I need to know what test or node I must use to ensure
that my data are balanced (I don’t mean it has missing value or needs normalizing) I mean it’s a real dataset that does not have random value or no sense in it when I use ML algorithms on it. The result of machine learning will be good
to make decisions on it, I used to use the heart dataset (to apply like videos I watch) but I figured out it was a bad dataset because all ML algorithms gave me bad results. Still, I can’t test all algorithms every time.
I would appreciate any information from your education or experience that can help me.
thanks all
I don’t think there’s a simple answer to assessing “data quality.” Its important to have sufficient domain knowledge as a beginning. Read this for some help on dealing with unbalanced data. A lot of data sets, e.g. for fraud are naturally unbalanced.
Typically such datasets are reasonably well prepared and are meant to be used in machine learning cases. Sometimes they tend to be ‘too good’ so as to spoil aspiring data scientists and give them a false impression of the real world …
So if the results are not to your satisfaction maybe the method or preparation did not work.
As @rfeigel already said: Domain knowledge most often is necessary to understand what is going on and if you do not use a prepared dataset like from a Kaggle competition you will have to invest some time to bring the data into such a shape that it will truthfully represent your task and the data has any chance at all to contain what you are looking for.
To check a dataset you could start by checking the correlations with the target variable. If there are only weak correlations it is very unlikely that you will be able to get a good model.
Another thing to check is if the data has some variations, so not all values in a column are constant or nearly constant or the colum features are highly imbalanced.
