Noted @Kwinten!
Like others have mentioned, an uploaded dataset would do a lot in cases like this to avoid other having to recreate it from scratch.
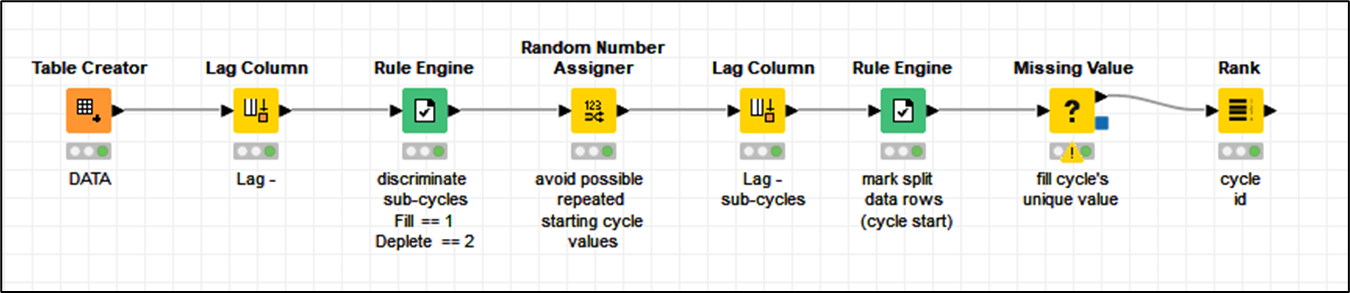
You can approach this in various with different nodes out there. Also depends a bit on how familiar you are with coding. Below is a way to solve it through Column Expressions.
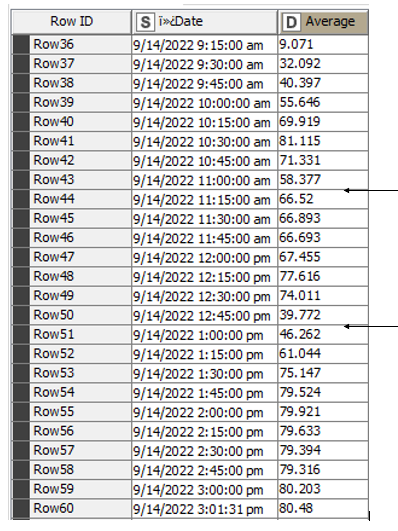
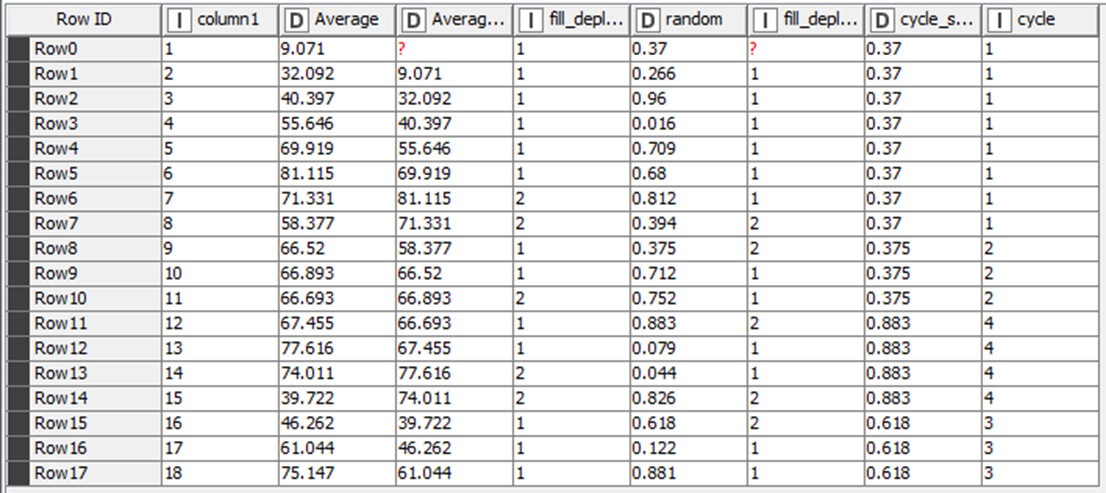
For the sake of saving time, I consider your timestamps as a sequence of ID’s.
