The dataset cited seems to be from this page. It might be based on another set but I was not able to track it down further.
Question is what you mean by 80%. Accuracy out of the box for this task goes to 85% without much data preparation. Some details might depend on the exact split of test and training. On Kaggle some more elaborate preparations reached 90% tough I have not checked them in detail.
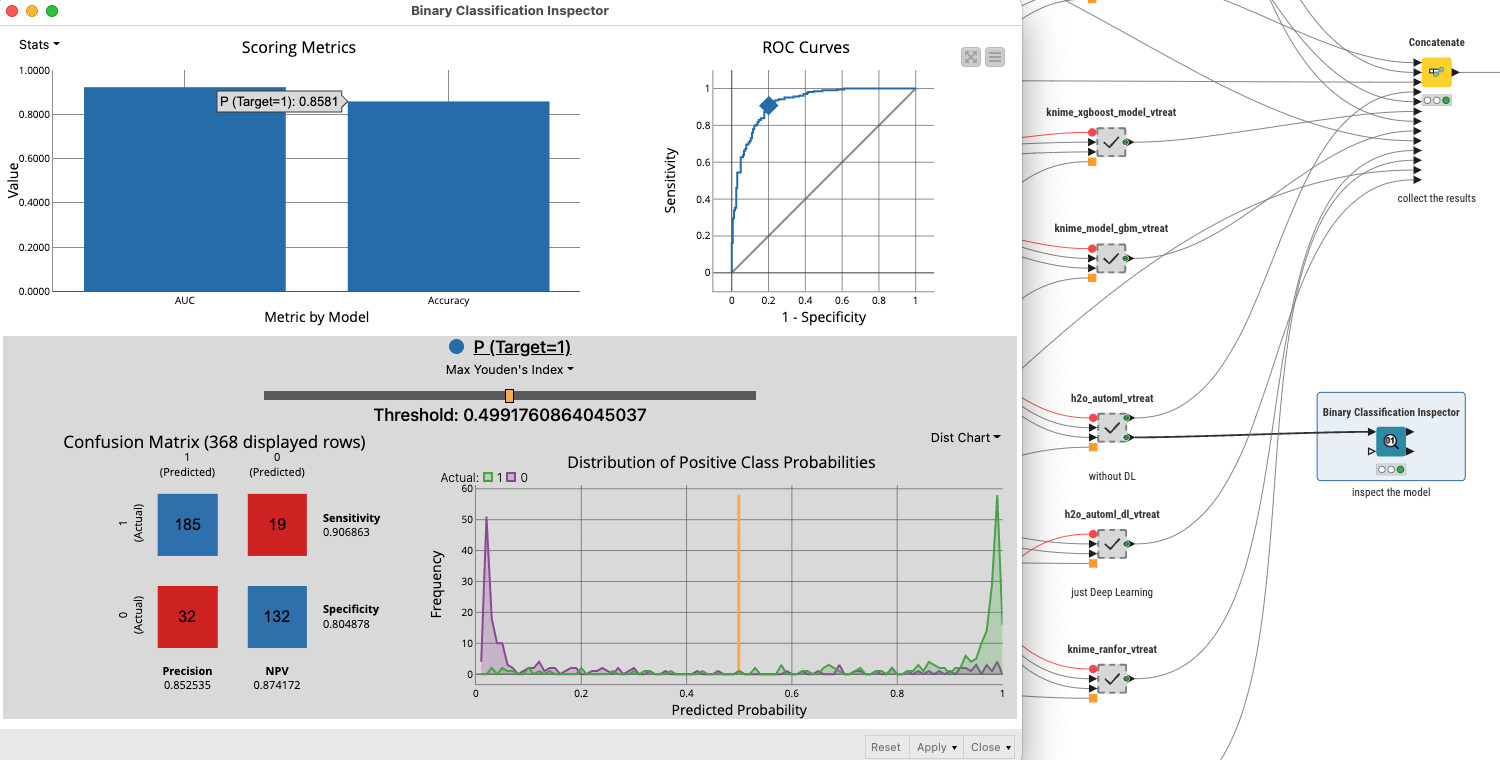
I took the liberty of dusting off my collection of binary classification algorithms for KNIME 5.2 and run it with this dataset. AutoML (that is GBM mostly) and XGBoost seem to be quite robust.

You will have to decide for yourself if the results are good to be used in your business case. In this case: it is better to scare some people that might later turn out to not have problems or miss some who might later develop a disease.