If your target variable is imbalanced that does not need to stop you from building a model; you could for example use a different metric like AUCPR to help you.
Further hints about models you could check here:
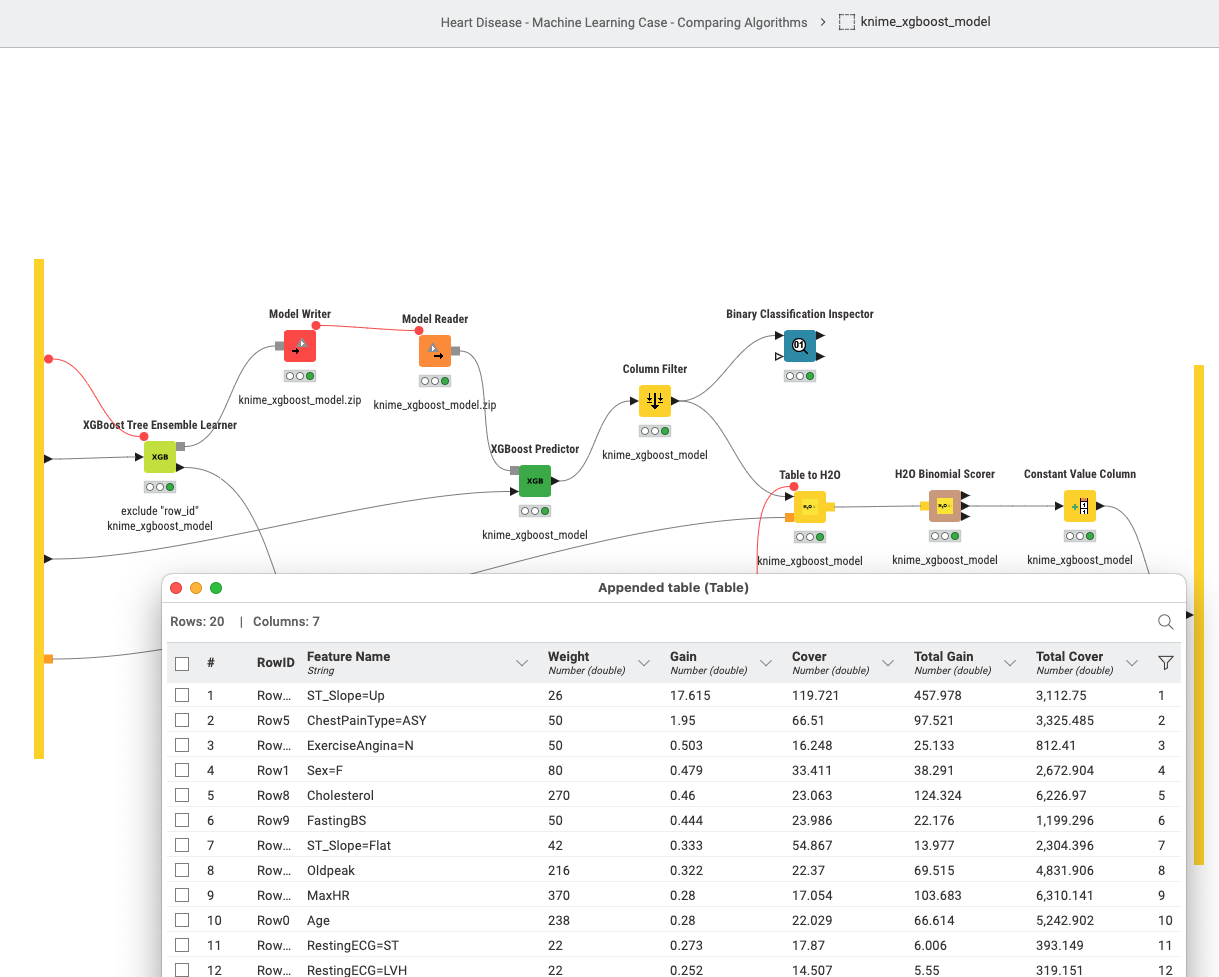
Another pre-check I like is to just run some (H2O.ai) models which will give us variable importance. You can check with domain knowledge if the ‘leading’ variables would make any sense at all. Or if they might be too good to be true (most likely constituting a leak, that is information about the target that a real model will not be allowed to have).
Welcome to the (real) world of data science
Maybe another remark: if you encounter problems you could maybe share the workflows and approaches you have used so the KNIME community might have a look and give further advise what could be done; like when you said the heart disease dataset would not give you good results.
First of all, thank you for all the valuable information you have provided.
Regarding your question, yes, it is the same data as in the previous question. I have noticed that no matter what the machine learning algorithm is, the results do not reach 80% at best, even with adjusting the parameters does not improve the results.
**I mentioned at the beginning of a series on this link (https://www.youtube.com/playlist?list=PLiOBAYiI6xJjHSOtryFfr0FzZYPqTBOZi) that when applying linear regression, it gave a result opposite to what is known for cholesterol. Perhaps this is repeated in more than one column, as there is no strong relationship between the data.
The dataset cited seems to be from this page. It might be based on another set but I was not able to track it down further.
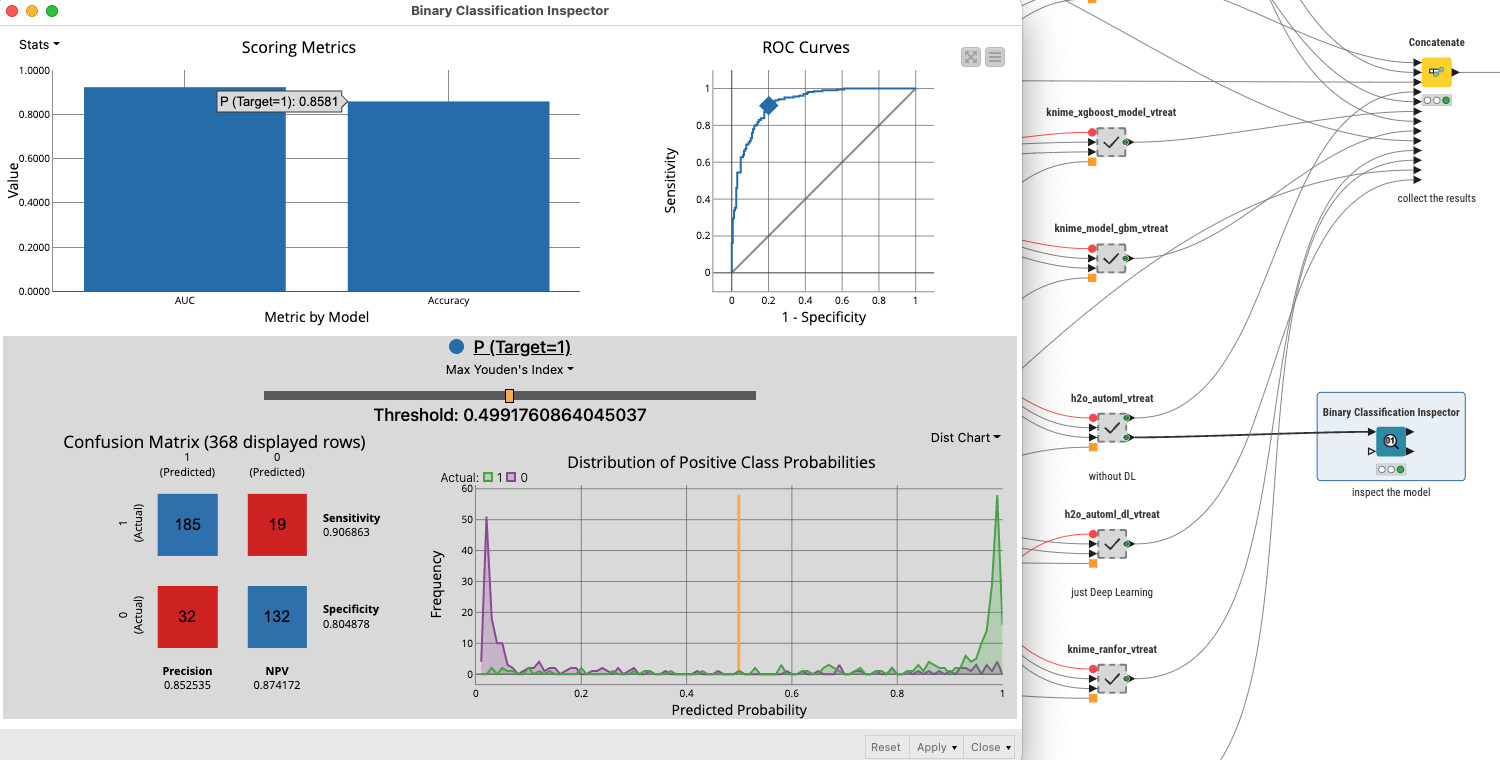
Question is what you mean by 80%. Accuracy out of the box for this task goes to 85% without much data preparation. Some details might depend on the exact split of test and training. On Kaggle some more elaborate preparations reached 90% tough I have not checked them in detail.