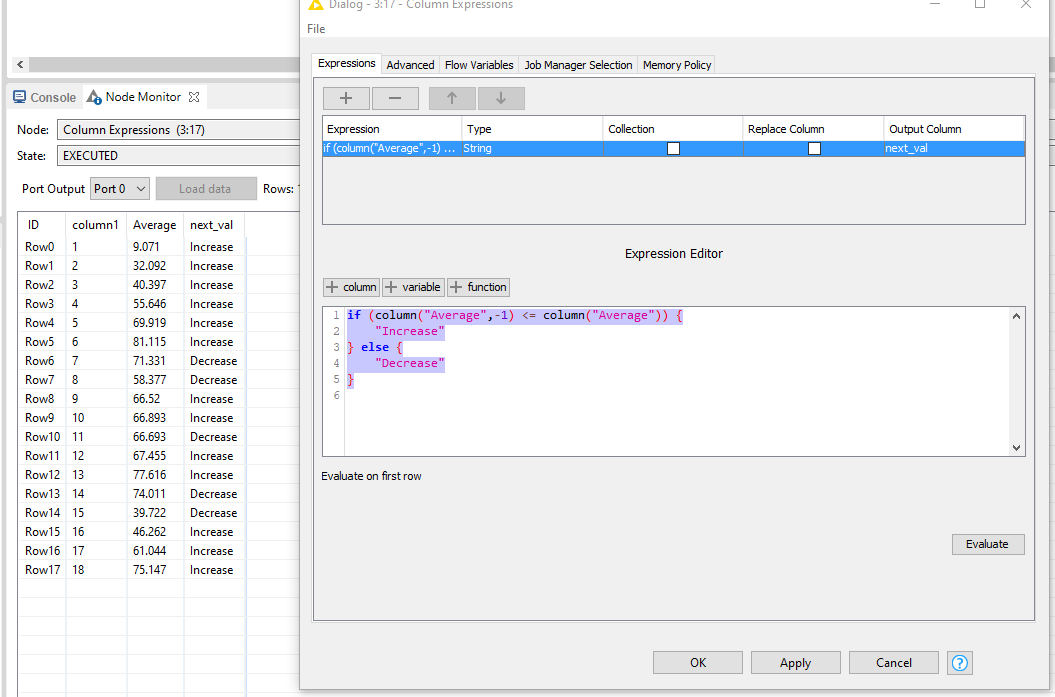
I first want to determine if the current value has increased or decreased compared to the previous row, to later establish the groups based on this. With the updated syntax of the Column Expression node in 4.6, you can achieve this by using:
if (column("Average",-1) <= column("Average")) {
"Increase"
} else {
"Decrease"
}
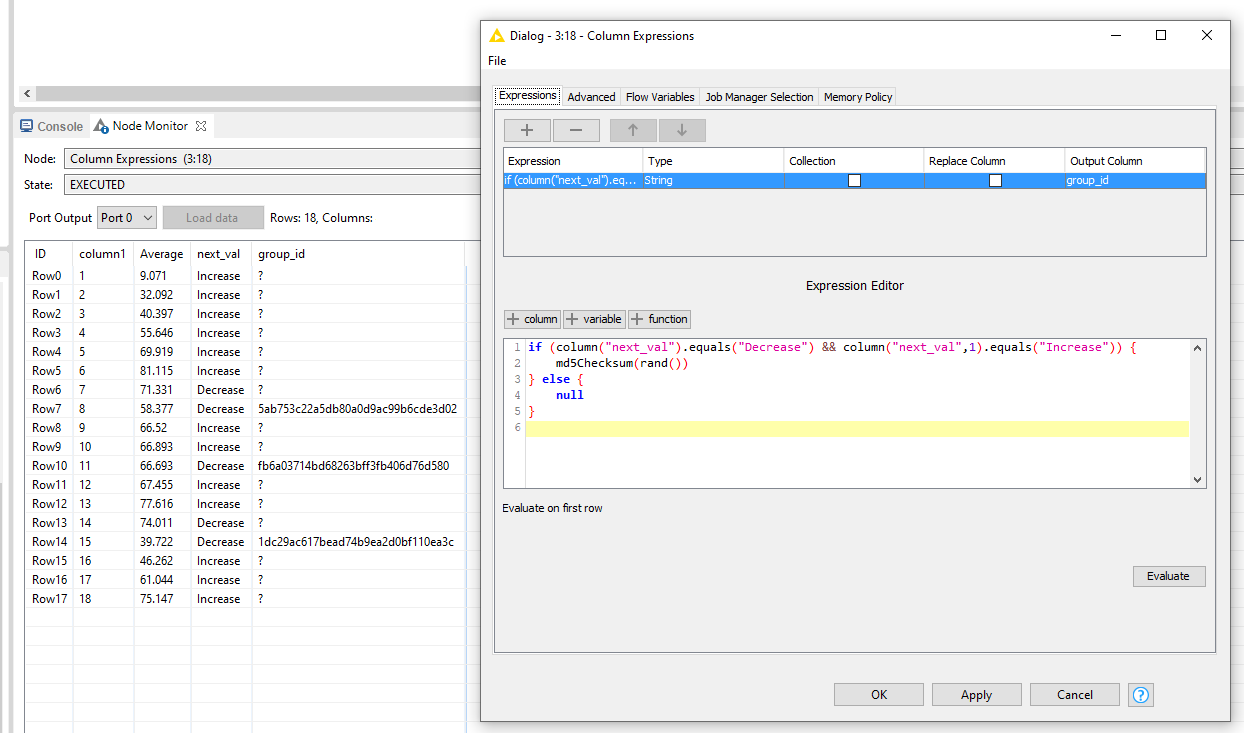
Since we established that the cut-off should be after the last “decrease”, I determine the end