Also there might be a case where the modle detected all the right signs of a health problem (or a defect in predictive maintenance) but it is not fully present yet so technically this might be a wrong classification but for all practical reasons it is not.
Some models do contain some variable importance metrics. There are also two Jupyter notebooks in the /data/ folder to run a XGBoost model and to inspect the H2O.ai/GBM model in greater details (along these lines).
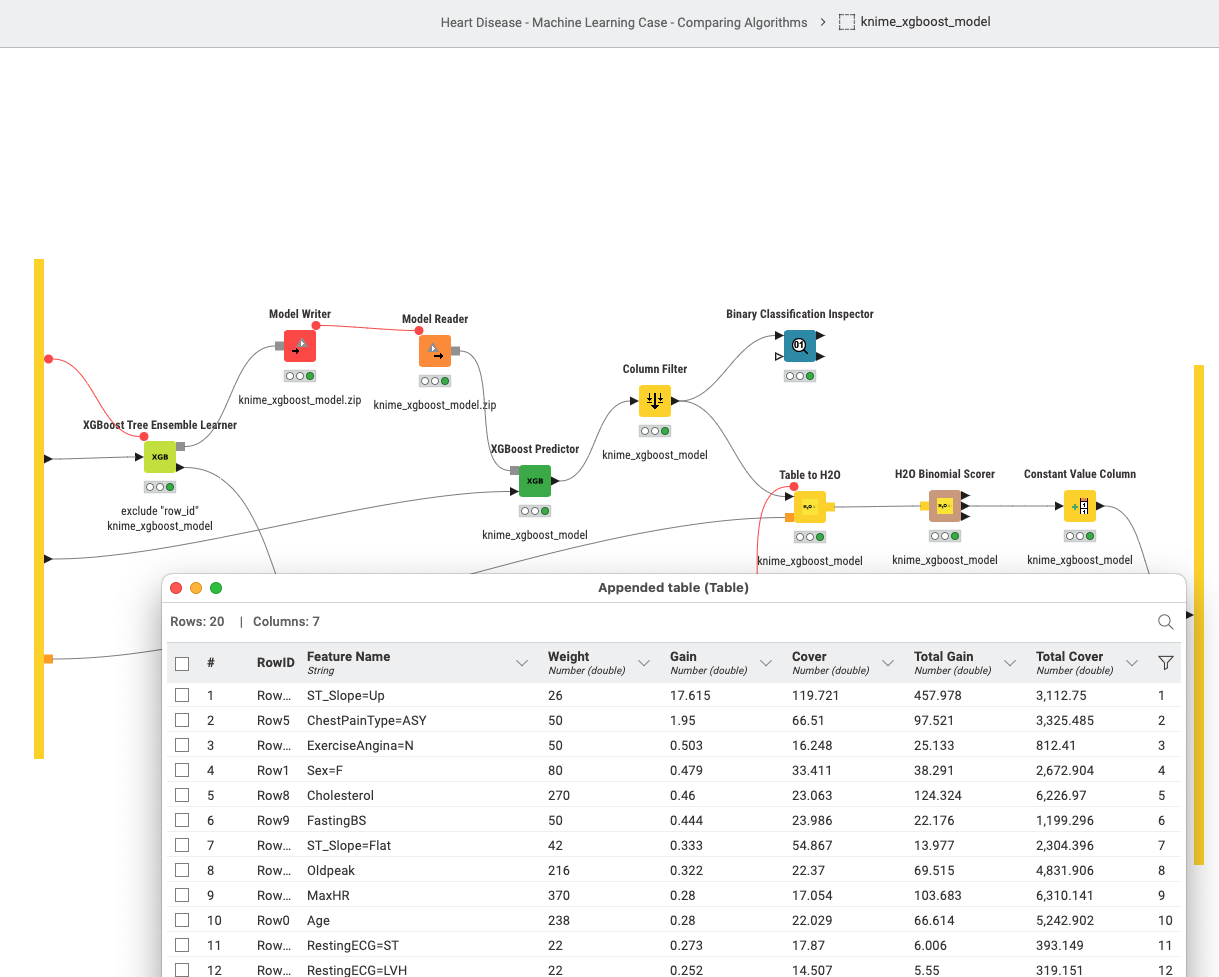
If you want you can explore these models. I might write some more elaborate blog about what is happening here; but one can just feed new data with a “Target” variable as string (0/1) and a “row_id” and split that into test and training, make sure the Python environment is running and just run this. If you are patient you can increase the time the automl process is running.