You will have to decide for yourself if the results are good to be used in your business case. In this case: it is better to scare some people that might later turn out to not have problems or miss some who might later develop a disease.
Also there might be a case where the modle detected all the right signs of a health problem (or a defect in predictive maintenance) but it is not fully present yet so technically this might be a wrong classification but for all practical reasons it is not.
Some models do contain some variable importance metrics. There are also two Jupyter notebooks in the /data/ folder to run a XGBoost model and to inspect the H2O.ai/GBM model in greater details (along these lines).
If you want you can explore these models. I might write some more elaborate blog about what is happening here; but one can just feed new data with a “Target” variable as string (0/1) and a “row_id” and split that into test and training, make sure the Python environment is running and just run this. If you are patient you can increase the time the automl process is running.
I did a very simple XGBoost model with default settings using your data. I realize you’re after an apriori method(s) to assess data quality. Sometimes its better to try reasonable models to help make the assessment. AutoML is very useful. @mlauber71 has given you a lot of good advice.
Accuracy - 86.9%
Cohen’s kappa - .736
@rfeigel … or just use XGBoost and be done on Mac and Linux Python H2O AutoML will include that in the models tested.
One can also try and combine that with some hyper parameter optimization:
In a lot of cases it will not be a question of 0.84 vs 0.85 which might shift some anyway but to think about what to do and where to make the cut for a prescribed action and also integrate some cost estimations.