of each group by finding all rows where the next_val = decrease and the new row = increase.
if (column("next_val").equals("Decrease") && column("next_val",1).equals("Increase")) {
md5Checksum(rand())
} else {
null
}
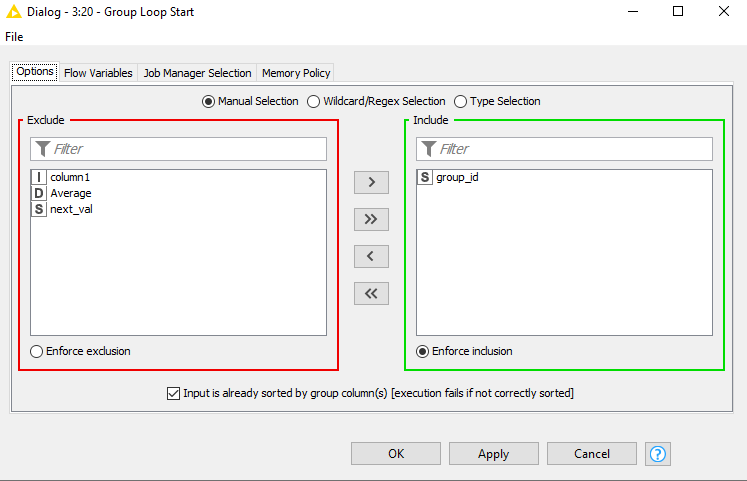
To later identify the groups easier, I opt to use a hash as identifier based on a random() value. The output of group_id now designates all “endpoints of each group”. Noticeably, @badger101 is right that there is another group hidden in there.
