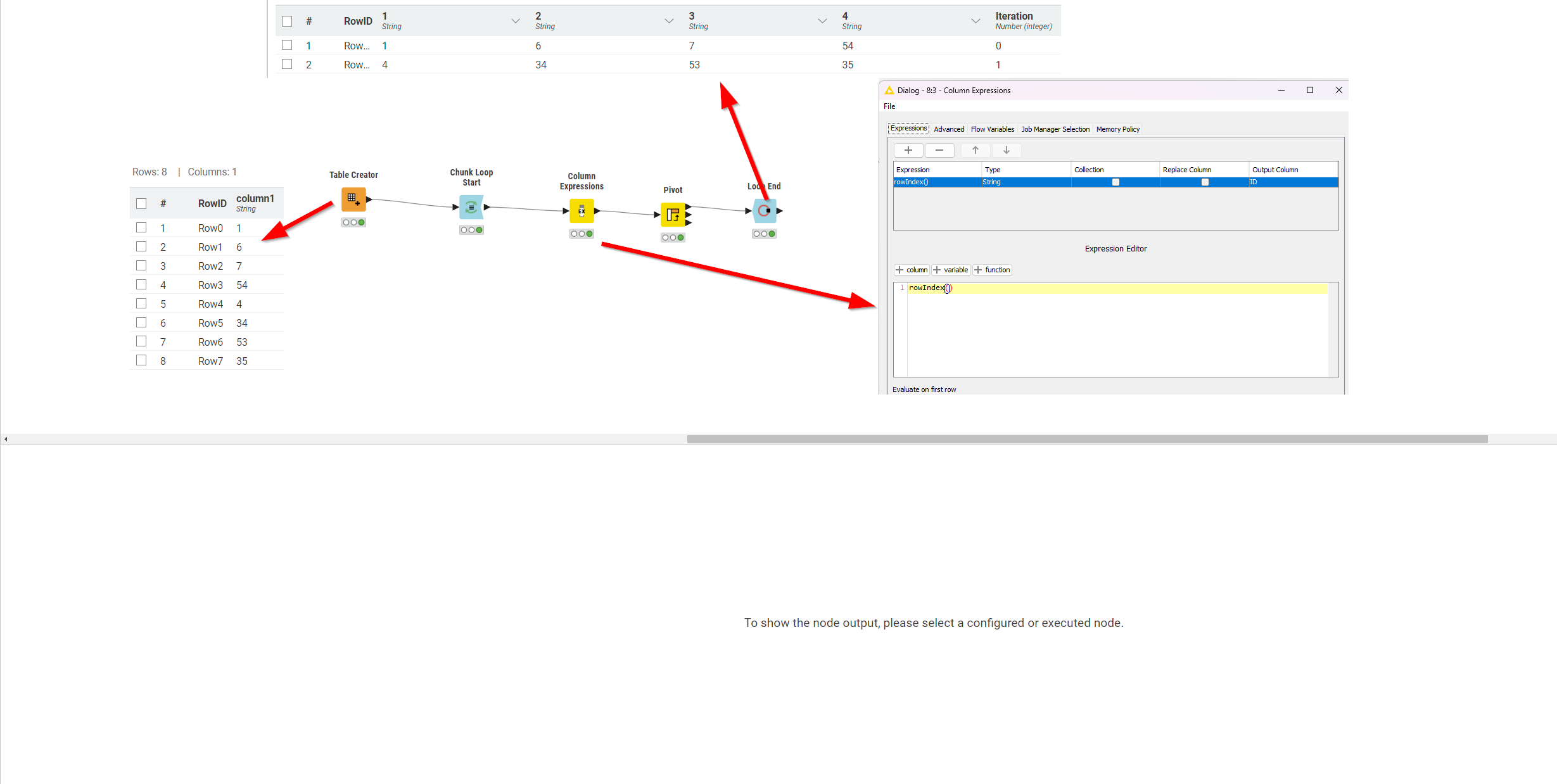
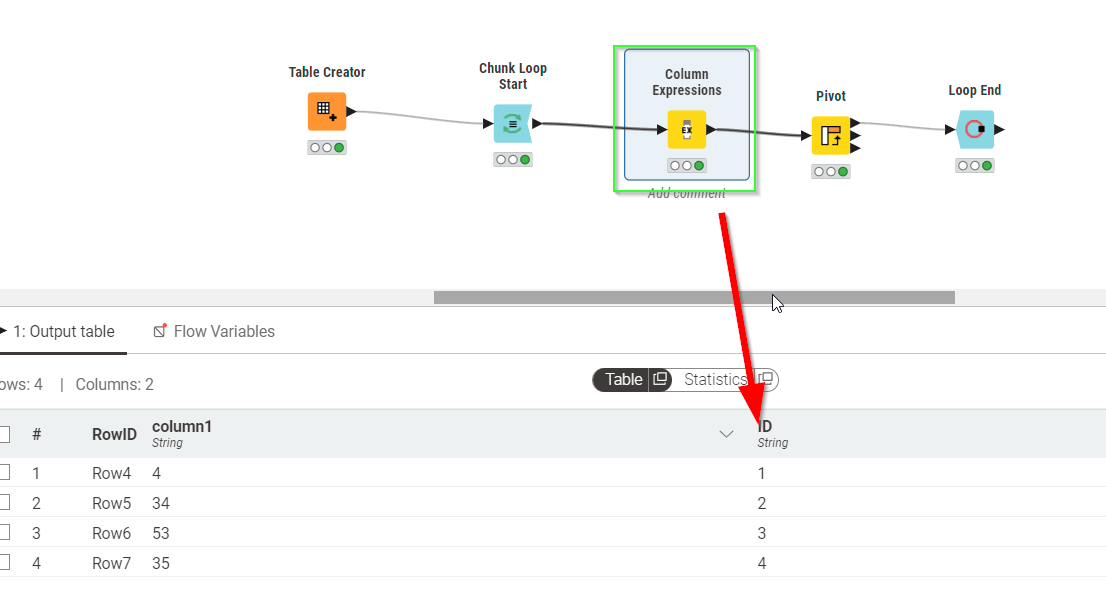
In order to collect results at the end of the loop you need to make sure that the new column headings are the same. The easiest way to achieve this is to create at every iteration a new unique ID that you then pivot by…
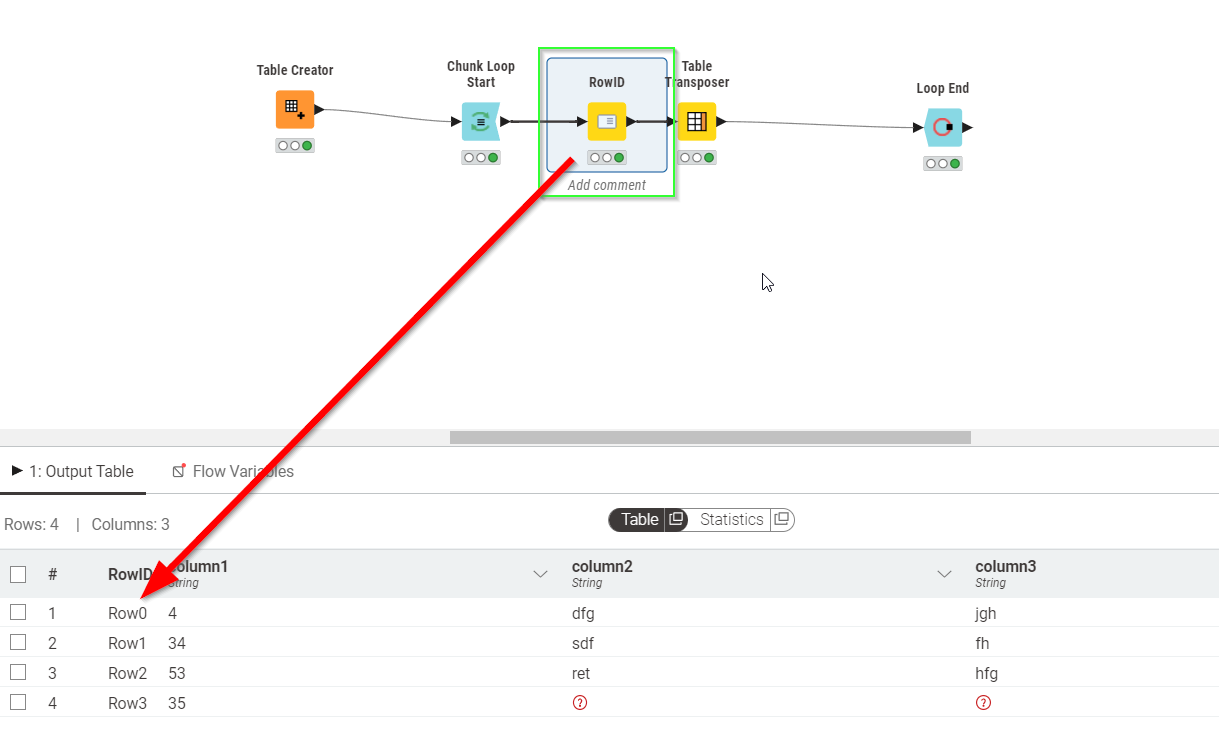
An alternative that can work if you have multiple columns in your input data set is to reset the row ids, then to transpose…
Thank you for the example flow, which I have loaded and runs with the desired output. I understand the concept of creating the unique ID every ‘chunk’ , but can’t see where that is actually happening! Can you enlighten me please?
Well in the first example (with pivot node) it is happening in the column expressions node (see config dialogue in screenshot in my earlier post as well):
In the second example the Row IDs are reset - once you “flip a table” on its side using Table Transposer, the RowIDs are used as column headers. To ensure that the column headers of all 4 columns are always the same, this node resets them. This makes sure that e.g. in the second iteration, when Row4-Row7 of your original dataset are processed, these are changed to Row0-Row3 again:
You can use Pivoting node for this only before that you need to create sequence column (which will be actually Pivoting column) with 1,2,3,4 repeating itself (or generalized 1,2,3,…,n where n is number of wanted/needed columns).
For creating sequence column see here:
In Pivoting node you don’t need grouping column but rather List aggregation for which you then use Ungroup node to get desired format. However if you also create sequence grouping column you won’t need Ungroup node as that will be your grouping column.
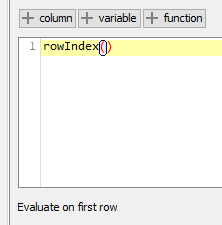
Thanks. I think the ‘evaluate on first row’ is important to mention as it means the same id is output for each row in the chunk and give the pivot node the column to group by?