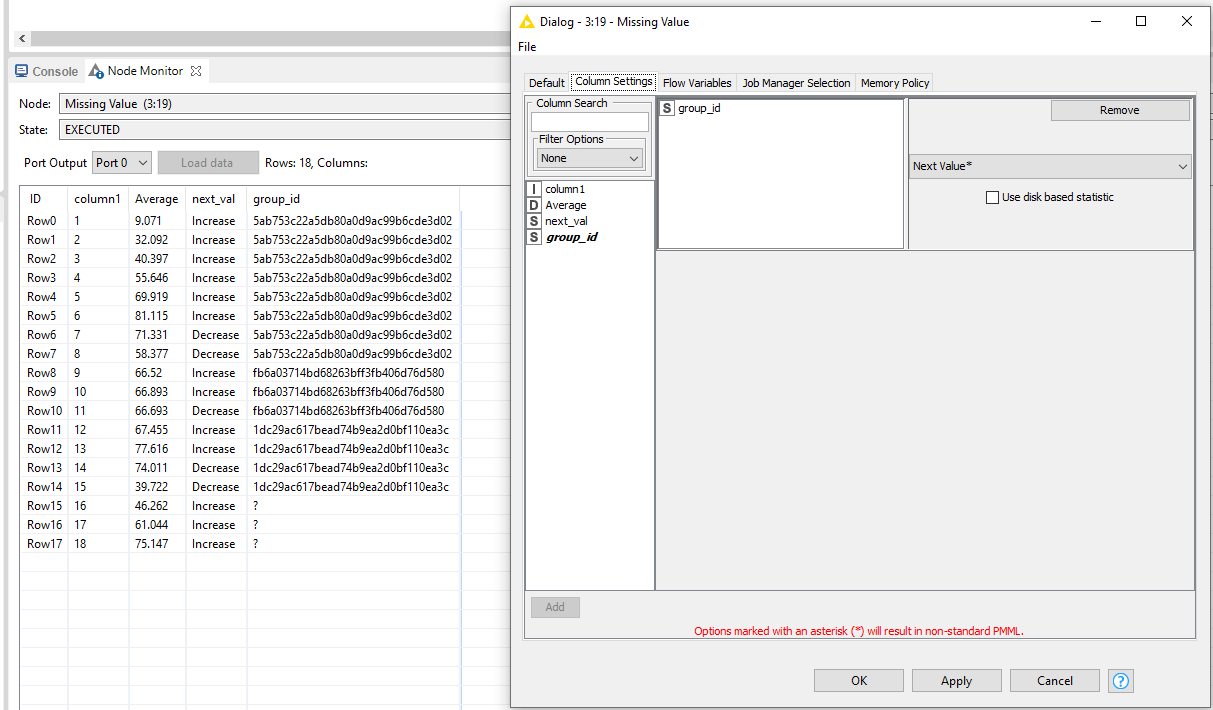
To complete the group_id’s, you can use the Missing Value node with the Next Value as replacement
If you then start a Group Loop based on this identifier, you can do whatever your use case desires (like writing it to a separate file, etc.).
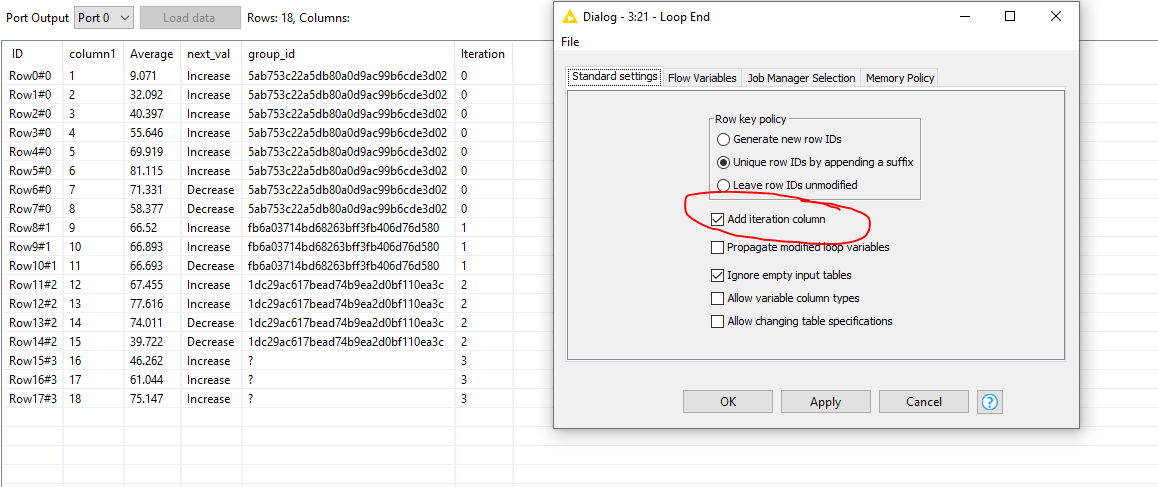
Add a general Loop End and enable the Add Iteration Column to visually see which records got processed within each group.
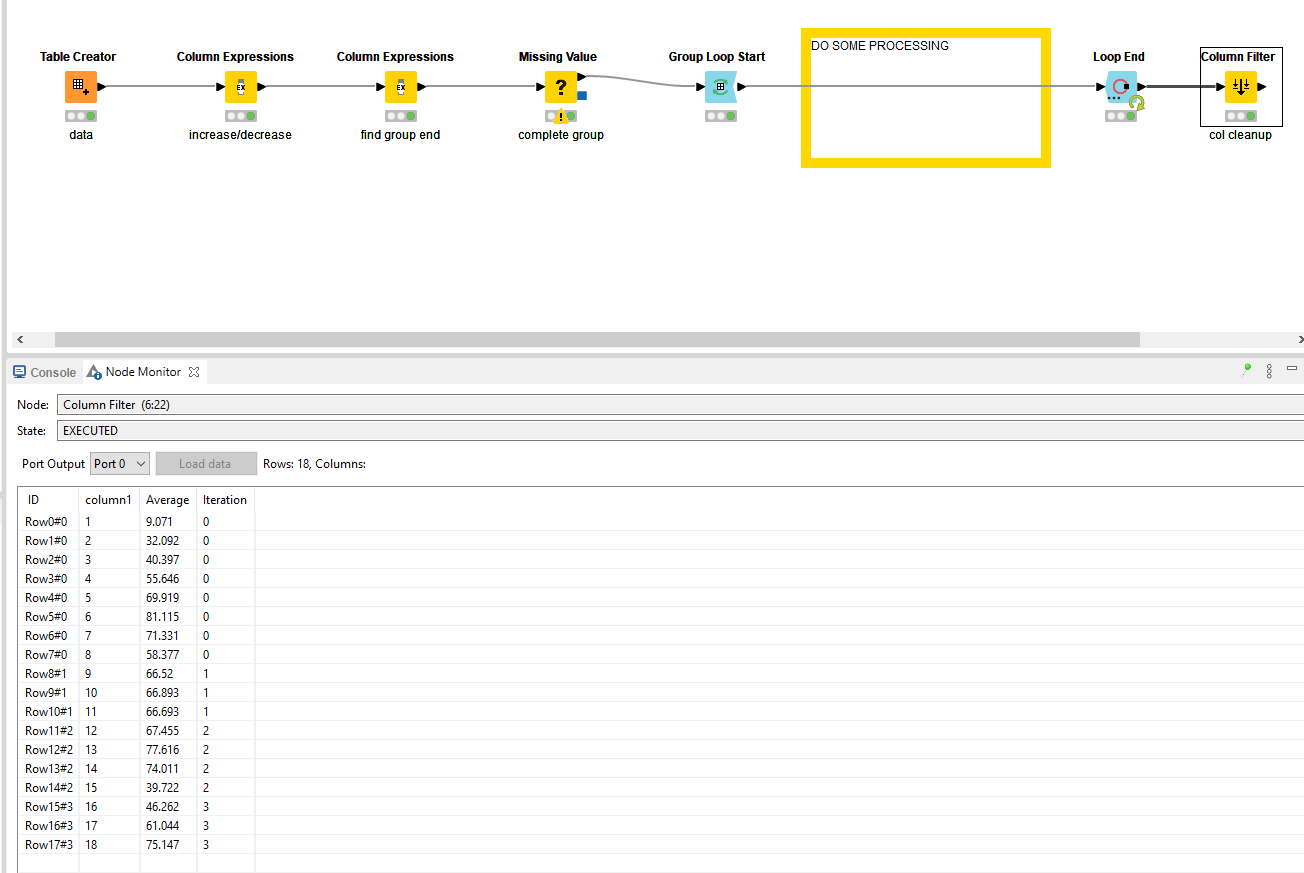
With a small clean-up, a test setup would look something like this:
See WF:
How do I split a column when a value drops.knwf (42.5 KB)
Hope this provides some inspriation!